







注:
这里谈论的2PC不同于事务中的2PC,而是专门为了同步和高可用改过的2PC协议
问题:
寻求一种能够保证,在给定多台计算机,并且他们之间由网络相互连通,中间的数据没有拜占庭将军问题(数据不会被伪造)的前提下,能够做到以下两个特性的方法:
1)数据每次成功的写入,数据不会丢失,并且按照写入的顺序排列
2)给定安全级别,保证服务可用性,并尽可能减少机器的消耗
基础场景:
假定有两个人,李雷和韩梅梅,李雷让韩梅梅去把隔壁班的电灯关掉,这时候,韩梅梅可能有以下三种反馈:
1)“好了,关了”(成功)
2)“开关坏了,没法关”(失败)
3)(因为网络原因,无反馈)
两阶段提交
假如我有两台机器A和B,A是Coordinator(协调者),B是Cohorts(同伴,支持者)

A将某个事件通知给B,B会有以下几种反馈:
1.成功
2.失败,比如硬盘满了?不符合某些条件?为了解决这个情况,所以我们必须让A多一个步骤:准备,准备意味着如果B失败,那么A也自然不应该继续进行,应该将A的所有已经做得修改回滚,然后通知客户端:错误啦。
因此,我们为了能做到能够让A应付B失败的这个情况,需要将同步协议设计为:
PrepareA -> CommitB -> Commit A
使用这个协议,就可以保证B就算出现了某些异常情况,数据还能够回滚
我们再看一些异常情况:
PA->CB(B机器挂掉):在CommitB失败,回滚PrepareA
PA->CB->CA(A机器挂掉):CommitA失败,在A这个机器重新恢复后,因为自己的状态是PA,所以它必须询问B机器,你提交了没有?如果B回答提交成功,那么A也必须将自己的数据进行提交,以达到一致。
其实,我们排除了一种最恶心的情况,这就是网络上最臭名昭著的问题,无反馈
无反馈这个情况,在2PC中只会在一个地方出现,因为只有一次网络传输过程:A把自己的状态设置为prepare,然后传递消息给B机器,让B机器做提交操作,然后B反馈A结果
那么,这无反馈意味着什么呢?
1.B成功提交
2.B失败
3.网络断开
以A机器的角度来看,有两类事情无法区分出来:
1)B机器是挂掉了呢?还是网络断掉了?
2)要求B做的操作,是成功了呢?还是失败了呢?
在无反馈的情况下,无法区分是成功了还是失败了,于是最安全和保险的方式就是等…等到B给个反馈,这种在可用性上基本上是0分了;A得不到B的反馈,又为了保证自己的可用性,唯一的选择就是:等待一段时间,超时以后,认为B机器挂掉了,于是自己继续接收新的请求,而不再尝试同步给B。
然而,这个选择会带来更大的问题,左脑和右脑被分开了。我们假定A所在的机房有一组clientA,B机房有一组clientB。开始时,A是master:
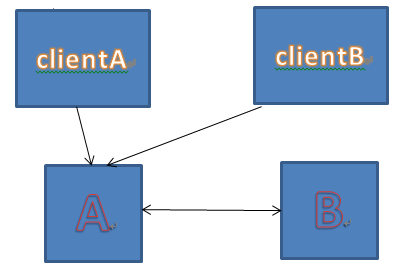
一旦发生断网:
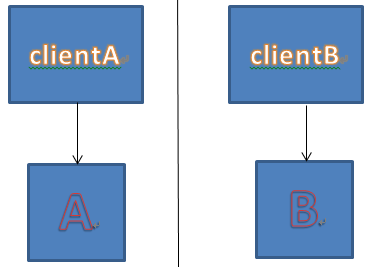
在这种情况下,A无法给B传递信息,为了可用性,只好认为B挂掉了。允许所有clientA提交请求到自己,不再尝试同步给B。而B与A的心跳也因为断网而中断,他也无法知道,A到底是挂掉了呢?还是只是网断了,但为了可用性,只好也把自己设置为主机,允许所有clientB写入数据。于是,出现了两个master。
两阶段提交解决了什么问题,以及存在什么问题?
两阶段提交协议是实现分布式事务的关键;存在的问题是针对无反馈的情况,除了“死等”,缺乏合理的解决方案。
针对“死等”问题,有人提出了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









