







【1】以下那个不是标准的输入输出通道?
A、std::cin B、std::cout C、std::cerr D、stream
【D】
【2】字符串循环移位(左旋转)问题
问题叙述:
将一个n元一维向量向左旋转i个位置。例如,当n=8且i=3时,”abcdefgh”旋转为”defghabc”,要求时间为O(n),额外存储占用为O(1)。(《编程珠玑》第二章问题B)
分析:
严格来说这并不是一个字符串,因为’\0’是不会移动的。为了叙述方便,可以把它认为是字符串,只是不对’\0’进行操作罢了。
如果不考虑时间要求为O(n),那么可以每次整体左移一位,一共移动i次。只使用O(1)的空间的条件下,一共要进行元素交换O(n*i)次;
如果不考虑空间要求为O(1),那么可以把前i个存入临时数组,剩下的左移i位,再把临时数组里的内容放入后i个位置中。
很可惜,由于两个限制条件,以上两种思路都不满足要求。
算法1:“杂技”代码
为了满足O(1)空间的限制,延续第一个思路,如果每次直接把原向量的一个元素移动到目标向量中它的应该出现新位置上就行了。先把array[0]保存起来,然后把array[i]移动到array[0]上,array[2i]移到array[i]上,直至返回取原先的array[0]。但这需要解决的问题是,如何保证所有元素都被移动过了?数学上的结论是,依次以array[0],…,array[gcd(i,n)-1]为首元进行循环即可,其中gcd(a,b)是a与b的最大公约数。因此算法可写为:
int vec_rotate(char *vec,int rotdist, int length) {
int i,j,k,times;
char t;
times = gcd(rotdist,length);
printf("%d\n",times);
for(i=0;i<times;i++) {
t = vec[i];
j = i;
while(1) {
k = j+ rotdist;
if(k>=length)
k-=length;
if(k==i)
break;
vec[j] = vec[k];
j = k;
}
vec[j]=t;
}
return 0;
}
向量左旋算法1:"杂技"代码算法2:块交换
考虑第二个思路,相当于把向量x分为两部分a和b,左移就是把ab变成ba,其中a包含了前i个元素。假设a比b短,把b分为bl和br,那么需要先把a与br交换得到brbla,再对brbl递归左旋。而a比b长的情况类似,当a与b长度相等时直接两两交换元素就能完成。同时可以看到,每次待交换的向量长度都小于上一次,最终递归结束。
算法3:求逆(推荐)
延续算法2的思路,并假定有一个辅助函数能对向量求逆。这样,分别对a、b求逆得到arbr,再对整体求逆便获得了ba!难怪作者也要称之为“灵光一闪”的算法。可能以前接触过矩阵运算的读者对此很快便能理解,因为(ATBT)T = BA。算法如下:
当n=8且i=3时,”abcdefgh”旋转为”defghabc”
分别求逆cba hgfed
总的求逆defghabc
int vec_rotate_v2(char *vec,int i,int length){
assert((i<=0)||(length<=0))
if(i>length)
i = i%length;
if (i==length) {
printf("i equals n. DO NOTHING.\n");
return 0;
}
reverse(vec,0,i-1);
reverse(vec,i,length-1);
reverse(vec,0,length-1);
return 1;
}
int reverse(char *vec,int first,int last){
char temp;
while(first<last){
temp = vec[first];
vec[first] = vec[last];
vec[last] = temp;
first++;
last--;
}
return 0;
}
向量左旋算法3:求逆扩展:(google面试题)用线性时间和常数附加空间将一篇文章的所有单词倒序。
举个例子:This is a paragraph for test
第一次处理:tset rof hpargarap a si siht
处理后: test for paragraph a is This
如果使用求逆的方式,先把全文整体求逆,再根据空格对每个单词内部求逆,是不是很简单?另外淘宝今年的实习生笔试有道题是类似的,处理的对象规模比这个扩展中的“一篇文章”小不少,当然解法是基本一样的,只不过分隔符不是空格而已,这里就不重述了。
【2】求字符串的连续出现次数最多的子串。
/*
基本算法描述:
给出一个字符串a b c a b c a b c d e .
