







 本文深入探讨了Google Dremel数据模型中的关键概念r和d,阐述它们在数据结构和有限状态机(FSM)执行中的作用。通过对FSM的分析,揭示了r和d如何帮助维护记录查询时的层次结构,以及它们在查询引擎执行SQL类查询时的角色,包括过滤、投影和聚合操作。
本文深入探讨了Google Dremel数据模型中的关键概念r和d,阐述它们在数据结构和有限状态机(FSM)执行中的作用。通过对FSM的分析,揭示了r和d如何帮助维护记录查询时的层次结构,以及它们在查询引擎执行SQL类查询时的角色,包括过滤、投影和聚合操作。
“神秘”的r和d
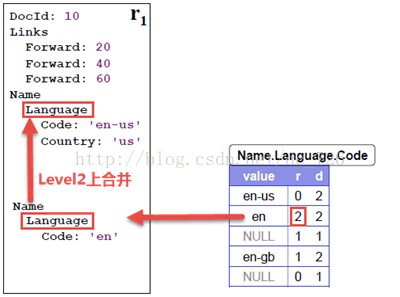
单从数据结构来看的话,我们可以这样解释r和d的含义。r代表着当前字段与前一字段的关系,是在哪一层合并的,即公共的父结点在哪?举例来说,假如我们重建到了Code='en',通过r=2可以知道是在Language那一层发生了重复。
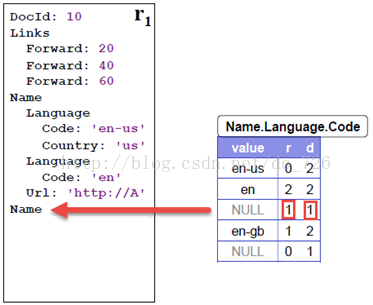
为了保持原纪录的结构,我们会保存一些NULL数据,而d就是用于重建NULL字段。通过d的值,就能知道NULL的结构。例如下图,通过r=1知道应该合并到Name那一层。而通过d=1则知道路径上只有一个字段,即不仅仅是Code字段不存在,Language也不存在。这样就把NULL正确地重建出来了,那么接下来的Code='en-gb'的层级也就不会乱了。
然而这只是从静态的数据结构来解释,而r和d的深层次含义还是要看FSM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9453
9453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









