






root@master:/usr/local/hadoop-2.6.0/sbin# start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-namenode-master.out
worker1: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker1.out
worker6: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker6.out
worker4: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker4.out
worker7: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker7.out
worker3: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker3.out
worker5: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker5.out
worker8: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker8.out
worker2: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker2.out
Starting secondary namenodes [0.0.0.0]
root@master:/usr/local/hadoop-2.6.0/sbin# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-resourcemanager-master.out
worker4: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker4.out
worker7: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker7.out
worker8: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker8.out
worker2: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker2.out
worker3: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker3.out
worker5: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker5.out
worker6: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker6.out
worker1: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker1.out
电影表
^(.*)::(.*)::(.*)$
说明: .* 表示任意字符,()分组
用户表
^(.*)::(.*)::(.*)::(.*)::(.*)$
评分表
^(.*)::(.*)::(.*)::(.*)$
建立电影表
//CREATE TABLE movies(MovieID BigInt, Title String, Genres String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '::';
//LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/movies.dat' INTO TABLE movies;
//CREATE TABLE movies(MovieID BigInt, Title String, Genres String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s') stored as textfile;
//ok
CREATE TABLE movies(MovieID String, Title String, Genres String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s') stored as textfile;
LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/movies.dat' INTO TABLE movies;
//ok
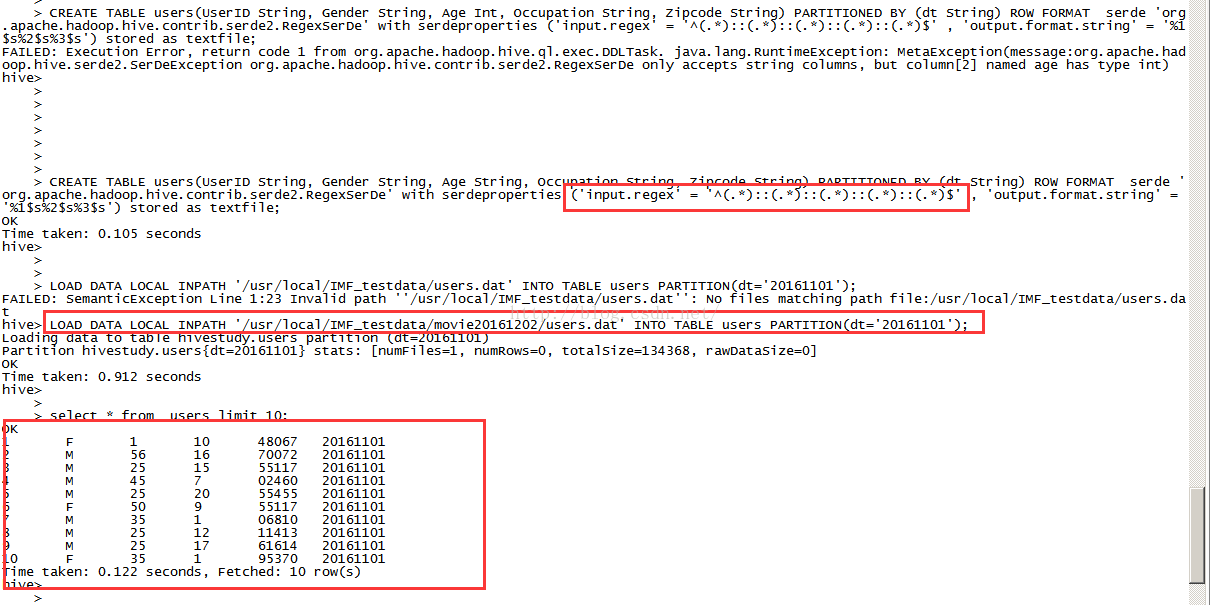
CREATE TABLE users(UserID String, Gender String, Age String, Occupation String, Zipcode String) PARTITIONED BY (dt String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s%4$s%5$s') stored as textfile;
LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/users.dat' INTO TABLE users PARTITION(dt='20161101');
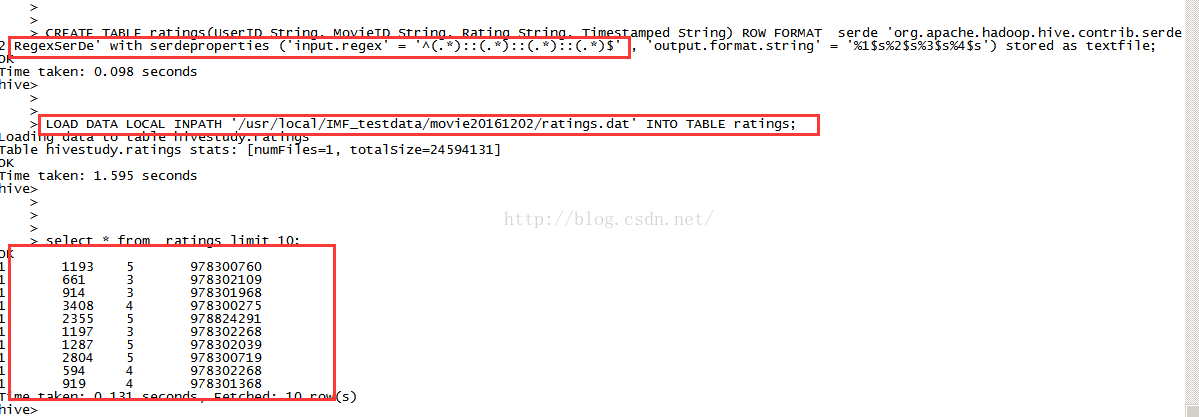
CREATE TABLE ratings(UserID String, MovieID String, Rating String, Timestamped String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s%4$s') stored as textfile;
LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/ratings.dat' INTO TABLE ratings;
SELECT users.UserID, users.Age, users.Gender FROM ratings JOIN users ON (ratings.UserID = users.UserID) WHERE ratings.MovieID = 2916 ;
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-namenode-master.out
worker1: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker1.out
