









有如下一张表
select s.id,s.name,s.grade,s.clazz,s.score from student s order by id 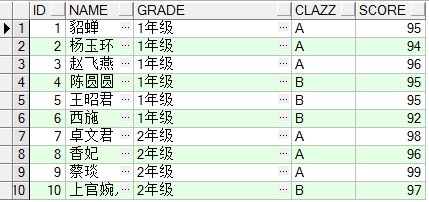
1.rollup
group by rollup(column1,column2....)
假如group by rollup(A,B,C),首先会先对A,B,C进行group by,然后对A,B进行group by,接着对A进行group by, 最后不group by了,也就是对所选择的列( 如A,B,C)从右到左,一次少一列进行group by ,直到最后没了,不使用group by 了。
可这样理解:
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
除非一开始就有基础了,否则看一些概念性的东西都是糊里糊涂的,所以请直接看下面数据,用数据来说话.
对上面的表使用group by rollup(grade,clazz)进行求总分、平均分,先看看结果,然后再分析.
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by rollup(s.grade,s.clazz) 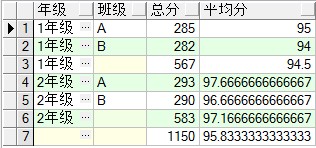
图一
按照上面的说法,group by rollup(grade,clazz),会先对grade,clazz进行group by,那么先看看对grade,clazz进行group by得出的是哪些列.
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.grade,s.clazz 
得出的是 图一中的1,2,4,5四列。接着对grade进行group by求总分和平均分,看看结果,得到哪些列。
select s.grade 年级,'' 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.grade
得出的是 图一中的3,6两列。最后不使用group by,进行求总分和平均分。
select '' 年级, '' 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s 
得出的是 图一中的第7列。
由此可知
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by rollup(s.grade,s.clazz) ;
-------相当于---------
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.grade,s.clazz
union all
select s.grade 年级,'' 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.grade
union all
select '' 年级, '' 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s ;2.cube
group by cube(column1,column2....)
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by cube(s.grade,s.clazz) order by 年级;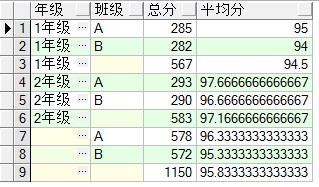
图二
图二和图一比对,发现多了两行,因为cube会对每一列都进行一次group by,也就是多了group by(clazz).在这就不一一把每列的结果是怎样出来的进行贴图了,它和上面的rollup差不多,只是多了一个group by而已。
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by cube(s.grade,s.clazz) order by 年级;
---------相当于--------
select s.grade 年级, s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.grade,s.clazz
union all
select s.grade 年级,'' 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.grade
union all
select '' 年级,s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by s.clazz
union all
select '' 年级, '' 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s 3. grouping
GROUPING函数可以接受一列,该列必须是group by中出现的,返回0或者1。如果列值为空,那么GROUPING()返回1;如果列值非空,那么返回0。GROUPING只能在使用ROLLUP或CUBE的查询中使用。当需要在返回空值的地方显示某个值时,GROUPING()就非常有用。
select grouping(s.grade), s.grade 年级, grouping(s.clazz), s.clazz 班级,sum(s.score) 总分,avg(s.score) 平均分
from student s group by rollup(s.grade,s.clazz) ;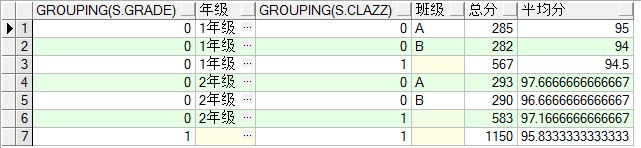
在上面的图一和图二中发现,对于某些统计行的列值为空了,这样很不友好,很不好看。那么可以借助grouping来进行判断,如果grouping()=1,则显示某些值。
select case when grouping(s.grade)=1 then '总计' else s.grade end 年级,
case when grouping(s.clazz)=1 and grouping(s.grade)=0 then '小计' else s.clazz end 班级,
sum(s.score) 总分,avg(s.score) 平均分
from student s group by rollup(s.grade,s.clazz) ;
这样子的结果看上去好看了很多。
4.grouping_id()
grouping()只能接收一个参数列(必须出现在group by 中),grouping_id()可以出现多个参数列(必须都是出现在group by中的).
case when grouping(s.clazz)=1 and grouping(s.grade)=0 then '小计' else s.clazz end 班级,
--可以用grouping_id来改写----
case when grouping_id(s.grade,s.clazz)=1 then '小计' else s.clazz end 班级, 那么grouping_id(a,b,c...)的值怎样计算呢?其实它返回的是由grouping(x)(x代表任意一列)的值组成的二进制。比如上面的grouping_id(s.grade,s.clazz)其中grouping(s.grade)=0,grouping(s.clazz)=1,则grouping_id(s.grade,s.clazz)=01,换成十进制就是1了。















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









