







在第一周的末尾,主要讲述了编辑距离的有关知识,主要涉及了最小编辑距离计算和用动态划归的方法进行最小编辑距离的计算。
一、最小编辑距离的定义
两个字符串之间的相似度,主要应用:单词拼写纠正,生物计算,比如说DNA序列的匹配,也同样在口语识别,机器翻译,信息抽取领域有一定的应用。
为了计算最小编辑距离需要采用三种方式,插入,删除,替换

如果每一个操作花费为1,那么这个最小编辑距离为5,如果替换花费算作2的话,那么这个最小编辑距离为8.
如何得到最小编辑距离?
初始状态:我们要转化的单词
操作:插入删除替换
目标:得到我们想要的相似单词
花费:所用的操作有几次
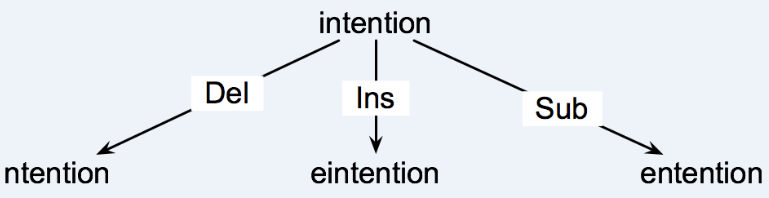
问题出来了,这么多单词,字符串计算起来很困难,另外一个单词可能有很多种形式,采用不同的操作就有不同的目标单词出现
下面是解决方法:
首先定义最小编辑距离:对于两个字符串一个是X长度为n,一个是Y长度为m,定义一个D(i,j)是X[1...i]和Y[1....j]之间的距离,那么X和Y之间的编辑距离就是D(n,m)
如何求得最小编辑距离呢?可以用动态规划的方法,求出D(n,m)的子集D(i,j)递归的求得最小编辑距离。下面附上伪代码:
Initialization
D(i,0) = i
D(0,j) = j
Recurrence Relation:
For each i = 1…M
For each j = 1…N
D(i-1,j) + 1
D(i,j)= min D(i,j-1) + 1
D(i-1,j-1) + 2; if X(i) ≠ Y(j)
0; if X(i) = Y(j)
Termination:
D(N,M) is distance
基本上是这个意思,我自己总是感觉写的不是那么清楚,可能我也没搞很清楚吧,不过写下来之后,对它的理解会更深一点,所以加油吧!















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