worker6: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker6.out
worker4: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker4.out
worker7: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker7.out
worker3: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker3.out
worker5: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker5.out
worker8: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker8.out
worker2: starting datanode, logging to /usr/local/hadoop-2.6.0/logs/hadoop-root-datanode-worker2.out
Starting secondary namenodes [0.0.0.0]
root@master:/usr/local/hadoop-2.6.0/sbin# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-resourcemanager-master.out
worker4: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker4.out
worker7: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker7.out
worker8: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker8.out
worker2: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker2.out
worker3: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker3.out
worker5: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker5.out
worker6: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker6.out
worker1: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-worker1.out
电影表
^(.*)::(.*)::(.*)$
说明: .* 表示任意字符,()分组
用户表
^(.*)::(.*)::(.*)::(.*)::(.*)$
评分表
^(.*)::(.*)::(.*)::(.*)$
建立电影表
//CREATE TABLE movies(MovieID BigInt, Title String, Genres String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '::';
//LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/movies.dat' INTO TABLE movies;
//CREATE TABLE movies(MovieID BigInt, Title String, Genres String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s') stored as textfile;
//ok
CREATE TABLE movies(MovieID String, Title String, Genres String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s') stored as textfile;
LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/movies.dat' INTO TABLE movies;
//ok
CREATE TABLE users(UserID String, Gender String, Age String, Occupation String, Zipcode String) PARTITIONED BY (dt String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s%4$s%5$s') stored as textfile;
LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/users.dat' INTO TABLE users PARTITION(dt='20161101');
CREATE TABLE ratings(UserID String, MovieID String, Rating String, Timestamped String) ROW FORMAT serde 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' with serdeproperties ('input.regex' = '^(.*)::(.*)::(.*)::(.*)$' , 'output.format.string' = '%1$s%2$s%3$s%4$s') stored as textfile;
LOAD DATA LOCAL INPATH '/usr/local/IMF_testdata/movie20161202/ratings.dat' INTO TABLE ratings;
SELECT users.UserID, users.Age, users.Gender FROM ratings JOIN users ON (ratings.UserID = users.UserID) WHERE ratings.MovieID = 2916 ;
SELECT /*+MAP JOIN(MOVIES)*/ users.UserID, users.Age, users.Gender,movies.title,movies.gendre FROM ratings JOIN users ON (ratings.UserID = users.UserID) JOIN movies ON (rating.movie.id = movies .movid) WHERE ratins.MovieID = 2916 ;















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











