







分类算法简述
一、什么是分类算法
数据挖掘任务通常分为两大类:
- 预测任务,根据其他属性的值,预测特定属性的值。
- 描述任务,概括数据中潜在联系的模式(相关性,趋势,聚类,轨迹和异常)
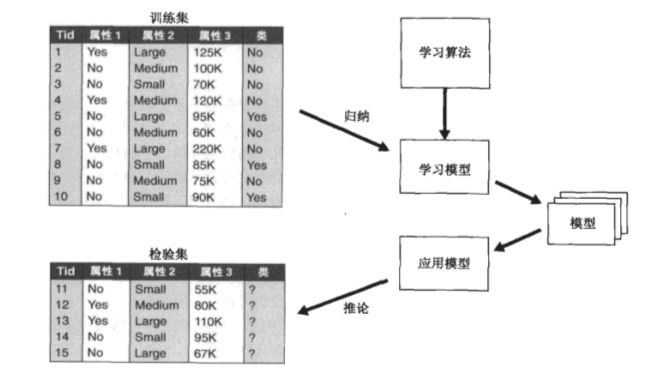
分类属于预测任务,就是通过已有数据集(训练集)的学习,得到一个目标函数f(模型),把每个属性集x映射到目标属性y(类),且y必须是离散的(若y为连续的,则属于回归算法)。
二、分类的基本流程
1、模型建立
分类过程首先需要将生活的数据处理成计算机可以理解的数据(通常为表)。阿里天池竞赛题目为例,已知客户行为信息,以及商品内容,预测推荐哪件商品给客户会被购买。
人的每一个行为都可以抽象成属性,是否购买过同类产品,买东西的频率是多少,从点进去网页到放进购物车的平均时间多少,从放入购物车到下单的时间多少,是否曾经把购物车的东西拿出来过,有无评论买过东西的习惯,有无退货习惯,买过最贵的东西是什么价位,最便宜是什么价位…….
| 数据名 | 属性 |
|---|---|
| 客户id | 1 |
| 是否买过同类产品 | 是 |
| 买东西频率 | 2 |
| 有无退货习惯 | 有 |
| 买过商品最贵是多少钱 | 799 |
| 买过商品最便宜是多少钱 | 32 |
| 买过商品平均是多少钱 | 78 |
| 上次买东西多久前 | 3天前 |
真实生活中数据可能有很多属性,需要我们决定保留哪个属性(特征选择),如“买过最便宜的多少钱”这个属性可以去掉,“上次买东西多久前”与“买东西频率”这两个属性可以只保留一个。接着我们需要将数据转换为计算计可以理解的格式(属性转换与模型建立)如“买东西频率”-》“3天一次”更改为“买东西频率(每月)”-》“0.1”
(1)特征选择
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合
- 增强对特征和特征值之间的理解
(2)数据类型
数据集可以看成数据对象的集合,数据对象的其他名字是记录、点、向量、模式、事件、样本、实体,属性的其他名字为变量、特性、字段、特征、维,属性的数量称为维度
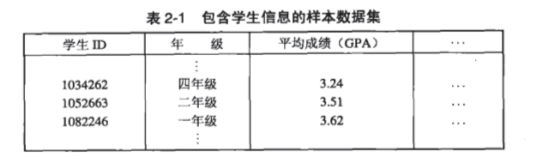
表中的学生id,年级,平均成绩均为属性,每列的所有内容称为一个记录或一个样本。
(3)属性类型与属性转换
首先确定你所选取的特征是什么类型,再通过属性转换为计算机可以理解的格式。如人名属于标称属性,但有时候人名可能会重复,可以将其转换为不重复的id。
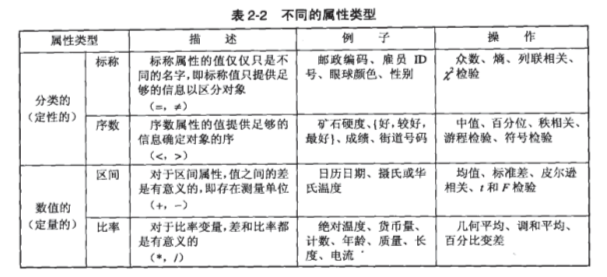
(图片来自《数据挖掘导论》中文版p17)
其次可以根据值的个数,将属性区分为离散属性或者连续属性,如果离散属性中每个值的价值相同如,“皮肤颜色”这个属性中,“黑”,“白”,“黄”三个值的价值相同,但“是否为黑人”这个属性中,“是”,“否”,可能“是”在实际应用中价值更大,前者称为“对称属性”,后者称为“非对称属性”。
(4)模型建立
通过以上几步就可以将生活中的数据转为计算机可以理解的格式如:
对于模型的描述
- 稀疏性:如果数据集非对称属性中,“是”的值很少则认为稀疏性高
- 维度:属性个数
2、算法选择
分类算法按原理分为以下四大类:
- 基于统计:如贝叶斯算法
- 基于规则:如决策树算法
- 基于神经网络:如神经网络算法
- 基于距离:如KNN算法
分类算法按模型可以分为一下两类:
- 预测性模型:直接告诉你数据应被分到哪个类
- 概率性模型:不直接告诉你结果,但告诉你属于每个类的概率
(3)性能与结果的衡量:
- 准确率:指模型正确地预测新的或未见过的数据的类标号的能力,这也是模型的首要能力。如果一个模型的分类准确率小于百分之五十,那么可以认为其结果是无价值的。在其他条件等同的情况下,当然首选准确率高的分类方法。
