






数据类型关键字
| K& R关键字 | C90关键字 | C99关键字 |
| int | signed | _Bool |
| long | void | _Complex |
| short | _Imaginary | |
| unsigned | ||
| char | ||
| float | ||
| double |
整数与浮点数
整数就是没有小数部分的数。
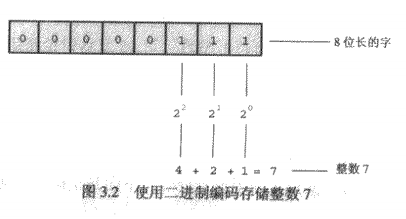
浮点数和数学的实数相对应。
浮点数表示法将一个数分为小数部分和指数部分,并分别存储。
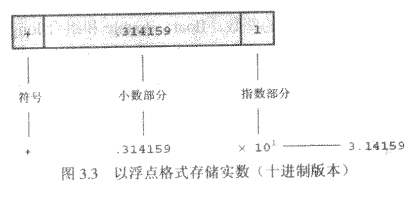
整数和浮点数在应用上的区别:
1.整数没有小数部分,浮点数有小数部分。
2.浮点数可以表示比整数范围大得多的数。
3. 浮点数往往只是实际值的近似值。
4.浮点数运算通常比整数慢。
数据类型
int
short int 简写 short
long int 简写 long
long long int 简写 long long
unsigned int 简写 unsigned
unsigned long int 简写 unsigned long
unsigned short int 简写 unsigned short
unsigned long long int 简写 unsigned long long
signed 有符号,默认是有符号的。
int 类型为16位或者32位,依据自然字的大小而定。int 类型被认为是计算机运算处理起来最方便有效的整数类型。
取值范围在limits.h头文件中定义了。
对于int 范围
1、关于INT取值范围首先是一个标准问题,就拿C来说,INT的取值范围主要由ANSI C规定。这一点是不容置疑的。目前ANSI C规定INT最小不小于16位。
2、关于位宽问题有点像现在面向对像编程里面的继承一样。电脑硬件位宽就是父构件,操作系统OS就是其子构件,编译器又是OS的子构件。子构件可以继承父构件的位宽,但是跟派生不一样,子构件无法超出父构件的位宽。即子构件真包含于父构件。
于是乎得出如此结论:
INT的取值范围取决于编译器。但前提是不超过OS及电脑位宽。
编译器因为其制作的历史条件及环境因素,位宽肯定不会超过当时的操作系统和电脑硬件,但不一定会等于当时的OS及电脑。像TC就是一个很好的例子。当有一个位宽更大的操作系统运行以前的老编译器时(能运行的话),那么所得结果还是以老编译器为准。因此,如果说INT取值范围由操作系统或由电脑决定,虽不能说这种说法错误,但仍然有些不妥。
long 类型可以加l 或者L后缀,long long 类型可以加LL或者 ll ,U或u标识无符号。
打印整型数
printf()的格式说明符 。
%x 十六进制打印
%o 八制打印
%u 无符号打印
%ld 打印long类型,也可以 %lx,%lo
%hd 对short类型以十进制打印
%lu 打印unsigned long 类型
%llu %lld 可以打印 long long 类型。















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