1.穷举出所有的后缀子串
把字符串用后缀树的形式表现出来如下:
a b c a b c a b c d e .substr[0]
b c a b c a b c d e ….substr[1]
c a b c a b c d e …….substr[2]
a b c a b c d e ……….substr[3]
b c a b c d e ………….substr[4]
c a b c d e ……………substr[5]
a b c d e ……………..substr[6]
b c d e ……………….substr[7]
c d e …………………substr[8]
d e ……………………substr[9]
e ……………………..substr[10]
可以观察到,若存在连续出现的字串,则满足 substr[0].substr(i,j-i) == substr[j].substr(0,j-i),例如上例中的
substr[0].substr(0,3-0) == substr[3].substr(0,3-0)
2.然后进行比较
substrs[0]比substrs[1]多了一个字母,如果说存在连续匹配的字符,那么
substrs[0]的第1个字母要跟substrs[1]首字母匹配,同理
substrs[0]的前2个字母要跟substrs[2]的前2个字母匹配(否则不能叫连续匹配)
substrs[0]的前n个字母要跟substrs[n]的前n个字母匹配.
如果匹配的并记下匹配次数.如此可以求得最长连续匹配子串.
*/
法一:生成后缀列表法
pair<int ,string> fun(const string &str)
{//string str="abcbcbcabc";
vector<string> substrs;
int maxcount=1,count=1;
string substr;
int i,len=str.length();
for(i=0;i<len;i++)
{
substrs.push_back(str.substr(i,len-i)); //把str字符串中的子串按每次把头部减少一个的方式插入到vector向量中
cout<<substrs[i]<<endl;//输出vector中的值 如上图
}
for(i=0;i<len;i++) //先从第一个子串开始直到所有的遍历完所有的子串
{
for(int j=i+1;j<len;j++) //从下一个子串开始 寻找连续出现的子串
{
count=1;
if(substrs[i].substr(0, j-i)==substrs[ j].substr(0, j-i)) //寻找以a开头的子串(对于本题的输入而言)下面依次为b开头的子串,一直到c开头的子串
{
++count;
for(int k=j+(j-i);k<len;k+=j-i)
{
if(substrs[i].substr(0, j-i)==substrs[k].substr(0, j-i)) ++count; //如果有连续一个子串出现就继续遍历vector的下一个子串中的和现在出现相同子串的地方的下一个或几个字符
else break;
}
if(count>maxcount) //maxcount 记录所有遍历中的最大连续子串出现的次数
{
maxcount=count;
substr=substrs[i].substr(0, j-i);
}
}
}
}
return make_pair(maxcount ,substr); //把maxcount 和 找到的子串做成pair<>返回
}int count = 0;
char sub_str[256];
void find_str(char *str)
{
int str_len = strlen(str);
int i, j, k;
int tmp_cnt = 0;
// 从后缀数组的第一个元素,开始遍历,依次进行比较
for (i = 0; i < str_len; i++)
{
// 后缀数组中substrs[i]之后的元素依次与substrs[i]比较
for (j = i+1; j < str_len; j++)
{
int n = j-i; //sub string length
// 如果前j-i个元素相同
// 如果有连续一个子串出现就继续遍历vector的下一个子串中的和现在出现相同子串的地方的下一个或几个字符
if (strncmp(&str[i], &str[j], n) == 0) //compare n-lengths strings
{
tmp_cnt++; //they are equal, so add count
for (k = j+n; k < str_len; k += n) //consecutive checking
{
if (strncmp(&str[i], &str[k], n) == 0)
{
tmp_cnt++;
}
else
break;
}
if (count < tmp_cnt)
{
count = tmp_cnt;
memcpy(sub_str, &str[i], n); //record the sub string
}
}
}
}
}【3】求字符串的最长的重复子序列==最长公共字符串
/*
基本算法描述:
给出一个字符串abababa
1.穷举出所有的后缀子串
对于“banana”,对应的后缀数组为:
a[0]:banana
a[1]:anana
a[2]:nana
a[3]:ana
a[4]:na
a[5]:a
它们是”banana”的所有后缀,这也是“后缀数组”命名原因。
