







1、LSA(隐性语义分析)和SVD(奇异值分解)在VSM(文档空间向量模型中)在文章看做词袋的集合,将文档转换为同一空间向量进行计算,聚类,分类,文本检索是减少计算量,但是难以考虑文档位置以及文档的一词多义性。
基于SVD分解,我们可以构造一个原始向量矩阵的一个低秩逼近矩阵,具体的做法是将词项文档矩阵做SVD分解
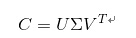
其中 是以词项(terms)为行, 文档(documents)为列做一个大矩阵. 设一共有t行d列, 矩阵的元素为词项的tf-idf值。然后把 的r个对角元素的前k个保留(最大的k个保留), 后面最小的r-k个奇异值置0, 得到 ;最后计算一个近似的分解矩阵
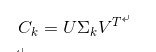
则 在最小二乘意义下是 的最佳逼近。由于 最多包含k个非零元素,所以 的秩不超过k。通过在SVD分解近似,我们将原始的向量转化成一个低维隐含语义空间中,起到了特征降维的作用。每个奇异值对应的是每个“语义”维度的权重,将不太重要的权重置为0,只保留最重要的维度信息,去掉一些信息“nosie”,因而可以得到文档的一种更优表示形式。
缺点:缺乏严密的数理统计
2、pLSA 概率潜在语义分析。PLSA的概率图模型如下
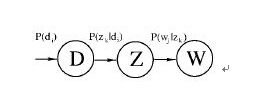
其中D代表文档,Z代表隐含类别或者主题,W为观察到的单词, 表示单词出现在文档 的概率, 表示文档 中出现主题 下的单词的概率, 给定主题 出现单词 的概率。并且每个主题在所有词项上服从Multinomial 分布,每个文档在所有主题上服从Multinomial 分布。整个文档的生成过程是这样的:
(1) 以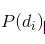
(2) 以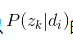
(3) 以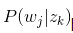
我们可以观察到的数据就是 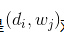
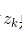
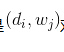
而 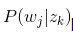
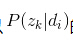
EM算法的步骤是:
(1)E步骤:求隐含变量Given当前估计的参数条件下的后验概率。
(2)M步骤:最大化Complete data对数似然函数的期望,此时我们使用E步骤里计算的隐含变量的后验概率,得到新的参数值。
两步迭代进行直到收敛。
在E步骤中,直接使用贝叶斯公式计算隐含变量在当前参数取值条件下的后验概率,有
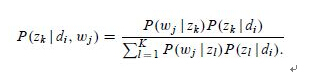
在这个步骤中,我们假定所有的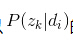
M步骤中通过最大化期望估计出的新的参数值
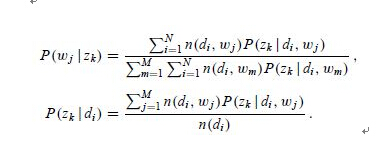
在PLSA中目标函数就是 ,约束条件是
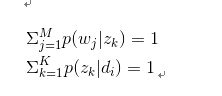
迭代至期望不变
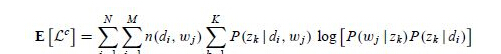
缺点:容易过拟合,不能生成心得文档类型
3、mixture unigram(混合语言模型) about EM
即E步骤 求隐含变量条件概率和M步骤 最大化期望估计参数的公式
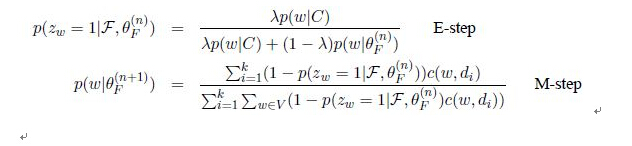
迭代直到对数似然函数停止
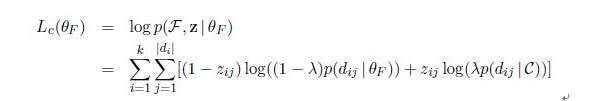
Thetaf与F为两个分布
4、GMM(混合高斯模型) by EM
(1) E步骤:估计数据由每个 Component 生成的概率:对于每个数据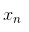
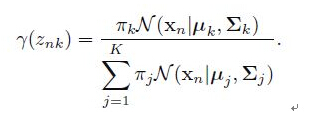
注意里面 和 也是需要我们估计的值,在E步骤我们假定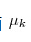
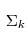
(2)M步骤:由最大估计求出高斯分布的所有均值、方差和线性组合的系数,更新待估计的参数值,根据上面的推导,计算公式是
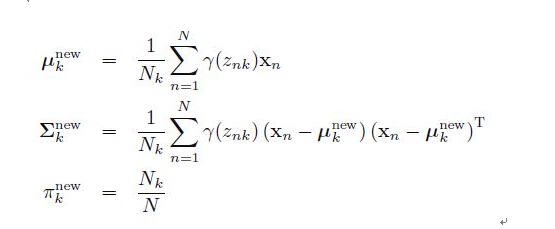
其中
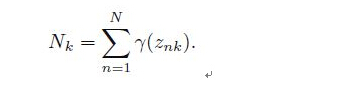
(3)重复迭代E步骤和M步骤,直到似然函数
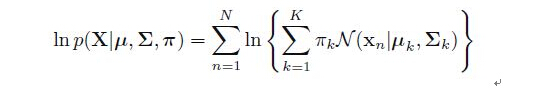
收敛时算法停止。
本文公式推演来自http://blog.csdn.net/yangliuy/article/details/8330640















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









