






前言
虽然 MapReduce 在处理数据时的确有其便捷性。但是当利用 MapReduce 从海量的数据集中提取出有效的特征时,很可能需要等待几个小时甚至更长时间才能出结果,假如发现代码的算法有问题,无法有效地提取特征,因此又重新修改了代码,并再次运行。这样的过程可能要反复好几 次,总的耗时可能多达数天,所以效率极低。
就此Google的团队结合其自身的实际需求,借鉴搜索引擎和并行数据库的一些技术,开发出了实时的交互式查询系统Dremel。
一、Dremel是什么?
Dremel 是Google 的“交互式”数据分析系统。可以组建成规模上千的集群,处理PB级别的数据。MapReduce处理一个数据,需要分钟级的时间。作为MapReduce的发起人,Google开发了Dremel将处理时间缩短到秒级,作为MapReduce的有力补充。Dremel作为Google BigQuery的report引擎,获得了很大的成功。Apache计划推出Dremel的开源实现Drill,将Dremel的技术得到了更广泛的应用。
二、数据模型
- 面向列的存储
Google的Dremel是第一个在嵌套数据模型基础上实现列存储的系统如下(示例):
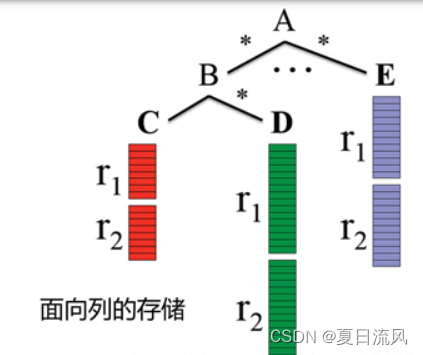
- 嵌套模型定义
原子类型
原子类型允许的取值类型包括整型、浮点型、字符串等
