







上一篇博文 HashMap中capacity、loadFactor、threshold、size等概念的解释 讨论了HashMap中的一些基本概念,这篇博文结合具体示例,讨论下HashMap的扩容、树化过程。
注意 , 本文基于JDK1.8

结论
如果在创建HashMap实例时没有给定capacity、loadFactor则默认值分别是16和0.75。
当好多bin被映射到同一个桶时,如果这个桶中bin的数量小于TREEIFY_THRESHOLD当然不会转化成树形结构存储;如果这个桶中bin的数量大于了 TREEIFY_THRESHOLD ,但是capacity小于MIN_TREEIFY_CAPACITY 则依然使用链表结构进行存储,此时会对HashMap进行扩容;如果capacity大于了MIN_TREEIFY_CAPACITY ,则会进行树化。
基础类
package org.fan.learn.map;
import java.util.regex.Pattern;
/**
* Created by fan on 2016/4/7.
*/
public class MapKey {
private static final String REG = "[0-9]+";
private String key;
public MapKey(String key) {
this.key = key;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MapKey mapKey = (MapKey) o;
return !(key != null ? !key.equals(mapKey.key) : mapKey.key != null);
}
@Override
public int hashCode() {
if (key == null)
return 0;
Pattern pattern = Pattern.compile(REG);
if (pattern.matcher(key).matches())
return 1;
else
return 2;
}
@Override
public String toString() {
return key;
}
}
这个MapKey类用于作为HashMap的key的类型,实现了equals、hashCode、toString方法。其中,hashCode方法故意将所有数字字符串key的hash值返回1,其他字符串key的hash值返回2。
package org.fan.learn.map;
import java.util.HashMap;
import java.util.Map;
/**
* Created by fan on 2016/4/7.
*/
public class MainTest {
public static void main(String[] args) {
