







防坑留名:
为了避免以后自己遇到什么坑爹的东西,先留脚印给自己。这个hadoop呢,主要是可以让用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。这点比较厉害了。
它主要是用来做数据分析,支持低端服务器集群(这点美滋滋- - ),先抓取大量数据,利用数据运算分析,获取日志,显示报表~;
本例子用的 环境: jdk 1.8.0_152 \ centos7 \ hadoop3.0
通解:(分布式文件管理系统)
一个电脑或操作系统管辖的范围存不下的文件,分布到更多的操作系统上,但是不方便管理,能对这些文件进行管理的系统就是分布式文件管理系统
(一次写入多次查询的情况,不支持并发写情况,小文件不合适{由hadoop中的FileInputFormat特点决定的,后面会提}。)
目录
2)启动NameNode 和 DataNode 守护进程及secondary namenodes
3)启动ResourceManager 和 NodeManager 守护进程
如有错误异常问题请进入大佬总结错误笔记:
http://blog.itpub.net/26230597/viewspace-1385602/
一、环境准备
1、先测试是否能免密登录:
# ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
2、默认是非免密的(设置):
1、去掉 /etc/ssh/sshd_config中的两行注释,如没有则添加,所有服务器都要设置的
#RSAAuthentication yes
#PubkeyAuthentication yes![]()
2、生成秘钥:
输入命令 ssh-keygen -t rsa 然后一路回车即可
3、复制到公共密钥中
cp /root/.ssh/id_rsa.pub /root/.ssh/authorized_keys![]()
4、之后测试~如下则成功
![]()

3、安装JDK
tips:(如果有1.8及以上的不需要这步,直接跳过)
最简单的方法,不要用自己的jdk慢慢下载了之后然后上传这么low逼好吗?直接 yum 妥妥的。
如果发现yum 之后出现 command not found 进入下面网站或自行百度
http://blog.sina.com.cn/s/blog_63d8dad80101cn2s.html
查看yum上面的java软件包
yum list installed |grep java ![]()
找到对的,直接
yum install 上面操作合适的名字 ![]()
最后输入下面有版本号如图则成功
java version![]()
![]()

设置环境变量,便于hadoop调用
编辑/etc/profile文件,在文件末尾添加以下内容
#set jdk environment
export JAVA_HOME=/usr/java/jdk1.8.0_152
export PATH=$JAVA_HOME/bin:$PATH![]()
4、安装hadoop
1,下载Hadoop3.0.0
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.0.0-alpha4/ 这里找,不建议官网- -,会少东西
2,解压安装
1),复制 hadoop-3.0.0.tar.gz 到/usr/hadoop目录下, 然后#tar -xzvf hadoop-3.0.0.tar.gz 解压,解压后目录为:/usr/hadoop/hadoop-3.0.0
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/hadoop/hadoop-3.0.0 ./bin/hadoop version
2),在/usr/hadoop/目录下,建立tmp、hdfs/name、hdfs/data目录,执行如下命令 #mkdir /usr/hadoop/tmp #mkdir /usr/hadoop/hdfs #mkdir /usr/hadoop/hdfs/data #mkdir /usr/hadoop/hdfs/name
3),设置环境变量,#vi /etc/profile
# set hadoop path
export HADOOP_HOME=/usr/hadoop/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/bin4),使环境变量生效,终端中运行如下命令
#source /etc/profile
CentOS版本用 #source ~/.bash_profile
二、设置hadoop
一共需要配置主要的6个文件
hadoop-3.0.0/etc/hadoop/hadoop-env.sh hadoop-3.0.0/etc/hadoop/yarn-env.sh hadoop-3.0.0/etc/hadoop/core-site.xml hadoop-3.0.0/etc/hadoop/hdfs-site.xml hadoop-3.0.0/etc/hadoop/mapred-site.xml hadoop-3.0.0/etc/hadoop/yarn-site.xml
1)配置hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_152
2)配置yarn-env.sh
#The java implementation to usr
export JAVA_HOME=/usr/java/jdk1.8.0_152
3)配置core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
4)配置hdfs-site.xml
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
5)配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6)配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.88.129:8099</value>
<description>这个地址是mr管理界面的</description>
</property>
</configuration>
三、启动及测试
1)格式化namenode,
#CD /usr/hadoop/hadoop-3.0.0# ./bin/hdfs namenode -format成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错
2)启动NameNode 和 DataNode 守护进程及secondary namenodes
#CD /usr/hadoop/hadoop-3.0.0
# sbin/start-dfs.sh
如果运行脚本报如下错误,
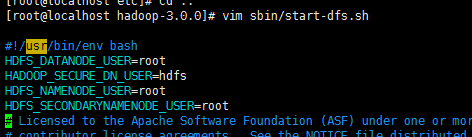
ERROR: Attempting to launch hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch. Starting datanodes ERROR: Attempting to launch hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting launch. Starting secondary namenodes [localhost.localdomain] ERROR: Attempting to launch hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting launch.