如果某个长字符串在数组c中出现了两次,那么它必然出现在两个不同的后缀中,更准确的说,是两个不同后缀的同一前缀。通过排序可以寻找相同的前缀,排序后的后缀数组为:
a[0]:a
a[1]:ana
a[2]:anana
a[3]:banana
a[4]:na
a[5]:nana
扫描排序后的数组的相邻元素就能得到最长的重复字串,本例为“ana”。
#include <iostream>
using namespace std;
#define MAXCHAR 5000 //最长处理5000个字符
char c[MAXCHAR], *a[MAXCHAR];
//参数的两个字符串长度相等时,该函数便返回这个长度值,从第一个字符开始
int comlen( char *p, char *q )
{
int i = 0;
while( *p && (*p++ == *q++) )
++i;
return i;
}
int pstrcmp( const void *p1, const void *p2 )
{
return strcmp( *(char* const *)p1, *(char* const*)p2 );
}
int main(void)
{
char ch;
int n=0;
int i, temp;
int maxlen=0, maxi=0;
printf("Please input your string:\n");
n = 0;
while( (ch=getchar())!='\n' )
{
a[n] = &c[n];
c[n++] = ch;
}
c[n]='\0'; // 将数组c中的最后一个元素设为空字符,以终止所有字符串
qsort( a, n, sizeof(char*), pstrcmp );
for(i = 0 ; i < n-1 ; ++i )
{
temp=comlen( a[i], a[i+1] );
if( temp>maxlen )
{
maxlen=temp;
maxi=i;
}
}
printf("%.*s\n",maxlen, a[maxi]);
return 0;
}【4】找出一个字符串中不含重复字符的最长子字符串
找出一个字符串中不含重复字符的最长子字符串
(1)采用动态规划,若已知以第i-1位字符为结尾的最长子字符串长度l[i-1],并知道第i-1位字符上一次出现的位置k,就可以求出以第i个字符为结束的最长子字符串(min(l[i-1]+1,i-k)。
遍历字符串就可以求出最长子串,时间复杂度为O(n),代码如下
#include "stdafx.h"
#include
using namespace std;
#define min(a, b) (((a) < (b)) ? (a) : (b))
void Find(const char* str,int len)
{
if(str == NULL)
{
return;
}
int prev[255];
for(int i=0; i<255; i++)
{
prev[i] = -1;
}
int *maxlen = new int[len];
maxlen[0] = 1;
prev[str[0]] = 0;
for(int i=1; i
{
if(prev[str[i]] == -1)
{
maxlen[i] =maxlen[i-1]+1;
}
if(prev[str[i]] != -1)//occur
{
maxlen[i] = min(maxlen[i-1]+1,i-prev[str[i]]);
}
prev[str[i]] = i;
}
int l = 0;
for(int i=0; i
{
if(l
{
l = maxlen[i];
}
}
for(int i=0; i
{
if(maxlen[i] == l)
{
for(int j = i-l+1; j<=i; j++)
{
cout<
}
cout<
}
}
}
int main(void)
{
const char* arr[] ={"ttdjb", "niceday", "helloworld",NULL};
for(int i = 0; arr[i]; ++i)
{
Find(arr[i],strlen(arr[i]));
}
//Find("abcabc",6);
return 0;
}(2)对这个字符串构造后缀数组,在每个后缀数组中,寻找没有重复字符的最长前缀,最长的前缀就是要找的子串。
#include<stdio.h>
//得到字符串最长的无重复的前缀长度
int longestlen(char * p)
{
int hash[256];
int len = 0;
memset(hash,0,sizeof(hash));
while(*p && !hash[*p])
{
hash[*p] = 1;
++len;
++p;
}
return len;
}
//使用后缀数组解法
int max_unique_substring4(char * str)
{
int maxlen = -1;
int begin = 0;
char *a[999];
int n = 0;
while(*str != '\0')
{
a[n++] = str++;
}
int i;
for (i=0; i<n; i++)
{
int temlen = longestlen(a[i]);
if (temlen > maxlen)
{
maxlen = temlen;
begin = i;
}
}
printf("%.*s\n", maxlen, a[begin]);
return maxlen;
}
