







 本文探讨了在机器学习中如何处理混合类型数据,包括数值型、类别型、连续型和文本数据。针对类别型数据,介绍了名义属性和有序属性的转换方法,如标签编码和哑变量编码。对于文本数据,提到了词袋模型、N元词组、TF-IDF以及神经网络表示。最后,强调了混合类型数据预处理的重要性,确保所有数据转化为数值型以便模型使用。
本文探讨了在机器学习中如何处理混合类型数据,包括数值型、类别型、连续型和文本数据。针对类别型数据,介绍了名义属性和有序属性的转换方法,如标签编码和哑变量编码。对于文本数据,提到了词袋模型、N元词组、TF-IDF以及神经网络表示。最后,强调了混合类型数据预处理的重要性,确保所有数据转化为数值型以便模型使用。
在机器学习中,经常会碰到不同类型的数据(numeric, categorical, Continuous and Text data)混合使用的情况,而机器学习算法一般只接受数值型的数据。比如说,虽然神经网络很强大,但是也没办法直接处理类别型的变量,需要经过如one-hot编码的预处理之后才能放进网络去训练。因此,必须对这些数据进行预处理。但是,不同的处理方式,可能对模型的效果产生重要的影响。
Understanding Categorical Data
类别型数据,主要有两种:Nominal(名称)、Ordinal(顺序)
名称型类别数据,在该属性的值之间没有排序的概念,如天气、城市等。

顺序分类特征,它的值的大小是有一定意义的(如衬衫尺寸、鞋子大小、学历高低等)

Feature Engineering on Categorical Data
通常,特征工程中的标准工作流都涉及到将这些类别值经某种形式的转换,转化为数字标签的形式,然后在这些值上应用一些编码方案。
Transforming Nominal Attributes
数据来源:kaggle videogames
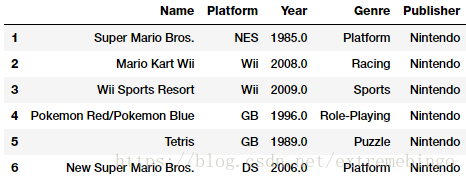
游戏类别字段Genre和Publisher、Platform都是名称属性。
查看游戏类别有多少类
genres = np.unique(vg_df['Genre'])
genres
Output
------
array(['Action', 'Adventure', 'Fighting', 'Misc', 'Platform',
'Puzzle', 'Racing', 'Role-Playing', 'Shooter', 'Simulation',
'Sports& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2950
2950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