记录类型
记录类型则可以包含多个域,是使用递归方式定义的,即τ能够由其余以前定义好的τ组成,就像c中的结构体,与结构体不大相同的是,每一个包含的τ的值能够有多个(*,repeated,相似c中的数组),还能够是可选的(?,optional,以前那个数组能够不包含任何元素)。由此记录型数据包括三类:必须型(Required)、可重复型(Repeated)以及可选用的(Optional)。其中Required类型必须出现且仅能出现一次。
三、嵌套式的列存储
1.特点与区别
- 关系型数据库
采用列存储有其便利之处,因为在不同列中相同位置的数据必然属于原数据库中的同一行,因此我们可以直接将每一列的值按顺序排列下来,不用引入其他的概念,也不会丢失数据信息。
- 嵌套式数据结构的列存储
数据本身之间的关系比关系数据库要复杂。存储后的数据本身反映不出任何结构上的信息,因此存储中除了记录值,还要记录结构。另外,所有的列存储在应用时往往要涉及多个列,如何按照正确的顺序快速地进行数据重组也是列存储需要解决的。
2.记录的无损表示
如果仅仅是数值(values) 的话,数值本身无法传递出记录(record) 的结构信息。我们不知道两个数值是属于两条不同的记录还是在一条记录下,同时我们也不知道一些可选的字段(field)是否显式定义。因此,我们引入了两个概念:重复深度( Repetition Level )和定义深度( Definition Level )。
