







 本文探讨了稀疏编码的概念及其在神经科学中的起源,特别是1996年Bruno在Nature上发表的文章如何通过最大化稀疏编码假设解释哺乳动物初级视觉细胞的特性。文章介绍了稀疏编码的基本思想、目标以及与PCA的区别,同时阐述了L1正则化的稀疏性作用,并展示了其在视觉感受野信号处理中的应用。
本文探讨了稀疏编码的概念及其在神经科学中的起源,特别是1996年Bruno在Nature上发表的文章如何通过最大化稀疏编码假设解释哺乳动物初级视觉细胞的特性。文章介绍了稀疏编码的基本思想、目标以及与PCA的区别,同时阐述了L1正则化的稀疏性作用,并展示了其在视觉感受野信号处理中的应用。
稀疏编码来源于神经科学,计算机科学和机器学习领域一般一开始就从稀疏编码算法讲起,上来就是找基向量(超完备基),但是我觉得其源头也比较有意思,知道根基的情况下,拓展其应用也比较有底气。哲学、神经科学、计算机科学、机器学习科学等领域的砖家、学生都想搞明白人类大脑皮层是如何处理外界信号的,大脑对外界的“印象”到底是什么东东。围绕这个问题,哲学家在那想、神经科学家在那用设备观察、计算机和机器学习科学家则是从数据理论和实验仿真上推倒、仿真。在神经编码和神经计算领域,我所能查到最早关于稀疏编码的文献是1996年,在此之前的生命科学家的实验观察和假设都不说了,1996年Cornell大学心理学院的Bruno在Nature上发表了一篇题名为:“emergence of simple-cell receptive fieldproperties by learning a sparse code for nature images”的文章,大意是讲哺乳动物的初级视觉的简单细胞的感受野具有空域局部性、方向性和带通性(在不同尺度下,对不同结构具有选择性),和小波变换的基函数具有一定的相似性。当时描述这些性质主要从自然图像编码的统计结构上来理解这些视觉细胞的特性,但是大部分都没有成功,接着Bruno在文章中提出通过最大化稀疏编码假说成功描述了上述细胞的性质,然后稀疏编码就火了。先来看看这篇文章的核心思想,作者基于一个基本假设,图像是有一些基的线性组合形成,如(公式一)所示:
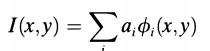
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9950
9950
评论 13

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