int main(int argc,char *argv[])
{
char *str = "abcdafeeg";
printf("%d\n",max_unique_substring4(str));
return 0;
}求字符串的“和最大连续子串”
最大子序列是要找出由数组成的一维数组中和最大的连续子序列。比如{5,-3,4,2}的最大子序列就是 {5,-3,4,2},它的和是8,达到最大;而 {5,-6,4,2}的最大子序列是{4,2},它的和是6。你已经看出来了,找最大子序列的方法很简单,只要前i项的和还没有小于0那么子序列就一直向后扩展,否则丢弃之前的子序列开始新的子序列,同时我们要记下各个子序列的和,最后找到和最大的子序列。
- 累加
- 判断是否更新最大值
- 判断是否要重新开始
int maxSubSum(const vector<int> & arr,int &begin,int &end){
int maxSum=0; //记录最大和
int currSum=0; //记录当前和
int newbegin=0; //记录最大和的开始节点
for(int i=0;i<arr.size();++i){
currSum+=arr[i];
if(currSum>maxSum){ //如果比最大和还大,则更新 最大和,起始,终止; 否则,继续向后遍历,以其发现新的和
maxSum=currSum;
begin=newbegin;
end=i;
}
if(currSum<0){ //当前和为负值了,对后边的影响为负影响,那么就要重新计算
currSum=0;
newbegin=i+1;
}
}
return maxSum;
}最长递增子序列
转化为求公共子序列问题
设序列X=< b1,b2,…,bn >是对序列L=< a1,a2,…,an >按递增排好序的序列。那么显然X与L的最长公共子序列即为L的最长递增子序列。这样就把求最长递增子序列的问题转化为求最长公共子序列问题LCS了。动态规划
- 设f(i)表示L中以ai为末元素的最长递增子序列的长度。则有如下的递推方程:
- 这个递推方程的意思是,在求以ai为末元素的最长递增子序列时,找到所有序号在L前面且小于ai的元素aj,即j < i且aj < ai。
- 如果这样的元素存在,那么遍历所有aj,都有一个以aj为末元素的最长递增子序列的长度f(j),把其中最大的f(j)选出来,那么f(i)就等于最大的f(j)加上1,即以ai为末元素的最长递增子序列,等于以使f(j)最大的那个aj为末元素的递增子序列最末再加上ai;
- 如果这样的元素不存在,那么ai自身构成一个长度为1的以ai为末元素的递增子序列。
// [1, -1, 2, -3, 4, -5, 6, -7]
// [1, 1, 2, 1, 3, 1, 4, 1]
// 时间复杂度:O(N*N)
public static void find1(int[] a)
{
int length = a.length;
int[] list = new int[length];// 以当前元素为根的最长递增序列值
List<Integer> result = new ArrayList<Integer>(); // 存储最长递增序列
for (int i = 0; i < length; i++)
{
list[i] = 1;
for (int j = 0; j < i; j++) //找到所有序号在L前面且小于ai的元素aj
{
if (a[j] < a[i] && list[j] + 1 > list[i]) //1、aj<ai 2、对已每一个j都做处理,找到最大的j元素
{
list[i] = list[j] + 1;
if (result.isEmpty()) //结果为空时,将第一个小元素放进去
{
result.add(a[j]);
}
if (!result.contains(a[i])) //进入循环说明找到了前缀,把当前元素也加进去
{
result.add(a[i]);
}
}
}
}
System.out.println("第i个元素时最长递增序列:" + Arrays.toString(list));
// 寻找list中最大值
int max = list[0];
for (int i = 0; i < length; i++)
{
if (list[i] > max)
{
max = list[i];
}
}
System.out.println("最长递增序列长度:" + max);
System.out.println("最长递增序列:" + result);
}
}
//求数组中最长递增子序列
1, -1, 2, -3, 4, -5, 6, -7
第i个元素时最长递增序列:[1, 1, 2, 1, 3, 1, 4, 1]
最长递增序列长度:4
最长递增序列:[1, 2, 3, 4]
多个字符串处理类
记住一个道理,如果涉及多个容器的处理,那么往往先单个容器内排序,可能会取得意想不到的效果
给定两个字符串大集合,如何高效求出交集或者差集
哈希法 O(M+N)
把第一个集合的元素都放入一个hashset中,然后用依次对第二个集合的元素调用contains(),若true表示有重复,输出,false则舍弃双线递增法 O(nlogN)+O(N)
- 分别对两个字符串进行递增排序O(nlogN) 此处也可以去除各自重复的字符
- 转化为“双链表的合并问题” :合并即排序;交集取相等的;差集则每次输出不等情况下的最小值;
两个字符串的最长公共子串 LCS
- 算法1:三重循环法【类似与 单串的最多连续子串 的求法】 O(M*N*N)