解决方案
(缺少用户定义而造成的)因此编辑启动和关闭
$ vim sbin/start-dfs.sh $ vim sbin/stop-dfs.sh
顶部空白处
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root![]()
![]()
3)启动ResourceManager 和 NodeManager 守护进程
#CD /usr/hadoop/hadoop-3.0.0
#sbin/start-yarn.sh
4)启动错误解决
如果启动时报如下错误,
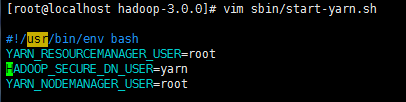
Starting resourcemanager ERROR: Attempting to launch yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
解决方案
(也是由于缺少用户定义)
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本 $ vim sbin/start-yarn.sh $ vim sbin/stop-yarn.sh
顶部添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root![]()
![]()
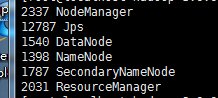
5)启动验证
执行jps命令,如下出现基本完成
![]()
以后启动可以直接写shell脚本执行,vi 创建文件 ,开头第一行 #! / bin/sh ,最后chmod +x filename ,使脚本可以执行。
本例子:
#! / bin/sh
rm -rf /usr/hadoop/hdfs/data/*
rm -rf /usr/hadoop/hdfs/name/*
#启动NameNode 和 DataNode 守护进程及secondary namenodes
sh /usr/hadoop/hadoop-3.0.0/sbin/start-dfs.sh
#启动ResourceManager 和 NodeManager 守护进程
sh /usr/hadoop/hadoop-3.0.0/sbin/start-yarn.sh![]()
6)端口注意问题
记得把防火墙关闭掉或者增加端口允许
/sbin/iptables -I INPUT -p tcp --dport 8099 -j ACCEPT ---上面填写的端口
如果发现不能访问50070端口,可进行如下设置
vi /etc/selinux/config
修改
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=enforcing
为
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled![]()
设置默认访问端口
mapred-site.xml 添加下面两个<property> <name>mapred.job.tracker.http.address</name> <value>0.0.0.0:50030</value></property><property> <name>mapred.task.tracker.http.address</name> <value>0.0.0.0:50060</value></property>hdfs-site.xml 添加下面配置<property> <name>dfs.http.address</name> <value>0.0.0.0:50070</value></property>然后停止所有进程,删除name、data文件夹下数据重新格式化,重新启动后访问正常
--------------------附带debug模式开启与关闭
开启:export HADOOP_ROOT_LOGGER=DEBUG,console
关闭:export HADOOP_ROOT_LOGGER=INFO,console
四、环境测试
1) 测试HDFS
n HDFS shell操作
#查看帮助
hadoop fs -help <cmd>
#上传
hadoop fs -put <linux上文件> <hdfs上的路径>
#查看文件内容
hadoop fs -cat <hdfs上的路径>
#查看文件列表
hadoop fs -ls /
#下载文件
hadoop fs -get <hdfs上的路径> <linux上文件>
2) 上传文件到hdfs文件系统上
hadoop fs -put <linux上文件> <hdfs上的路径>
例如:hadoop fs -put /root/install.log hdfs://localhost:9000/
3)删除hdfs系统文件
hadoop fs -rm hdfs://localhost:9000/install.log
