







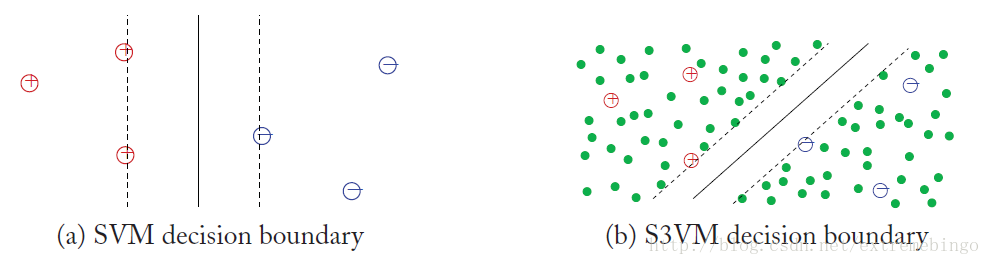
对于Semi-Supervised Support Vector Machines (S3VMs),即半监督支持向量机的直观理解是很简单的,如下图所示。在左图中,所有的数据都是有标签数据,所以可以使用SVM的最大化间隔来确定分离超平面。如果存在大量无标记的点,如右图所示,该如何确定分离超平面呢?如果还是采用左图所示的分离超平面,则分离超平面会将稠密的无标记数据切分成两个不同的类。但是根据图上的数据分布来看,该分离超平面很可能不是最优的,最优的分离超平面为图中实线所示,它就是由S3VMs得到的一个决策边界。上面简单介绍了S3VMs的直观理解,下面从理论层面详细介绍该算法。由于S3VMs是基于SVM的,所以先介绍SVM的部分理论知识。
Support Vector Machines(SVM)
假设存在两个类 y∈{ −1,1} ,决策边界为
{
x|wTx+b=0}
令 f(x)=wTx+b ,则决策边界为 f(x)=0 。对于样本 x 的预测值为
决策边界将整个特征空间划分成两份, f>0 和 f<0 。对于有标记样本 (x,y) ,带符号的距离为
yf(x)/||w||
如果分类正确,则带符号的距离为正,否则为负。对于线性可分的情况,可以将问题转化为下列带约束的优化问题
minw,b s.t. ||w||2yi(wTxi+b)≥1,i=1,...,l
对于线性不可分的情况,至少有一个点不能满足上述约束条件时,引入松弛因子 ξ ,将问题转为下述优化问题
minw,b,ξ s.t. ∑i=1lξi+λ||w||2<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









