









在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的。
一、爬虫类编写(spider.py)
from scrapy.spider import BaseSpider
class test(BaseSpider):
name = "test"
allowed_domains = ["yuedu.baidu.com"]
start_urls = ["http://yuedu.baidu.com/book/list/0?od=0&show=1&pn=0"]
def parse(self, response):
print response.url
二、爬网页:运行scrapy项目
这里选择从命令行启动运行项目的方式,一定要注意工程目录结构,能够运行scrapy命令的只有scrapy安装的根目录下。
cd到scrapy的根目录,我的是D:\Python27\,然后运行scrapy命令:scrapy runspider test\test\spiders\spider.py。(或者直接运行工程项目的命令scrapy crawl test),可以看到爬虫爬取的过程有一些debug信息输出:
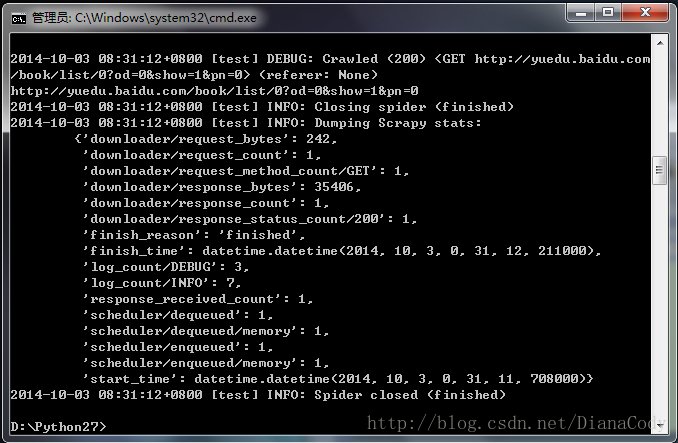
scrapy给爬虫的start_urls属性中的每个url创建了一个scrapy.http.Request对象,指定parse()方法为回调函数。当这些Request被调度并执行,之后通过parse()返回scrapy.http.Response对象,返回给爬虫。
三、取网页:网页解析
这里用shell爬取网页,cd到项目的根目录test\下,在cmd中输入:
scrapy shell http://yuedu.baidu.com可以看到结果如下图:
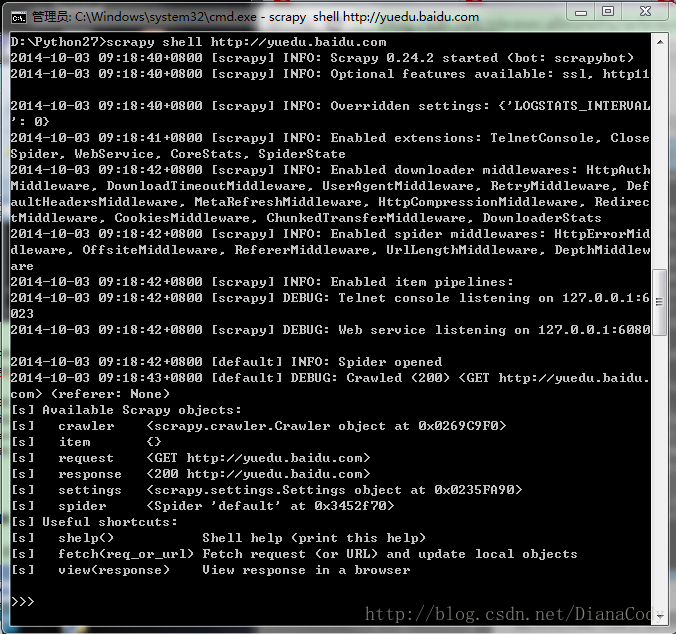
刚才的整个过程中,shell载入url后获得了响应,由本地变量response存储响应结果。
来看下response的内容,输入response.body可以查看response的body部分,即抓到的网页内容:

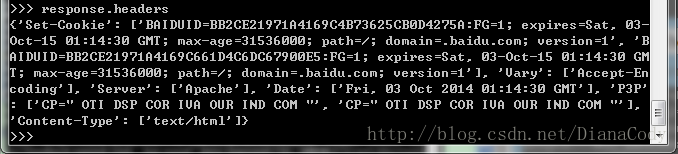
要查看head部分,输入response.headers:
四、用选择器xpath提取网页
之前提取网页是用的正则,这里选择器xpath提供了更好的接口。shell有一个selector对象sel,可以根据返回的数据类型自动选择最佳的解析方式(XML or HTML),无需再指明了。
1.抓取网页标题,即<titie>标签,在命令行里输入:response.selector.xpath(‘//title’)

或者:response.xpath(‘//title’)
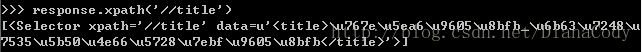
2.抓取<title>下的<text>内容,命令sel.xpath(‘//title/text()’).extract()

先写到这里,下篇文章给出一个关于scrapy项目的完整实例。
原创文章,转载请注明出处:http://blog.csdn.net/dianacody/article/details/39753933















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









