







1、lvs负载均衡集群简图:
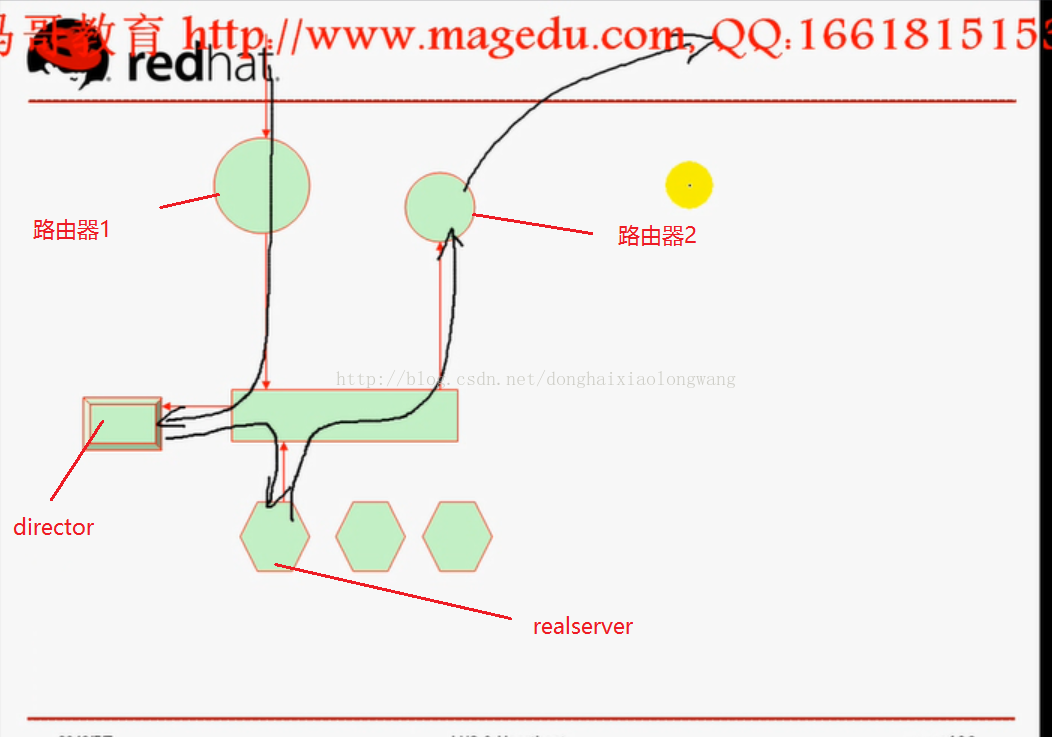
注释:
director为请求代理服务器,
realserver为后端真实服务器
路由器1提供给director公网ip地址(用户请求数据包都会从这个路由器进入)
路由器2提供给所有服务器内网地址(响应用户的所有数据包从这个路由器出去)
一般来说,上图中director至少有一个公网IP地址,用于给互联网用户提供访问接口。其余的机器都是私有ip地址就可以。当然如果每个机器的ip都是公网ip的话更好(当然小公司不太可能有这实力)。 我们测试的时候就把所有的机器放到同一个物理网络(接在同一个交换机上,所有主机网卡类型都是桥接的就可以了)的逻辑网络里边就行了。没那么多资源
2、准备机器:1台director、2台realserver
集群准备工作我们主要解决问题:如何给realserver配置VIP、如何使realserver响应的报文原地址是VIP而不是RIP、如何控制配置有VIP的realserver不响应ARP报文(意思就是虽有VIP地址但是不能把自己的mac地址响应出去,因为只有director才能将自己的VIP对应的mac响应出去)。下边有详细步骤,操作完就会知道原理。
进行下方步骤之前,先在各个realserver上装上httpd服务,我们对http服务进行负载均衡测试。
yum install httpd -y
在各个realserver上提供个简单页面,内容自定义。能看出差异来就行。
vim /var/www/html/1.html
2、1 director分配两个地址(一块网卡就可以了):VIP192.168.99.201配置到eth0:0上 DIP192.168.99.202 配置到eth0上 。 ###VIP就是提供给用户的访问接口。
在director上执行 :ifconfig eth0 192.168.99.202/24 ; ifconfig eth0:0 192.168.99.201/24 ###修改方法很多,可以使用setup命令修改。也可以自己修改/etc/sysconfig/network-script/ifcfg-eth#的文件并重启网络服务。
2、2 realserver1上配置一个地址:RIP192.168.99.207 ##RIP就是真实服务器的ip地址
执行命令ifconfig eth0 192.168.99.207/24 ##setup命令进行配置也行,修改/etc/sysconfig/network-script/ifcfg-eth#文件也行。
2、3 realserver2上配置一个地址:RIP192.168.99.208
执行命令ifconfig eth0 192.168.99.208/24 ##setup命令进行配置也行,修改/etc/sysconfig/network-script/ifcfg-eth#文件也行。
