







前言:上周出去找实习的时候被问到数据库设计的问题,面试人员问我什么是范式,当时脑袋转了一下,隐约记得书里概念。。“第一范式不能再分,然后第二范式一定是第一范式。。。忘记了”想想十分囧。
回来之后赶紧去查资料补一下,想想在学校只是跟着老师简单做增删改查,即使提及这个概念也只是简单掠过,印象不是很深。但是范式在实际数据库开发还是很重要的。
在微信看到一位前辈写的《从范式谈起》结合例子觉得比书面语言好理解。
数据库又可理解为关系数据库,它用来表示实体或者其属性之间的关系。
举个例子:
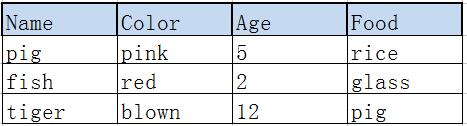
这是一组4元组(有4个(列)属性),竖着看每个元素都是属性
横着看每一行都是一个关系(行)。
切入正题
第一范式:简单理解为,每个属性其值不能再细分,你说猪的食物就说食物,颜色就说颜色。
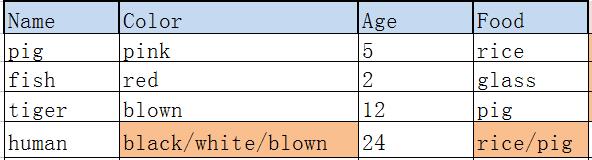
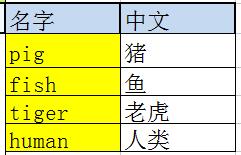
比如一下这个就不是第一范式:
因为它一个属性包含了多个值如果要改为符合第一范式可以这么设计
多建两个表:
把多个属性和对应主键分开
在数据库设计时候,要考虑最小属性,而不是属性中的属性.
第二范式:符合第一范式的前提下,每个非主属性完全依赖与主键.
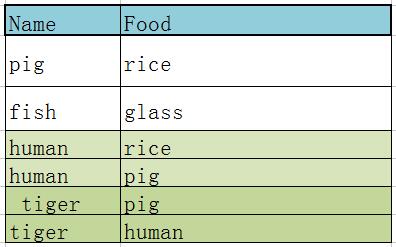
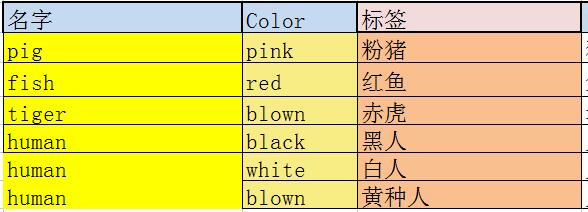
反例如下图:
此表的主键为: 名字+颜色
每个标签都由主键唯一确定.
但是其中的中文(非主属性)仅仅由主键的子集 名字 确定,因此不符合第二范式.优化如下:
新建一张表, 名字+中文
再把上表中文一列去掉,主键(名字+颜色)确定唯一一个非主属性(标签)
第三范式
第三范式前提是满足第二范式,所以当然它也必须满足第一范式.第三范式中,所有非主属性不允许被主键之外的属性唯一对应,区别于第二范式(非主属性不允许被主键的子集唯一对应)
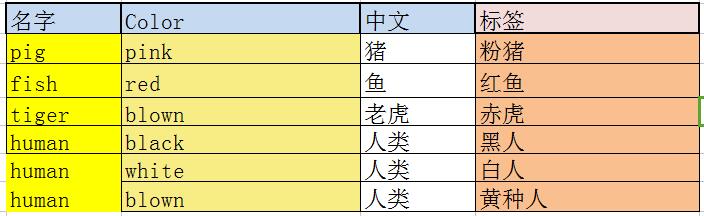
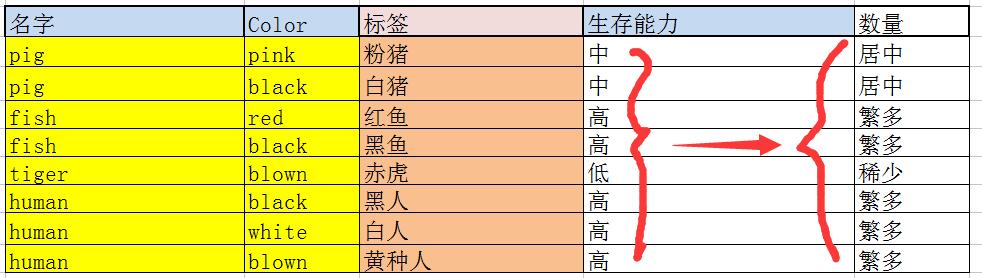
举个反例:
可以看到,某一非主属性(数量)仅仅由非主属性(生存能力)所确定,与主键没有关系.因此它不属于第三范式.
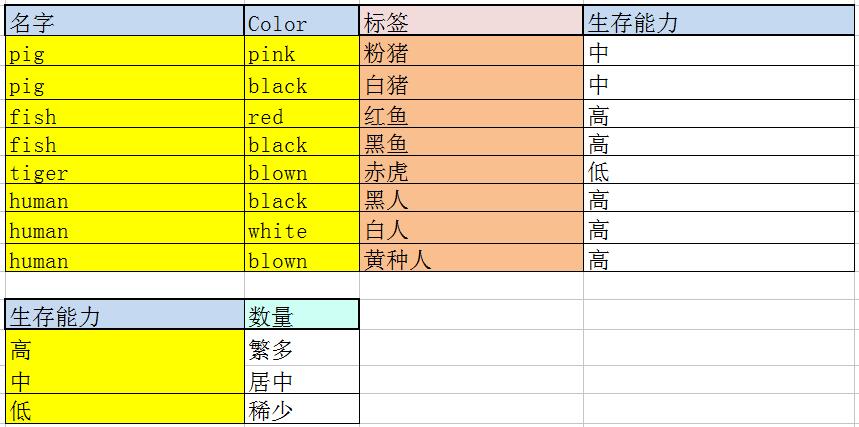
纠正:
把生存能力单独与数量建表:

第三范式
从第一范式到第三范式,这是一个去除重复的过程.尽可能的把重复冗余的属性抽离出来新建表,保证了数据的一致性.
参考文章 余晟以为《从范式谈起》















 6511
6511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









