






The Processes
When the Flink system is started, it bring up the JobManager and one or more TaskManagers. The JobManager is the coordinator of the Flink system, while the TaskManagers are the workers that execute parts of the parallel programs. When starting the system in local mode, a single JobManager and TaskManager are brought up within the same JVM.
When a program is submitted, a client is created that performs the pre-processing and turns the program into the parallel data flow form that is executed by the JobManager and TaskManagers. The figure below illustrates the different actors in the system and their interactions.

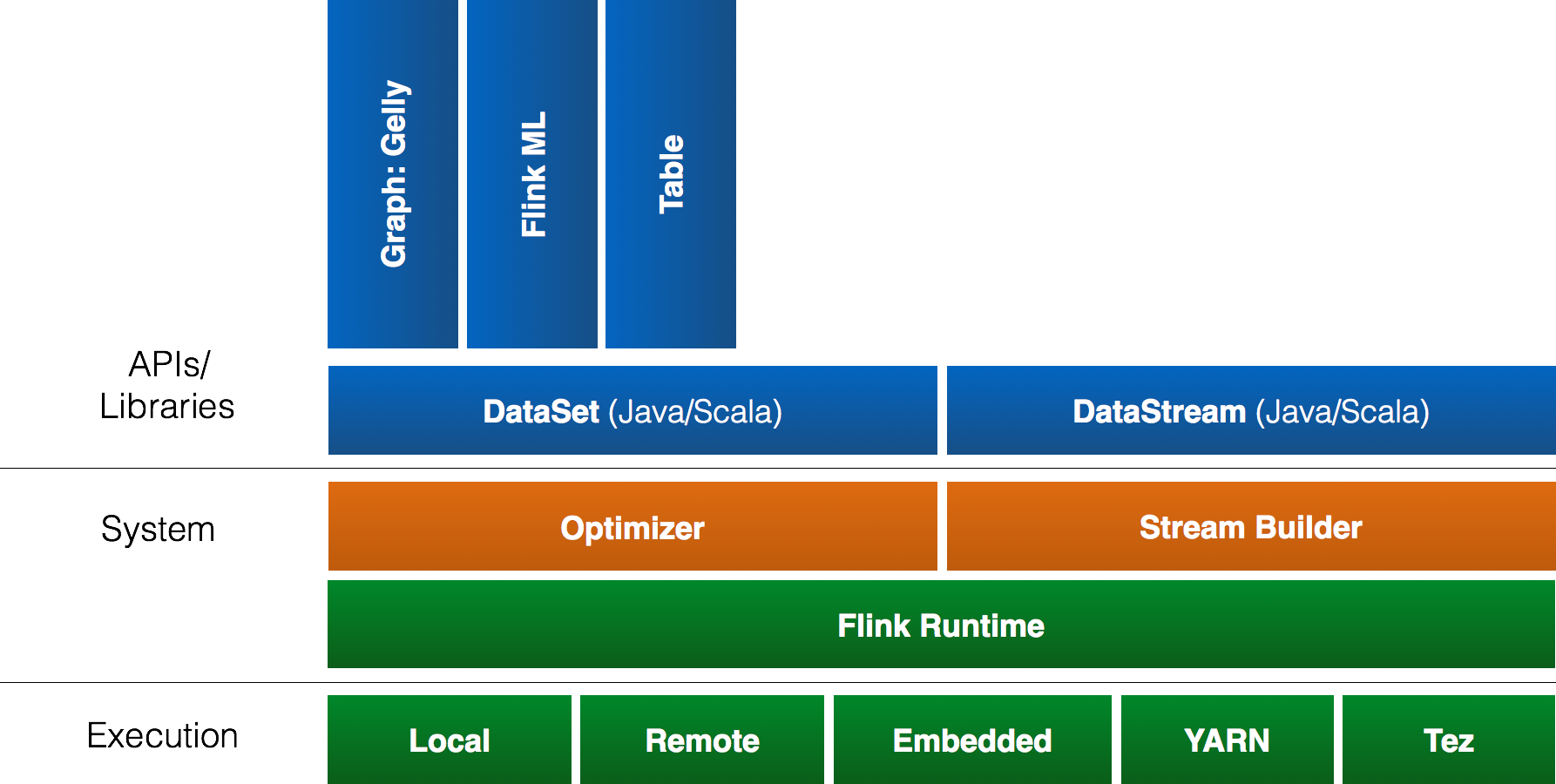
Component Stack
As a software stack, Flink is a layered system. The different layers of the stack build on top of each other and raise the abstraction level of the program representations they accept:
-
The runtime layer receives a program in the form of a JobGraph. A JobGraph is a generic parallel data flow with arbitrary tasks that consume and produce data streams.
-
Both the DataStream API and the DataSet API generate JobGraphs through separate compilation processes. The DataSet API uses an optimizer to determine the optimal plan for the program, while the DataStream API uses a stream builder.
-
The JobGraph is executed according to a variety of deployment options available in Flink (e.g., local, remote, YARN, etc)
-
Libraries and APIs that are bundled with Flink generate DataSet or DataStream API programs. These are Table for queries on logical tables, FlinkML for Machine Learning, and Gelly for graph processing.
You can click on the components in the figure to learn more.
Projects and Dependencies
The Flink system code is divided into multiple sub-projects. The goal is to reduce the number of dependencies that a project implementing a Flink progam needs, as well as to faciltate easier testing of smaller sub-modules.
The individual projects and their dependencies are shown in the figure below.

In addition to the projects listed in the figure above, Flink currently contains the following sub-projects:
-
flink-dist: The distribution project. It defines how to assemble the compiled code, scripts, and other resources into the final folder structure that is ready to use. -
flink-staging: A series of projects that are in an early version. Currently contains among other things projects for YARN support, JDBC data sources and sinks, hadoop compatibility, graph specific operators, and HBase connectors. -
flink-quickstart: Scripts, maven archetypes, and example programs for the quickstarts and tutorials. -
flink-contrib: Useful tools contributed by users. The code is maintained mainly by external contributors. The requirements for code being accepted intoflink-contribare lower compared to the rest of the code. -














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









