







分布式文件系统 Distributed File System
- 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
- 是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
- 通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 容错。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
- 分布式文件管理系统很多,hdfs只是其中一种。适用于一次写入多次查询的情况,不支持并发写情况,小文件不合适。
HDFS-Shell
调用文件系统(FS)Shell命令应使用 bin/hadoop fs 的形式。
HDFS fs命令
- help [cmd] //显示命令的帮助信息
- ls(r) //显示当前目录下所有文件
- du(s) //显示目录中所有文件大小
- count[-q] //显示目录中文件数量
- mv //移动多个文件到目标目录
- cp //复制多个文件到目标目录
- rm(r) //删除文件(夹)
- put //本地文件复制到hdfs
- copyFromLocal //同put
- moveFromLocal //从本地文件移动到hdfs
- get [-ignoreCrc] //复制文件到本地,可以忽略crc校验
- getmerge //将源目录中的所有文件排序合并到一个文件中
- cat //在终端显示文件内容
- text //在终端显示文件内容
- copyToLocal [-ignoreCrc] //复制到本地
- moveToLocal
- mkdir //创建文件夹
- touchz //创建一个空文件
Hadoop管理员常用命令
hadoop job –list #列出正在运行的Job
hadoop job –kill #kill job
hadoop fsck / #检查HDFS块状态,是否损坏
hadoop fsck / -delete #检查HDFS块状态,删除损坏块
hadoop dfsadmin –report #检查HDFS状态,包括DN信息
hadoop dfsadmin –safemode enter | leave
HDFS架构
HDFS架构由三部分组成,NameNode、DataNode、SecondaryNameNode
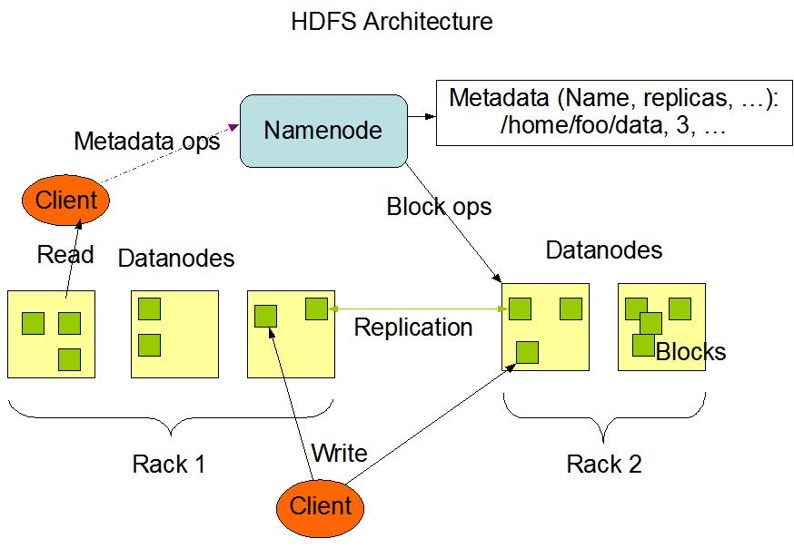
NameNode
- 是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
- 文件目录(hdfs-site.xml的dfs.name.dir属性
)
- fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
- edits:操作日志文件。
- fstime:保存最近一次checkpoint的时间
- 以上这些文件是保存在linux的文件系统中。
NameNode的工作特点
- Namenode始终在内存中保存metedata,用于处理“读请求”
- 到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
- Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。
- ondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
DataNode
- 提供真实文件数据的存储服务。
- 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
dfs.block.size - 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
- Replication参数,多副本,hdfs-site.xml的dfs.replication属性,默认是三个。
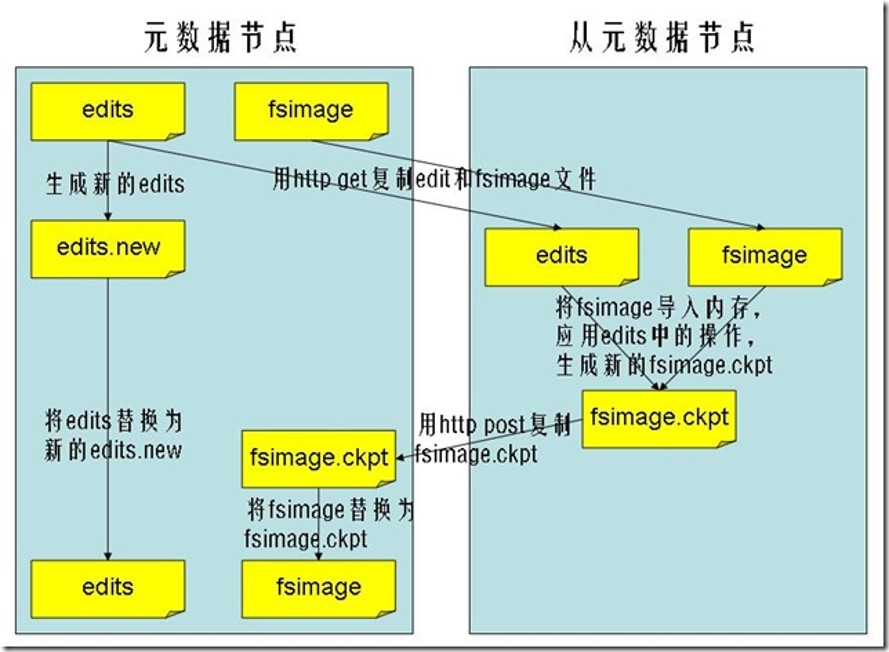
Secondary NameNode
- HA的一个解决方案。但不支持热备。配置即可。
- 执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
- 默认在安装在NameNode节点上,但这样…不安全!
