







一、HDFS基本概念
数据块(block):大文件会被分割成多个block进行存储,block大小默认为128MB。每一个block会在多个datanode上存储多份副本,默认是3份。最后一块即使没有128M,块文件会自动缩到所需的大小。
NameNode :NameNode 负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系。
DataNode:DataNode就负责存储了,当然大部分容错机制都是在DataNode上实现的。
元数据:指HDFS文件系统中,文件和目录的属性信息。HDFS实现时,采用了 镜像文件(Fsimage) + 日志文件(EditLog)的备份机制。文件的镜像文件中内容包括:修改时间、访问时间、数据块大小、组成文件的数据块的存储位置信息。目录的镜像文件内容包括:修改时间、访问控制权限等信息。日志文件记录的是:HDFS的更新操作。
NameNode启动的时候,会将镜像文件和日志文件的内容在内存中合并。把内存中的元数据更新到最新状态。
用户数据:HDFS存储的大部分都是用户数据,以数据块的形式存放在DataNode上。
在HDFS中,NameNode 和 DataNode之间使用TCP协议进行通信。DataNode每3s向NameNode发送一个心跳。每10次心跳后,向NameNode发送一个数据块报告自己的信息,通过这些信息,NameNode能够重建元数据,并确保每个数据块有足够的副本。
二、读写流程
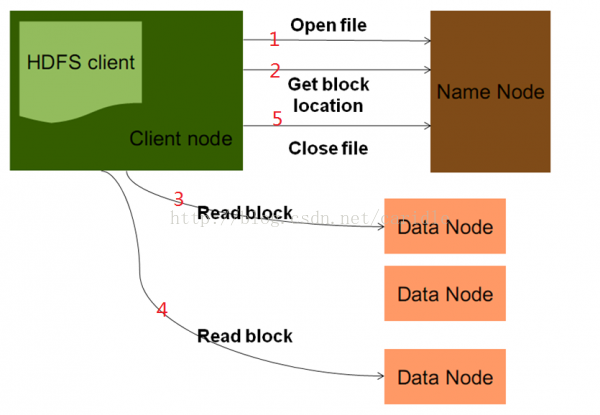
读文件的流程:
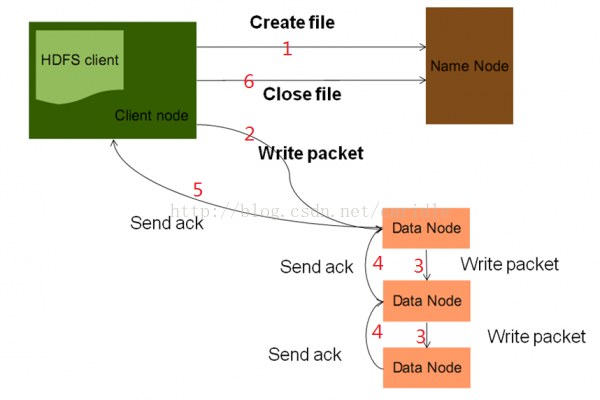
写文件流程
三、java API调用
关于hdfs的api主要在org.apache.hadoop.fs包中。下面的类除标明外,默认都在该包下。
3.1 org.apache.hadoop.conf.Configuration类:
封装了一个客户端或服务器的配置,用于存取配置参数。系统资源决定了配置的内容。一个资源以xml形式的数据表示,由一系列的键值对组成。资源可以用String或path命名,String-指示hadoop在classpath中查找该资源;Path-指示hadoop在本地文件系统中查找该资源。
默认情况下,hadoop依次从classpath中加载core-default.xml(对于hadoop只读),core-site.xml(hadoop自己的配置文件,在安装目录的conf中),初始化配置。这里的classpath是指应用运行的类路径。服务端(hadoop)的classpath指向的是conf。客户端,classpath就是客户端应用的类路径(src)。
方法:addResource系列方法在配置中增加资源。
3.2 FileSystem抽象类:
与hadoop的文件系统交互的接口。可以被实现为一个分布式文件系统,或者一个本地件系统。使用hdfs都要重写FileSystem,可以像操作一个磁盘一样来操作hdfs。
方法:
获得FileSystem实例:
static FileSystem get(Configuration):从默认位置classpath下读取配置。
static FileSystem get(URI,Configuration):根据URI查找适合的配置文件,若找不到则从默认位置读取。uri的格式大致为hdfs://localhost/user/tom/test,这个test文件应该为xml格式。
读取数据:
FSDataInputStream open(Path):打开指定路径的文件,返回输入流。默认4kB的缓冲。
abstract FSDataInputStream open(path,int buffersize):buffersize为读取时的缓冲大小。
写入数据:
FSDataOutputStream create(Path):打开指定文件,默认是重写文件。会自动生成所有父目录。有11个create重载方法,可以指定是否强制覆盖已有文件、文件副本数量、写入文件时的缓冲大小、文件块大小以及文件许可。
public FSDataOutputStream append(Path):打开已有的文件,在其末尾写入数据。
其他方法:
- boolean exists(path):判断源文件是否存在。
- boolean mkdirs(Path):创建目录。
- abstract FileStatus getFileStatus(Path):获取一文件或目录的状态对象。