- 重复深度( Repetition Level )
定义听起来比较抽象:at what repeated field in the field’s path the value has repeated。意思就是在路径上,在哪个repeated 字段上重复了。
如下图所示:
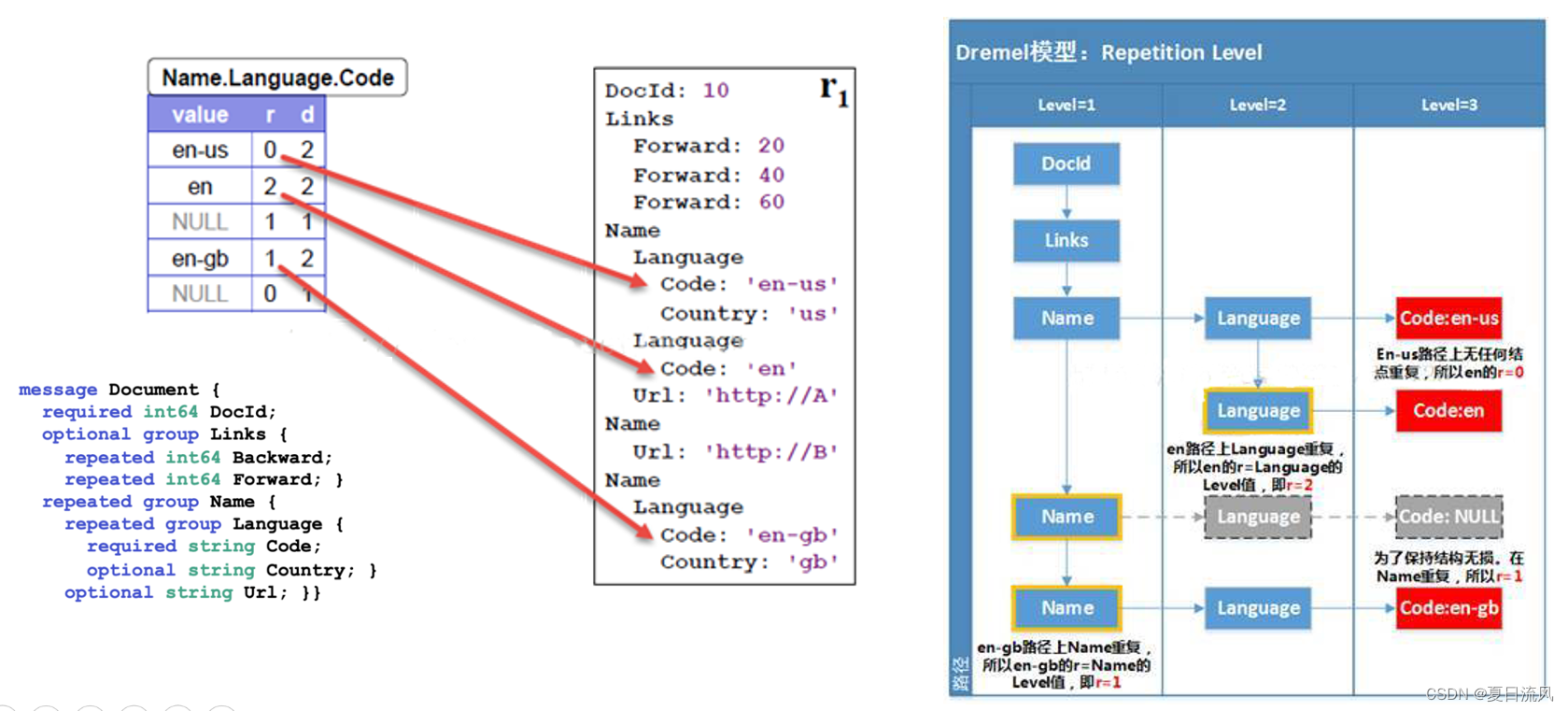
Code(Name.Language.code)中可重复字段有Name、Language
R 的取值为 0:没有重复、1:Name(位置排第一)重复 2:Language(第二)重复
- 定义深度( Definition Level )
定义为:对于具有路径p的字段的每个值,Definition Level表示record中可以是未定义(option/repeated field)但是却实际上是存在的字段的数目。
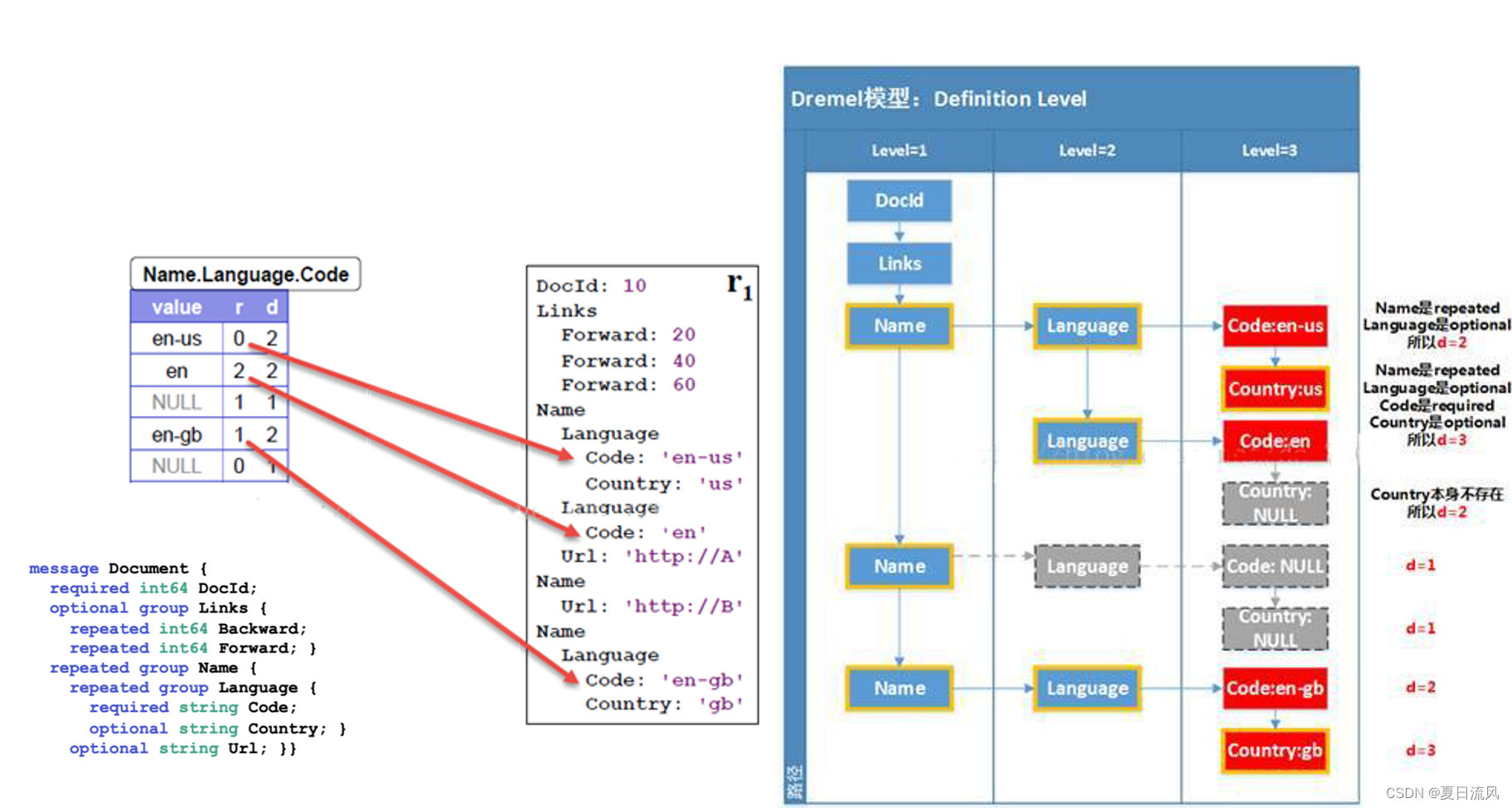
值得注意的几点是:
- 在路径上计算多少字段本可以不存在时,包含了当前字段本身。例如计算Country:us时,Country本身也是optional,也计入总数,所以d=3。
- 每种字段只计算1次。例如最下面的Country:gb,在其路径上的3个Name都满足条件,但只计1次,所以d=3,而不是5。
