









背景介绍
刚到新公司,老大让我处理Spark方面的工作,公司之前使用的是CDH,我之前一直都是接触Apache官方的Hadoop和Spark,对CDH有所了解,但是没有真正使用。而且,由于CDH相对来讲对Spark的支持总有一些滞后,而公司打算使用最新的Spark 2.0,所以需要使用CDH 中的Yarn和Apache原生态的Spark 2.0。
问题描述
从Apache官网下载spark-2.0.0-bin-hadoop2.6,部署好之后,在Standalone模式下,能用spark-submit提交任务,本以为一切都已经好了,使用yarn应该也不会有什么问题了。没想到,当使用spark-submit提交任务时,就报错了,且不管是Yarn Client还是Yarn Cluster模式都报相同的错误,错误如下:

错误很明显,从数组中取值时超出了数组的范围。瞬间心凉了半截,为什么会这样呢?我运行的是Spark自带的例子,代码肯定不会有问题的,那起问题会出在哪呢?立刻开始Google和Baidu,找了一圈也没找到有在spark-submit提交任务时报这个错误的。继续在网上扒,终于在Google中找到了一个有点关系的了,看到那个网页中的说明,心彻底凉了——居然说是Yarn的一个Bug。但是,仔细想一下,这也说不通呀!如果是Bug,这么多人在用CDH和Spark,那应该早就有人遇到了,也早就被解决了。肯定是其它方面的原因,于是只能靠自己找问题啦!
问题查找
在之前我稍微看过一小部分Spark源码,于是根据报错的位置,开始查看Spark源码。
首先,查看org.apache.spark.deploy.yarn.YarnSparkHadoopUtil.scala在375行附近中的setEnvFromInputString()函数中,代码如下:

很明显,是parts(1)取值的时候超出了数组的范围。但是,又是什么原因会导致这个问题呢?
应该是inputString参数传递进来的时候不是太符合预想的要求,没有等号,导致split("=")得到的数组只有一个元素,所以parts(1)没有取到值,超出了数组范围。
于是,根据报错,继续追踪源码,在org.apache.spark.deploy.yarn.Client.scala中的setupLaunchEnv()函数中,744行附近调用了 setEnvFromInputString()函数,具体代码如下:
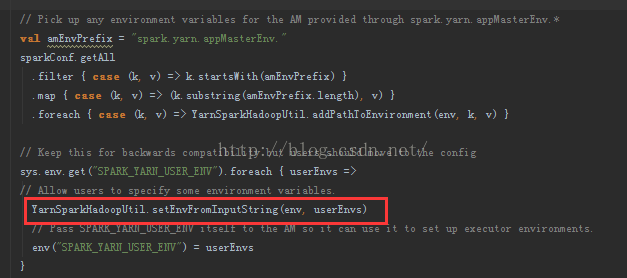
其实这些代码的主要作用是从系统中取出名称为SPARK_YARN_USER_ENV的环境变量的值,并设置在启动AM之前进行设置,作为AM启动的环境变量值。但是,不幸的是,取到的环境变量值与开发者预期的不一致,才导致后来设置环境变量时的异常。既然已经知道问题所在,那么到底Spark运行的时候从环境变量中取得的值是什么样的呢?又该怎么解决这个问题呢?
问题解决
为了查看系统传进来的值到底是什么样的,而我又不知道怎么调试Spark源码的情况下,我打算在源码中进行修改,然后重新编译、打包、运行整个Spark项目。
于是,我在源码中增加了
sys.env.get("SPARK_YARN_USER_ENV").foreach { userEnvs =>
logInfo("Value of SPARK_YARN_USER_ENV is: "+userEnvs)}然后,使用Maven编译、打包,重新部署,再用spark-submit进行任务提交,得到了
Value of SPARK_YARN_USER_ENV is: /opt/cloudera/parcels/CDH-5.6.0-1.cdh5.6.0.p0.45/lib/hadoop/
很明显,跟代码里所需的数据格式不一致,没有等号!且SPARK_YARN_USER_ENV这个环境变量我没有在配置文件中进行设置,得到的这个路径为HADOOP_HOME设置的值。
现在问题已经很明确了,但是该怎么设置SPARK_YARN_USER_ENV这个环境变量的值呢?又该怎么避免代码中从环境变量中获取SPARK_YARN_USER_ENV值时没有等号的问题呢?
接着,我在网上搜了一下,在这篇Bolg上找到了设置方法,虽然他这篇Blog遇到的问题跟我遇到的不一样,但是,这里提到了如何设置SPARK_YARN_USER_ENV。
于是,我在spark-env.sh中添加了
export SPARK_YARN_USER_ENV="CLASSPATH=/opt/cloudera/parcels/CDH-5.6.0-1.cdh5.6.0.p0.45/lib/hadoop/etc/hadoop"额外说明和测试
1. 我在spark-env.sh中设置SPARK_YARN_USER_ENV,将其改成其它的随意的key和值,如下:
export SPARK_YARN_USER_ENV="test=/opt/cloudera/parcels/CDH-5.6.0-1.cdh5.6.0.p0.45/lib/hadoop/etc/hadoop"2.我在另一台机器上,使用了从Apache上下载的Hadoop原版,配置好Hadoop运行环境,并用官方的spark-2.0.0-bin-hadoop2.6版本,没有设置SPARK_YARN_USER_ENV的值,使用spark-submit 以yarn cluster和yarn client模式运行,能正常的运行。说明Spark和Hadoop的原版从系统中获取SPARK_YARN_USER_ENV的值时,不存在上述的问题。这也说明CDH中SPARK_YARN_USER_ENV环境变量的值获取有点问题(个人猜测)。查遍了整个Spark项目源码,也没有找到具体设置SPARK_YARN_USER_ENV的代码,所以,我对于Spark如何设置和读取环境变量中的SPARK_YARN_USER_ENV值还存在一定的疑惑(希望对一点比较熟悉的大牛能指点一下)。
学习心得
这也是我在新公司半个月时间内所遇到的第一个技术问题,整个过程花了将近一个礼拜的时间。虽然,花的时间长了一些,但是在阅读源码的过程中,对Spark提交任务和Yarn上任务运行的流程熟悉了很多,也对Spark有了更多的思考和了解,希望在后面的时间里能有更多的收获!只要足够的耐心和细心,什么技术问题都不是问题^_^














 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