Map<MapKey,String> map = new HashMap<MapKey, String>();
/*
//第一阶段
for (int i = 0; i < 6; i++) {
map.put(new MapKey(String.valueOf(i)), "A");
}
*/
/*
//第二阶段
for (int i = 0; i < 10; i++) {
map.put(new MapKey(String.valueOf(i)), "A");
}
*/
/*
//第三阶段
for (int i = 0; i < 50; i++) {
map.put(new MapKey(String.valueOf(i)), "A");
}
*/
/*
//第四阶段
map.put(new MapKey("X"), "B");
map.put(new MapKey("Y"), "B");
map.put(new MapKey("Z"), "B");
*/
System.out.println(map);
}
}
下面逐个阶段通过debug,查看map中的数据。
注意,在使用IDEA查看map的数据时,要设置view as Object。如下图所示:
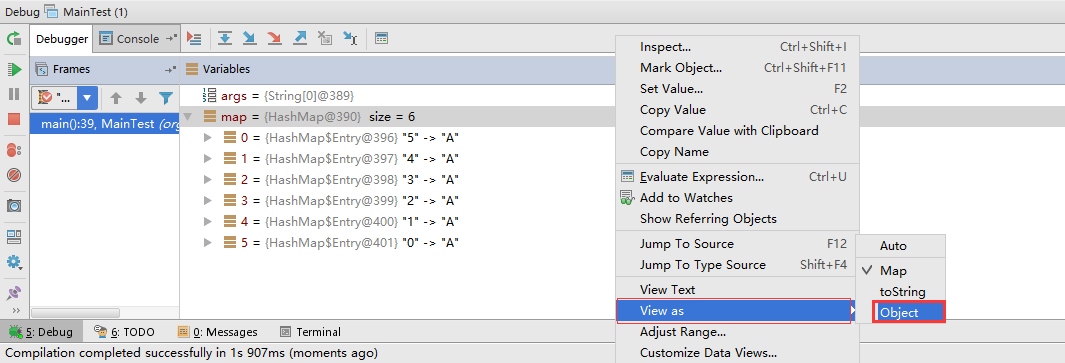
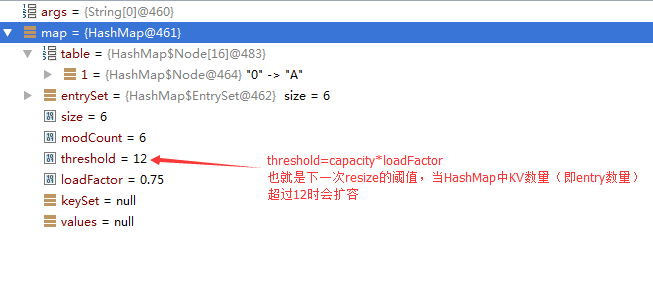
第一阶段
这个时候桶中bin的数量小于TREEIFY_THRESHOLD 。
Debug如下所示:
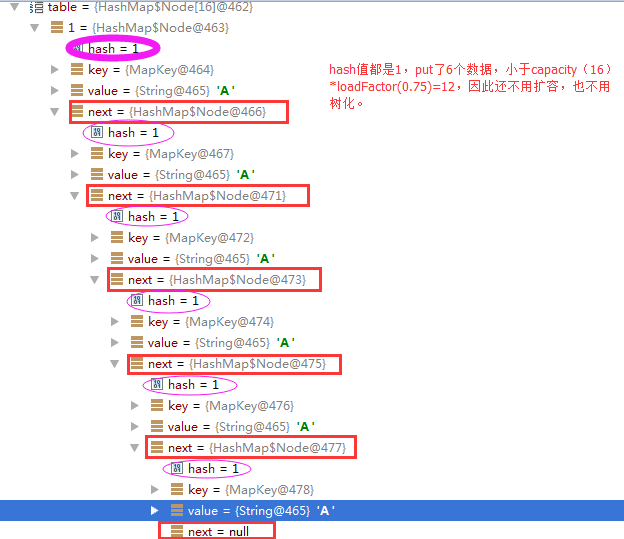
看一下table中具体的存储方式:
第二阶段
这个时候桶中bin的数量大于了TREEIFY_THRESHOLD ,但是capacity不大于MIN_TREEIFY_CAPACITY ,则要扩容,使用链表结构存储。
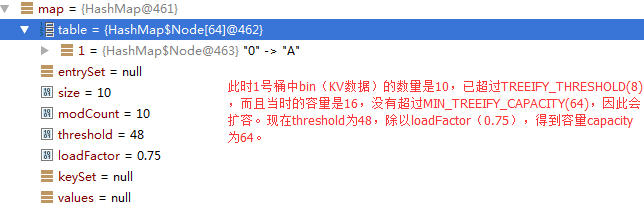
从上图可以看出,1号桶中的存储结构依然是链表。
第三阶段
这个时候桶中bin的数量大于了TREEIFY_THRESHOLD 且 capacity大于了MIN_TREEIFY_CAPACITY ,因此,会树化。
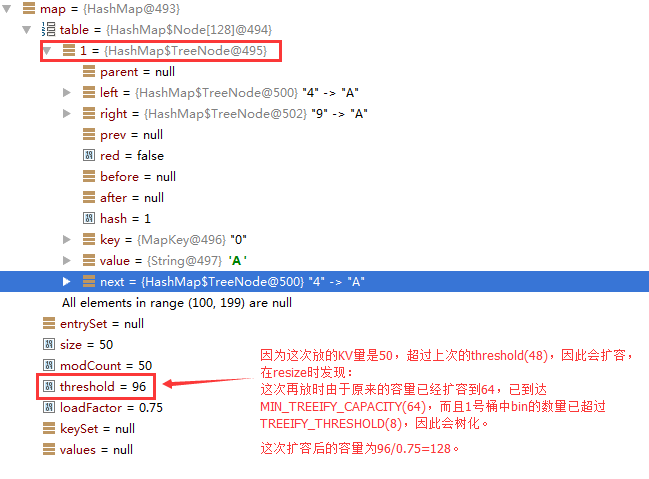
对这个输出map的值,可以看到是乱序的,因为是使用树形结构进行存储的。

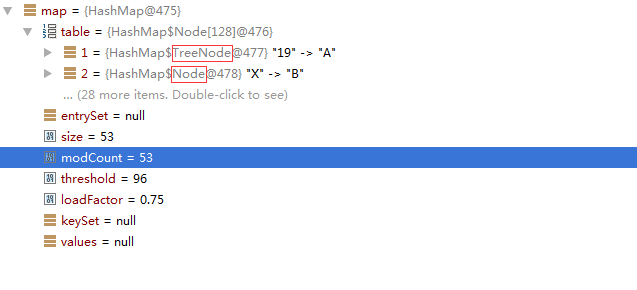
第四阶段
这个阶段主要是测试,如果一个桶采用了树形结构存储,其他桶是不是也采用树形结构存储。结论是,如果其他桶中bin的数量没有超过TREEIFY_THRESHOLD,则用链表存储,如果超过TREEIFY_THRESHOLD ,则用树形存储。
结束语
这篇博文讨论了HashMap的扩容和树化的过程。

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