2、4 控制realserver对ARP报文的响应,并且设置VIP。(因为代理服务器要将客户端数据包转发到各个realserver端,所以必须要使realserver有VIP地址。又因为数据包必须现发给director然后由director分发给各个realserver才行,所以必须使得realserver不能响应ARP报文)
执行命令:在每个realserver上都执行一遍,保障每个realserver不会响应ARP报文
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore
设置每个realserver的VIP地址:每个realserver上都执行一遍配置好VIP
ifconfig lo:0 192.168.99.201 broadcast 192.168.99.201 netmask 255.255.255.255
测试下各个主机间是否能通信:保正各个主机间能ping通。(如果不能ping通,可能防火墙未关闭。)
2、5 给各个服务器添加路由,保正realserver相应的数据包原地址使用VIP而不是RIP。(因为realserver相应的数据包会从eth0网卡出去,linux系统会默认使用eth0上的RIP作为数据包的原地址,我们必须使用VIP做为源地址才可以,否则客户端是不会接收数据包的)
执行命令:在各个realserver上都执行
route add -host 192.168.99.201 dev lo:0 ##意思是所有从lo:0进来的数据包,响应后必须使用lo:0上的地址作为原地址。而不管从那块网卡出去
执行命令:在director上执行,这条路有不是必须的,但官方是这样要求的。
route add -host 192.168.99.201 dev eth0:0 ##提示192.168.99.201是VIP地址。director会将数据包转发给他挑选的realserver服务器(通过mac地址转发的,不修改ip地址。这就是为什么说所有机器必须在同一个物理网络中)
测试所有主机间是否能够通信:互相ping下,通了就行了。
2、6 上方已经将服务器准备完毕,我们开始写lvs规则。
在director上执行命令:
ipvsadm -A -t 192.168.99.201:80 -s wlc ##添加一个集群服务,-t指的是tcp服务,192.168.99.201:80指的是在VIP的80端口上监听。 -s wlc 指定集群选择realserver的算法(权重最少连接算法)。
ipvsadm -a -t 192.168.99.201:80 -r 192.168.99.207 -g -w 1 ##向集群服务添加一个realserver机器,权重为1。-g表示使用DR工作模式,可省略。
ipvsadm -a -t 192.168.99.201:80 -r 192.168.99.208 -g -w 2 ##第二个realserver服务器,权重为2
ipvsadm -L -n ##查看下规则是否添加好了