注:如果能正常上传和删除文件说明HDFS没问题。
4) 测试Yarn
n 上传一个文件到HDFS
hadoop fs -put words.txt hdfs://localhost:9000/
n 让Yarn来统计一下文件信息
cd /$HADOOP_HOME/share/hadoop/mapreduce/
#测试命令
tips: ha.txt 内容不方便透露 - -
hadoop jar /usr/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /ha.txt /myorder/![]()
之后就是成功这样了:
![]()
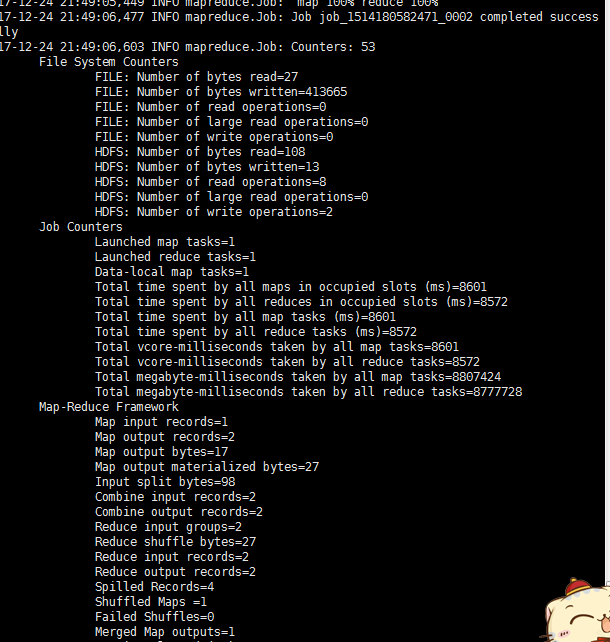
这时候jobID和applicationID出现了
输入命令查看
hadoop fs -ls /myorder![]()
![]()
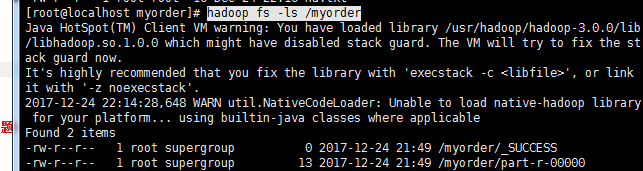
查看内容:
hadoop fs -cat /output/part-r-00000![]()
![]()
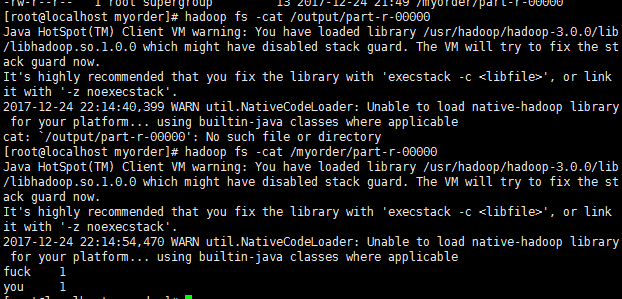
注:如果能正常生成一个目录,并把统计信息输出到文件夹下,说明Yarn没问题。
如果遇到问题:
Failing this attempt.Diagnostics: Exception from contain-launch
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app![]()
那么不急:
进入
cd /usr/hadoop/hadoop-3.0.0/etc/hadoop/![]()
编辑 mapred-site.xml, 添加
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/hadoop/hadoop-3.0.0/etc/*,
/usr/hadoop/hadoop-3.0.0/etc/hadoop/*,
/usr/hadoop/hadoop-3.0.0/lib/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/common/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/common/lib/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/lib-examples/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/hdfs/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/hdfs/lib/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/yarn/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/yarn/lib/*,
</value>
</property>![]()
yarn-site.xml ,*添加*
<property>
<name>yarn.application.classpath</name>
<value>
/usr/hadoop/hadoop-3.0.0/etc/*,
/usr/hadoop/hadoop-3.0.0/etc/hadoop/*,
/usr/hadoop/hadoop-3.0.0/lib/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/common/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/common/lib/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/mapreduce/lib-examples/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/hdfs/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/hdfs/lib/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/yarn/*,
/usr/hadoop/hadoop-3.0.0/share/hadoop/yarn/lib/*,
</value>
</property>![]()
重启一波,返回上面的命令计算,得到满意的结果,没毛病














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