secondary namenode的工作流程
- secondary通知namenode切换edits文件
- secondary从namenode获得fsimage和edits(通过http)
- secondary将fsimage载入内存,然后开始合并edits
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage
Remote Procedure Call
hadoop的远程程序调用机制
- RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
hadoop的整个体系结构就是构建在RPC之上的(见org.apache.hadoop.ipc)。
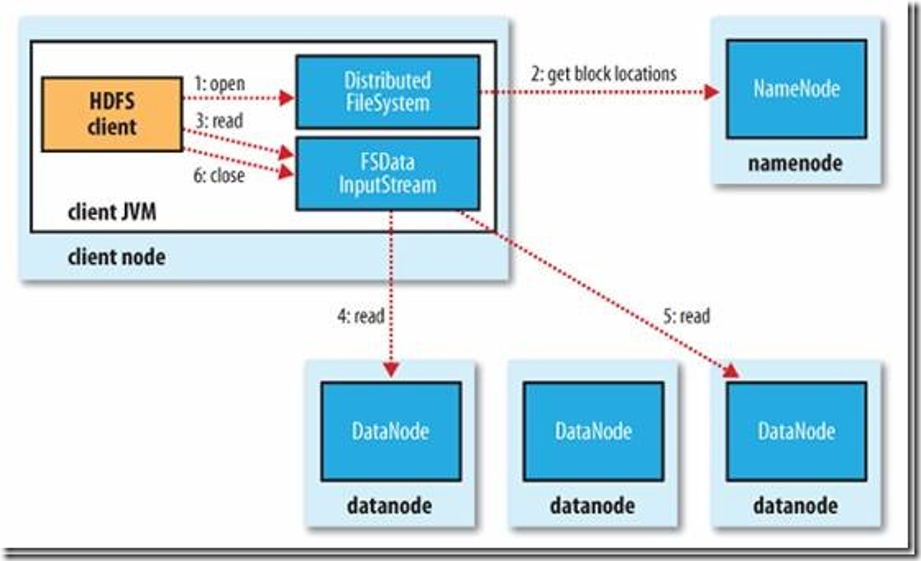
HDFS读过程
- 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
- FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
- FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
- 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
- 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。
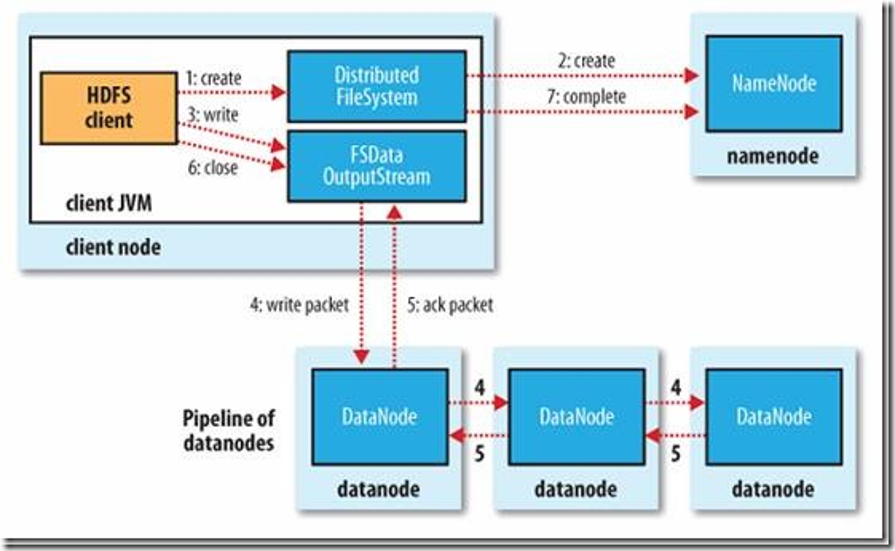
HDFS写过程
- 初始化FileSystem,客户端调用create()来创建文件
- FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
- DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
- 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
- 如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
思考题
hdfs的组成部分有哪些,分别解释一下
HDFS架构由三部分组成,NameNode、DataNode、SecondaryNameNode。详细解释参见HDFS架构
hdfs的高可靠如何实现
HDFS实现其高可靠性的策略及机制 http://blog.csdn.net/lsxy117/article/details/47622159
- 请用shell命令实现目录、文件的增删改查
shell命令实现文件操作 - 请用java api实现目录、文件的增删改查
package com.elon33.hadoop.hdfs;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsClientEasy {
private FileSystem fs = null;
@Before
public void getFs() throws IOException {
// get a configuration object
Configuration conf = new Configuration();
// to set a parameter, figure out the filesystem is hdfs
conf.set("fs.defaultFS", "hdfs://hadoop:9000/");
conf.set("dfs.replication", "1");
// get a instance of HDFS FileSystem Client
fs = FileSystem.get(conf);
}
/**
* 在hdfs文件系统中创建文件目录
*
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testMkdir() throws IllegalArgumentException, IOException {
boolean res = fs.mkdirs(new Path("/upload"));
System.out.println(res ? "mkdir is successfully!" : "it's failed!");
}
/**
* 给文件/文件夹重命名
*
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testRename() throws IllegalArgumentException, IOException {
boolean res = fs.rename(new Path("/upload"), new Path("/upload1"));
System.out.println(res ? "mkdir is successfully!" : "it's failed!");
}
/**
* 上传文件到HDFS
*