service ipvsadm save ##保存ipvs规则。/etc/sysconfig/ipvsadm 文件就是保存的位置。打开看下。这样保证重启ipvsadm后规则依然存在。##重启 :service ipvsadm restart
2.7 测试,查看是否有效果
在第四台机器上运行多次:curl http://192.168.99.201/1.html
也可以在windows上打开浏览器输入:http://192.168.99.201/1.html ##刷新多次
注意:测试的时候,最好使用linux下的curl命令。
如果在windows上运行浏览器测试,因为我们在同一个物理网络,windows操作系统的ARP缓存表会对集群测试产生影响。而没有效果。想要看到效果,你必须每次刷新浏览器前,先清空arp缓存表。你需要以管理员权限运行cmd.exe并且执行:arp -d 。windows操作系统(至少windows10是这样的)第一次会使用director的mac地址发送请求,以后都使用realserver的mac地址发送。这样我们的director就悲剧的起不到作用了(都不用director转发了)。其实这种情况在真实的环境下是不会存在的。(客户不会和你在同一个物理网络中)我测试的时候就被windows坑了,找到这个问题足足用了10多个小时,还以为我配置的有问题呢。悲剧啊
附加:我们的集群搭建完毕,但有一种情况就是,后端realserver出了问题,前端的代理director是不知道的。那用户的请求仍然会被发往该故障服务器。因此我们需要“检测后端realserver”是否正常,并且动态的移除故障realserver和添加从故障恢复的realserver。
这里附上逻辑,代码自己开发。
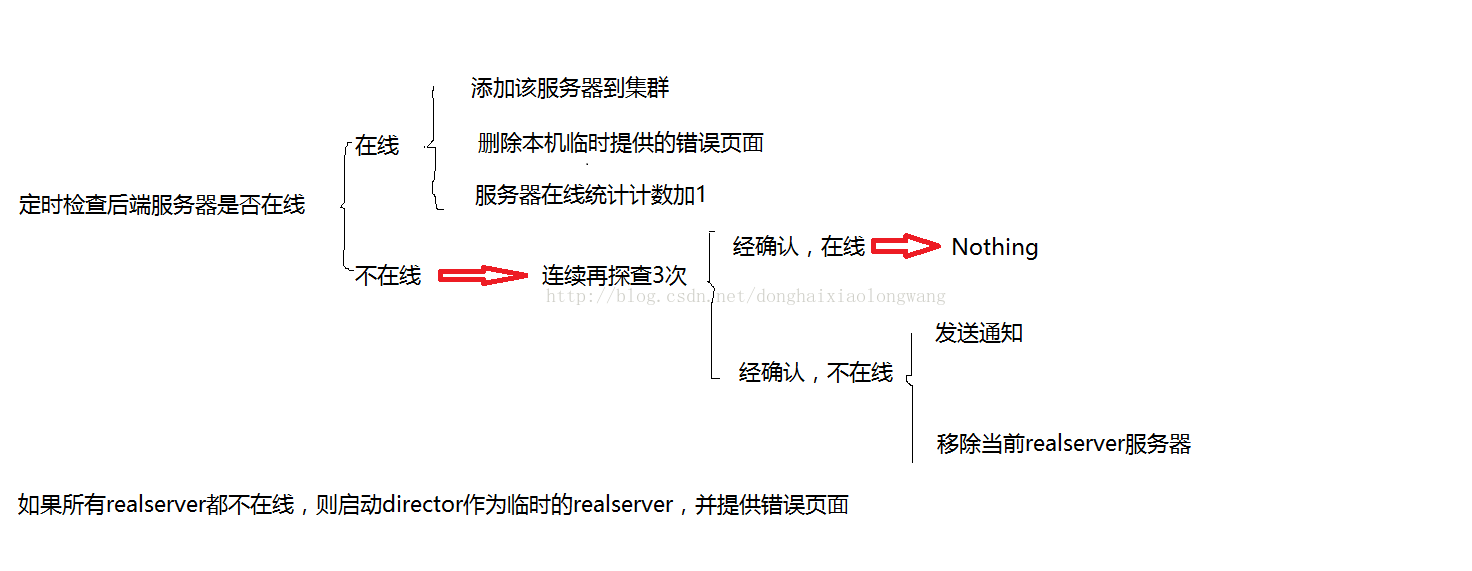
写上述自动化脚本时的参考命令和工具:shell脚本的基础语法,请参看之前的博客文章
curl --connection-timeout 1 http://192.168.99.201/1.html ###请求页面,若失败则不在线。 --connection-timeout 设置超时时间,否则curl会阻塞很长时间
curl -I --connection-timeout 1 http://192.168.99.201/1.html ###如果页面内容多,可以只请求头。-I表示只返回响应头
echo $? ##查看上述命令是否执行成功,0成功,1失败
ARRAY=("192.168.99.201" "192.168.99.202") ##shell脚本数组初始化
echo ${ARRAY[0]} ##引用数组元素第一个
echo ${#ARRAY[*]} ##数组个数
echo ${ARRAY[*]} ##数组元素列表
echo ${#ARRAY[0]} ##数组第一个元素的长度















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









