







Multi-Label Learning 第一周
Multi-Label Learning的含义
从今天开始Multi-Label Learning的学习,我会把学习的一点点心得记录下来,如果有不对的地方,请您指正。
Multi-Label Learning,顾名思义,指的就是多标签学习。其中,learning,当然指的是机器学习,而这里要研究的重点,就集中在Multi-label上。
传统机器学习
在传统的监督学习中,我们的研究对象集合中的一个个体一般通过一个实例(instance),也就是一个特征向量来表达。然后这个实例会与一个标签(label)联系起来,这个标签用来表达这个研究对象的特征(比如它的类别信息)。如下图:
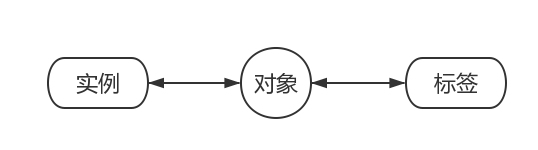
用公式化的说法,就是令 X 为实例(instance)空间, Y 为标签(label)空间,我们的目标就是从数据集 {(x1,y1),(x2,y2),⋯,(xn,yn)} 中学得函数 f:X→Y ,从而我们面对新的样本时,抽取出它的实例,通过 f ,即可得到它的标签,也就确定了它的类别。
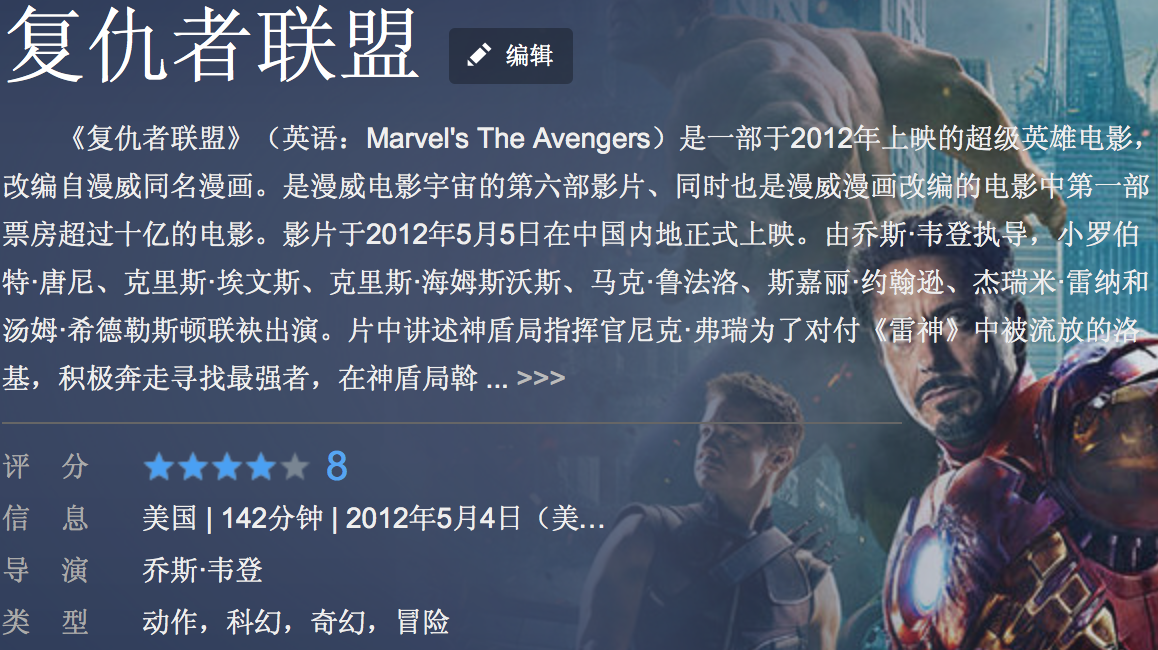
举个比较实际的例子,比如我们要对一些电影进行分类,训练集中的《复仇者联盟》这部电影,可以用一个特征向量对它进行表示,它是属于动作片类型的,于是就有一个“动作片”的标签。然后我们对训练集进行训练,当测试集输入时,与《复仇者联盟》比较接近的影片,被分到“动作片”类别的几率就会大一些。
多标签学习
说到这里,细心的童鞋可能就发现了一个传统方法中很明显的缺陷,那就是现实世界中我们要研究的对象的多类别性。比如,《复仇者联盟》这部电影,它并不是一部单纯的“动作片”,它同时也是一部“科幻片”,“奇幻片”和“冒险片”。
这时,我们就需要引入多标签学习(Milti-Label Learning)的概念了。多标签学习指的就是训练集中的每个对象的实例对应多个标签,进过训练之后,输入新的实例,我们可以得到一个针对这个实例的标签集合。
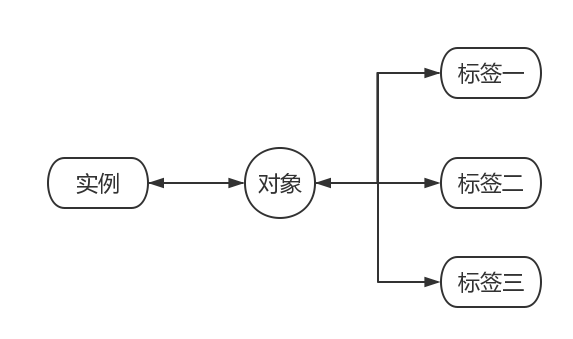
用公式化的表达,就是指定 X={x1,x2,⋯,xn} 为实例集合, Y={y1,y2,⋯,yn} 为标签集合。通过学习,目的是从给定的数据集 {(X1,Υ1),⋯,(Xi,Υi)} (其中 Υi 为第i个实例 Xi 对应的标签集合),上得到一个函数 fMLL:X→2Y 。之后,我们面对测试集对象时,抽取其实例输入函数,即可得到其标签集合。
Multi-Label Learning 算法
目前对MLL的主要算法还不是很了解,先依据搜寻到的资料列出按算法思想分类的算法类别,日后分别对每个算法进行更详细的学习。
分解为多个单标签问题
MLSVM
标签排序
- BoosTexter
- BP-MLL
- RankSVM
发现类间内在联系
- Probabilistic generative models
- Maximum entropy methods
Multi-Label Learning 算法的评估指标
任何算法,我们都要评定算法的优劣,这就需要算法的评估指标。对于Multi-Label Learning算法的评定指标有五个,分别为:
- Hamming Loss(汉明损失):该指标衡量预测所得标签与样本实际标签之间的不一致程度,即样本的预测标签集与世纪标签集之间的差距。这个值越小越好。
- One-error(1-错误率):该指标表示样本预测的隶属度最高的标签不属于其实际标签集的可能性。这个值越小越好。
- Coverage(覆盖率):该指标表示在预测标签集的排序队列中,从隶属度最高的类别开始向下,平均需要跨越多少标签才能覆盖其实际标签集的所有标签。这个值越小越好。
- Ranking Loss(排序损失):该指标表明了样本预测标签集中,预测正确的标签的隶属度低于预测错误的标签的隶属度的可能性。这个值越小越好。
- Average Precision(平均准确度):该指标表示预测标签集的平均准确度。这个值越高越好。















 4097
4097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