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testUpload() throws IllegalArgumentException, IOException {
fs.copyFromLocalFile(new Path("c:/input.txt"), new Path("/upload1"));
}
/**
* 从HDFS系统下载文件到本地
*
* @throws Exception
*/
@Test
public void testDownload() throws Exception {
fs.copyToLocalFile(new Path("/jdk.exe"), new Path("f:/"));
}
/**
* 通过输入输出流完成上传文件 upload local file to HDFS
*
* @throws Exception
*/
@Test
public void testUploadByIO() throws Exception {
// open a inputstream of the local source file
FileInputStream is = new FileInputStream("c:/input.txt");
// create a outputstream of the dest file
Path destFile = new Path("hdfs://hadoop:9000/input.txt");
FSDataOutputStream os = fs.create(destFile);
// write the bytes in "is" to "os" ==> upload local file to HDFS
// IOUtils.copy(is, os);
}
/**
* 通过输入输出流完成下载文件 download HDFS file to local
*
* @throws Exception
*/
@Test
public void testDownloadByIO() throws Exception {
// open a FSDataInputStream of the HDFS source file
FSDataInputStream is = fs.open(new Path("hdfs://hadoop:9000/input.txt"));
// create a outputstream file of the local file
FileOutputStream os = new FileOutputStream("f:/input.txt");
// write the bytes in "is" to "os" ==> download HDFS file to local
IOUtils.copy(is, os);
}
/**
* 删除hdfs文件系统中的文件
*
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testRmfile() throws IllegalArgumentException, IOException {
boolean res = fs.delete(new Path("/upload1"), true);
System.out.println(res ? "delete is successfully :)" : "it is failed :(");
}
/**
* 查询出文件系统指定目录下的文件列表
*
* @throws FileNotFoundException
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
// List the statuses and block locations of the files in the given path
// 循环遍历指定路径下的所有文件 同:hadoop fs -ls -R /
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus file = listFiles.next();
System.out.println(file.getPath().getName());
}
System.out.println("--------------------------------------------");
// List the statuses of the files/directories in the given path if the
// path is a directory.
// 列出该路径下的文件或者目录状态信息
FileStatus[] status = fs.listStatus(new Path("/"));
for (FileStatus file : status) {
System.out.println(file.getPath().getName() + " " + (file.isDirectory() ? "d" : "f"));
}
}
}














 6279
6279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