- abstract boolean delete(Path f,boolean recursive):删除文件,recursive为ture-一个非空目录及其内容会被删除。如果是一个文件,recursive没用。
- boolean deleteOnExit(Path):标记一个文件,在文件系统关闭时删除。
3.3 Path类:
用于指出文件系统中的一个文件或目录。Path String用 “/" 隔开目录,如果以 / 开头表示为一个绝对路径。一般路径的格式为”hdfs://ip:port/directory/file"。
3.4 FSDataInputStream类:
InputStream的派生类。文件输入流,用于读取hdfs文件。支持随机访问,可以从流的任意位置读取数据。完全可以当成InputStream来进行操作、封装使用。
方法:
- int read(long position,byte[] buffer,int offset,int length):从position处读取length字节放入缓冲buffer的指定偏离量offset。返回值是实际读到的字节数。
- void readFully(long position,byte[] buffer) / void readFully(long position,byte[] buffer,int offset,int length)。
- long getPos():返回当前位置,即距文件开始处的偏移量
- void seek(long desired):定位到desired偏移处。是一个高开销的操作。
3.5 FSDataOutputStream:OutputStream的派生类,文件输出流,用于写hdfs文件。不允许定位,只允许对一个打开的文件顺序写入。
方法:除getPos特有的方法外,继承了DataOutputStream的write系列方法。
3.6 其他类
org.apache.hadoop.io.IOUtils:与I/O相关的实用工具类。里面的方法都是静态!
- static void copyBytes(InputStream in,OutputStream out,Configuration conf)
- static void copyBytes(InputStream in, OutputStream out,Configuration conf,boolean close)
- static void copyBytes(InputStream,OutputStream,int buffsize,boolean close)
- static void copyBytes(InputStream in,OutputStream out,int buffSize)
- copyBytes方法:把一个流的内容拷贝到另外一个流。close-在拷贝结束后是否关闭流,默认关闭。
- static void readFully(InputStream in,byte[] buf, int off,int len):读数据到buf中。
FileStatus类:用于向客户端显示文件信息,封装了文件系统中文件和目录的元数据,包括文件长度、块大小、副本、修改时间、所有者以及许可信息。
FileSystem的继承关系如下:
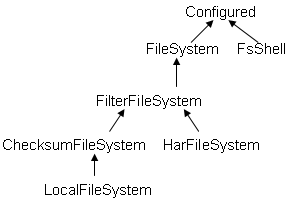
FsShell类:Provide command line access to a FileSystem,是带有主函数main的类,可以直接运行,如Java FsShell [-ls] [rmr]。猜测:在终端使用hadoop fs -ls等命令时,hadoop应该就调用了该类FsShell。
ChecksumFileSystem抽象类:为每个源文件创建一个校验文件,在客户端产生和验证校验。HarFileSystem:hadoop存档文件系统,包括有索引文件_index*,内容文件part-*
LocalFileSystem:对ChecksumFileSystem的本地实现。
四、写编程
首先创建一个文件,将 file-input.txt(可以添加任意内容)传到hdfs://uer/wangxinnian目录中。这里我只启动了一个 slave,以前是三个,所以会处于 safemode。手动离开 safemode 模式:hadoop dfsadmin -safemode leave
上传命令是:hadoop fs -put file-input.txt /user/wangxinnian
1、本地文件在/Users/wangxinnian 目录下,file-input.txt
2、已经启动 Hadoop,http://mymac:50070,选择Utilities 浏览 HDFS上的文件
