







实验要求可以参考deeplearning的tutorial,Exercise:Softmax Regression ,softmax回归的原理可以参照之前Logistic and Softmax Regression (逻辑回归和Softmax回归)博文,本实验实现对手写数字0-9的识别(也就是分类)。
1. 神经网络结构:
在之前的博文中谈到,softmax回归是最神经网络,只包含输入成和输出层,而没有隐含层。本实验中的softmax回归有28*28个输入neuron(不包括bias结点),输入层10个neuron。
2. 数据
实验中的数据采用的是MNIST手写数字数据库(0-9手写数字),其中训练数据6万个,测试数据1万个,其中每个样本是大小为28*28的图片。(注意,令数据0为类别10,因为matlab中起始的index为1)
下图是把训练数据中的前100个手写数据图像进行显示。

3 过程:
之后的过程就是构建softmax回归的损失函数(loss function),通过BP算法计算偏导数,梯度检验,最后用L-BFGS算法进行优化,学习得到模型的参数。
4. 注意:
1. 在构造loss函数时,我们需要计算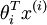
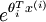

2. 梯度检测本身是一个非常耗时的过程,如果在6万个训练集上进行这个梯度检测,那将花去很长的时间。我们可以缩小训练集的大小,比如说10个,20个,如果在这个小的集上梯度检测的误差很小,锁门我们的BP实现是正确,通过这种方法可以大大缩短梯度检测时间。
5. 实验结果:
经过100次迭代之后,得到所需的参数,最后在测试集上显示92.640%的正确率,这个实验说明中要求的结果一直,所以代码应该没什么错误。

6. 部分代码
softmaxCost.m
function [cost, grad] = softmaxCost(theta, numClasses, inputSize, lambda, data, labels)
% numClasses - the number of classes
% inputSize - the size N of the input vector
% lambda - weight decay parameter
% data - the N x M input matrix, where each column data(:, i) corresponds to
% a single test set
% labels - an M x 1 matrix containing the labels corresponding for the input data
%
% Unroll the parameters from theta
theta = reshape(theta, numClasses, inputSize);
numCases = size(data, 2);
groundTruth = full(sparse(labels, 1:numCases, 1));
cost = 0;
thetagrad = zeros(numClasses, inputSize);
%% ---------- YOUR CODE HERE --------------------------------------
% Instructions: Compute the cost and gradient for softmax regression.
% You need to compute thetagrad and cost.
% The groundTruth matrix might come in handy.
A = theta*data;
M = bsxfun(@minus, A, max(A,[],1));
M = exp(M);
p = bsxfun(@rdivide,M,sum(M,1));
cost = -1/numCases * groundTruth(:)' * log(p(:)) + lambda /2 * theta(:)'* theta(:);
thetagrad = -1/numCases * (groundTruth - p)*data' + lambda * theta;
% ------------------------------------------------------------------
% Unroll the gradient matrices into a vector for minFunc
grad = [thetagrad(:)];
end















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