- 速度:指产生和使用模型的时间复杂度。产生模型的试验数据集通常是巨量的,因为一般情况下其数量和分类准确率成正比。如果产生和使用模型的时间过长,将严重影响用户的使用。
- 稳健性:指给定噪声数据或具有空缺值的数据,模型正确预测的能力。现实中的数据库通常有噪声,有时还很大。如果一个分类器不善于消除噪声的影响,将严重影响分类准确率。
- 可伸缩性:指给定大量数据,有效的构造模型的能力。有些分类器在数据量很小的情况下可以有效的构造模型,随着数据量的增大,其构造模型的能力显著下降,这最终也会影响分类准确率。
- 可解释性:指学习模型提供的理解和洞察的层次。
其中计算准确率主要是通过混淆矩阵( Confusion Matrix)的计算,一个完美的分类模型就是,如果一个客户实际上(Actual)属于类别good,也预测成(Predicted)good,处于类别bad,也就预测成bad。但从上面我们看到,一些实际上是good的客户,根据我们的模型,却预测他为bad,对一些原本是bad的客户,却预测他为good。我们需要知道,这个模型到底预测对了多少,预测错了多少,混淆矩阵就把所有这些信息,都归到一个表里:
预测
true false
实 true a b
际 false c d
其中:
1. d是正确预测到的负例的数量, True Negative(TN,0->0)
2. c是把负例预测成正例的数量, False Positive(FP, 0->1)
3. b是把正例预测成负例的数量, False Negative(FN, 1->0)
4. a是正确预测到的正例的数量, True Positive(TP, 1->1)
5. c+d是实际上负例的数量,Actual Negative
6. a+b是实际上正例的个数,Actual Positive
7. b+d是预测的负例个数,Predicted Negative
8. a+c是预测的正例个数,Predicted Positive
几组常用的评估指标:
- 召回率(recall,R)/敏感性sensitivity:针对good的正确覆盖率,预测对的good实例/实际good的实例 =a/(a+b)
- 精确率(precision,P):预测为good的所有样本中实际为good搜所占的数目,预测对的good实例/预测good的实例 =a/(a+c)
- f-measure:是一种统计量,常用于评价模型的好坏,取值在0到1之间。 f-measure=(2×P×R)/(R+P)
因为大部分情况下准确率提升召回率就会下降,所以一般以f-measure值作为衡量分类器的标准.
三、简单的分类算法介绍
1、如何选择合适的算法
如果你的训练集很小,高偏差/低方差的分类器(如朴素贝叶斯)比低偏差/高方差的分类器(如K近邻或Logistic回归)更有优势,因为后者容易过拟合。但是随着训练集的增大,高偏差的分类器并不能训练出非常准确的模型,所以低偏差/高方差的分类器会胜出(它们有更小的渐近误差)。你也可以从生成模型与鉴别模型的区别来考虑它们。
2、简单的分类模型
朴素贝叶斯(Naive Bayes, NB)
根据条件独立假设与贝叶斯公式,计算样本属于每个类的概率。
决策树(Decision Tree, DT)
根据特征集取值不同,将样本逐层划分并建立规则,直到某一个样本集合内的所有样本属于同一类。
K近邻(K-nearest neighbors, KNN)
kNN 算法的思路非常简单直观:如果一个样本在特征空间中的 k 个最相似 ( 即特征空间中最邻近 ) 的样本中的大多数属于某一个类别,则该样本也属于这个类别。














 4702
4702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