3、构建开发环境
新建--- maven 工程文件,可以参考 storm,kafka 的编程内容
在 pom.xml 中添加如下依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
4、源代码
package wangxn.hadoop_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Inputfile {
public static void main(String[] args) throws IOException, URISyntaxException {
// TODO Auto-generated method stub
String source="/Users/wangxinnian/file-input.txt";
String dest ="hdfs://mymac:9000/";
putfile(source,dest);
}
public static void putfile(String source,String dest) throws IOException,URISyntaxException {
//读取 hadoop 文件系统的配置
Configuration conf =new Configuration();
URI uri =new URI("hdfs://mymac:9000");
// FileSystem是用户操作HDFS的核心类,它获得URI对应的HDFS文件系统
FileSystem fileSystem=FileSystem.get(uri,conf);
//源文件路径
Path srcPath=new Path(source);
//目的路径
Path dstPath=new Path(dest);
//查看目的路径是否存在
if ( !(fileSystem.exists(dstPath))) {
fileSystem.mkdirs(dstPath);
}
//得到本地文件名称
String fileName=source.substring(source.lastIndexOf('/')+1,source.length());
try {
//将本地文件上传到 HDFS
fileSystem.copyFromLocalFile(srcPath, dstPath);
System.out.println("File " + fileName + " copied to " + dest);
}catch(Exception e) {
System.err.println("Exception caught! :" + e);
System.exit(1);
}finally {
fileSystem.close();
}
}
}
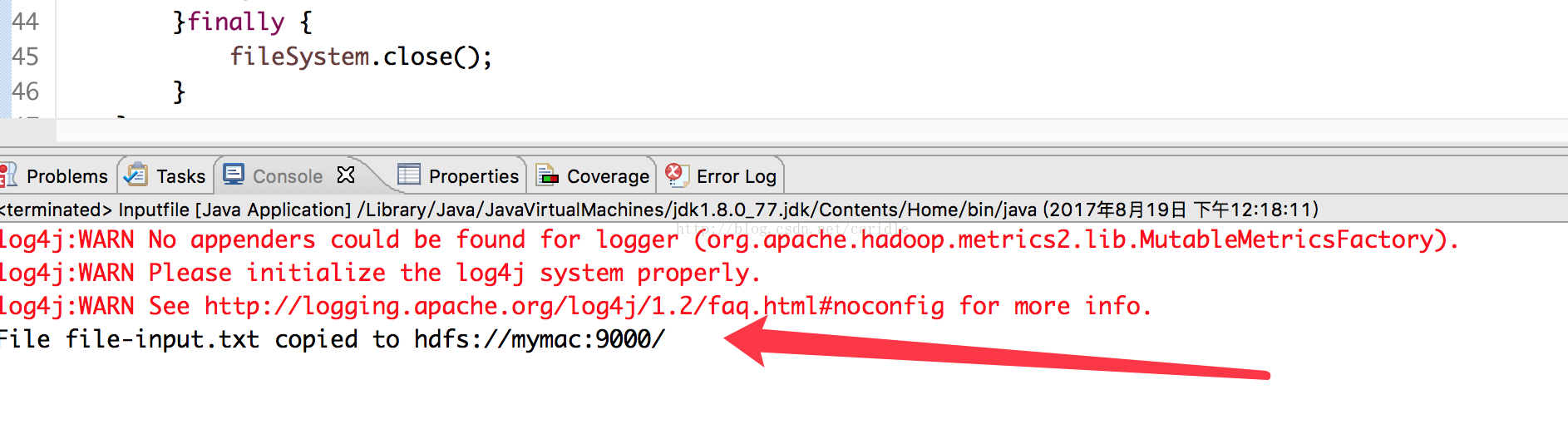
通过浏览器查看,file-input.txt 已经上传到了 HDFS
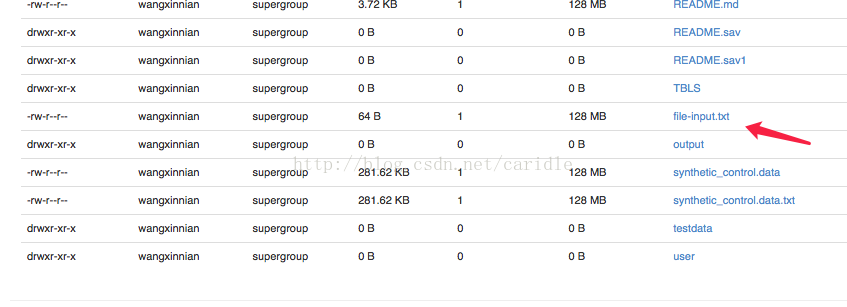
五、读编程
将上传到 HDFS 的 file-input.txt 读出,并在控制台显示文件的内容。另外新建一个类 readFile
package wangxn.hadoop_hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class readFile {
public static void main(String[] args) throws IOException, URISyntaxException {
// TODO Auto-generated method stub
Configuration conf=new Configuration();
URI uri =new URI("hdfs://mymac:9000");
FileSystem fs=FileSystem.get(uri,conf);
//读取数据
Path filePath=new Path("hdfs://mymac:9000/file-input.txt");
FSDataInputStream in=fs.open(filePath);
IOUtils.copyBytes(in, System.out, conf);
in.close();
}
}
运行,控制台输出:
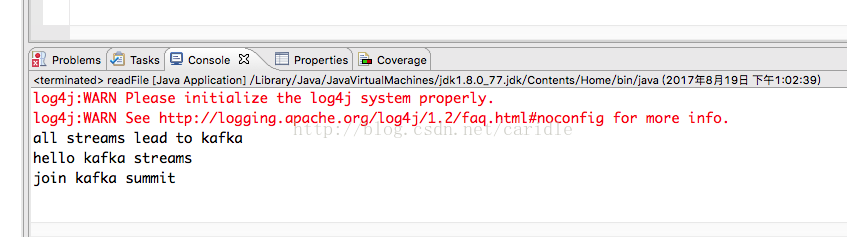

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