对于NULL来说,路径p上有多少字段可以是不存在( 例如在文档定义中是optional 或repeated,而不是required ) ,然而实际却存在的。例如文档r1 的Name下没有Code 字段,然而Name 字段却存在( 因为Name下有Url ),所以在表中保存一条NULL,并且d=1。
对于非NULL字段来说,意义不大,因为d 的值对于每种字段来说都是相同的,例如Code都是2,Country都是3。
3.列式储存
每一列都以块(block)的集合进行存储,每个块包含重复深度、定义深度和压缩后的字段值。
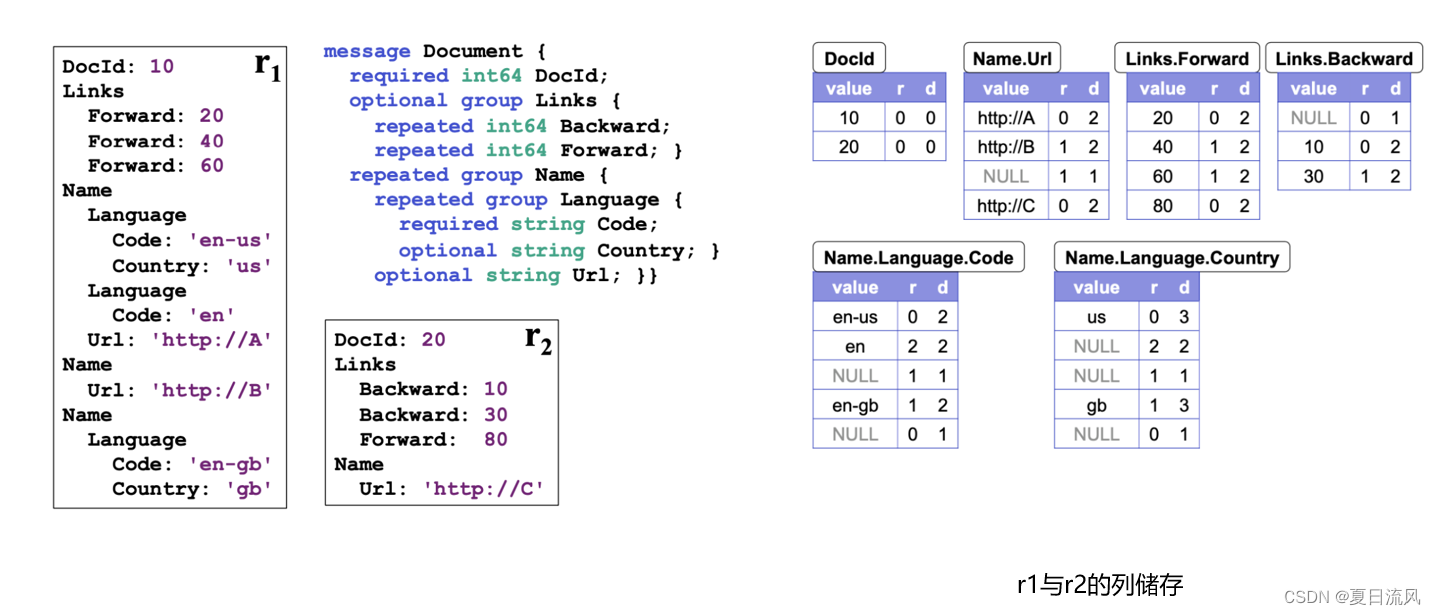
Null值无需存储:因为null可以通过定义深度d来确定:d < 路径上repeated和optional字段总数,就说明是NULL。
始终被定义的值无需存储definition level:例如required int64 DocId(只有required ,始终为被定义)
仅当需要时才存储重复深度:例如定义级别为0,则暗含可重复级别为0,存储时,可以省略掉后者。
使用bit存储level,例如,定义级别最大为3,那么使用2bit就可以表示。

















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