- 外层循环
- 内层循环
- 相等则继续往里边走,最终更新max
//求两个字符串的最大公共字符子串,如"abccade","dgcadde"的最大子串为"cad"
int GetCommon(char *s1, char *s2, char **r)
{
int len1 = strlen(s1);
int len2 = strlen(s2);
int maxlen = 0;
int i = 0, j = 0;
for (i = 0; i < len1; i++)//最外层循环,字符串1的不同开始位置
{
for(j = 0; j < len2; j++)//内存循环,字符串2的不同开始位置
{
if (s1[i] == s2[j])//相等的话就继续匹配
{
int as = i, bs = j, count = 1;
while((as + 1 < len1 )&& (bs + 1 < len2) && (s1[++as] ==s2[++bs]))//匹配
count++;
if (count > maxlen)//更新
{
maxlen = count;
*r = s1 + i;
}
}
}
}
return maxlen;
}//求两字符串的最长公共子串
#include<stdio.h>
#include<string.h>
char * maxsamesubstring(char *s1,char *s2)
{
int i,j,len,maxlen,index,maxindex;
maxlen=0; //初始化最长公共子串的长度
maxindex=0; //初始化最长公共子串的位置
len=0; //当前公共子串的长度
for(i=0;s1[i]!='\0';i++)
for(j=0;s2[j]!='\0';j++)
if(s1[i+len]==s2[j])
{
if(!len)
{
index=j; //记下公共子串的起始位置
}
len++;
}
else if(len)
{
if(maxlen<len) //经过一次扫描找到了最长公共子串
{
maxlen=len;
maxindex=index;
}
len=0; //进行下一次的扫描
}
char *p=new char[maxlen+1];
strncpy(p,s2+maxindex,maxlen); //把最长公共字符串复制到p所指的空间
p[maxlen+1]='\0'; //置串结束标志
return p;
}- 动态规划
找两个字符串的最长公共子串,这个子串要求在原字符串中是连续的。其实这又是一个序贯决策问题,可以用动态规划来求解。我们采用一个二维矩阵来记录中间的结果。这个二维矩阵怎么构造呢?直接举个例子吧:”caba”和”bab”(当然我们现在一眼就可以看出来最长公共子串是”ba”或”ab”):第一个字符串的的i个字符等于第二个字符串的第j个字符
A[0]!=B[0]!=B[1]!=B[2]
A[1]!=B[0]==B[1]!=B[2]
b a b
c 0 0 0
a 0 1 0
b 1 0 1
a 0 1 0
我们看矩阵的斜对角线最长的那个就能找出最长公共子串。
不过在二维矩阵上找最长的由1组成的斜对角线也是件麻烦费时的事,下面改进:当要在矩阵是填1时让它等于其左上角元素加1。
b a b
c 0 0 0
a 0 1 0
b 1 0 2
a 0 2 0
这样矩阵中的最大元素就是 最长公共子串的长度。
在构造这个二维矩阵的过程中由于得出矩阵的某一行后其上一行就没用了,所以实际上在程序中可以用一维数组来代替这个矩阵。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//求公共子串(连续),注意跟求公共子序列有区别
int lcstr( const char* s1,const char* s2)
{
//clen保存公共子串的最大长度,s1_Mindex保存 s1公共子串的最后一个元素的位置
int len1,len2,i,k,maxLen=1,s1_Mindex=0;
int **c;
if(s1==NULL || s2==NULL) return -1;
len1=strlen(s1);
len2=strlen(s2);
if(len1< 1 || len2 < 1) return -1;
int a[len1][len2]={0}; //构建二维矩阵c[i][j],并全部初始化为0
/**********init end!*************/
for(i=0;i<len1;i++)
{
for(k=0;k<len2;k++)
{
if (s1[i] == s2[k]) //相等则执行+1操作将对应矩阵位置置1+对角线前一个
{
if(i==0 || k==0) //第一行或者列,对角线前边没东西
c[i][k]=1; //相等则直接置1
else
c[i][k] = c[i - 1][k - 1] + 1;
if (maxcLen < c[i][k]) //发现比当前max还要长,就更新max
{
maxcLen = c[i][k];
s1_Mindex = i; //记录终止位置(起始终止都可以,找到对角线上的0,就是分隔符)
}
}
}
}
//*************//
// printf the one of lcs 只是其中一条
//如果存在多条在上边赋值过程那里修改:用容器装终止位置
//如果相等maxcLen == c[i][k],则终止位置进入一个resultlist;
//如果需要更新maxcLen < c[i][k],则resultlist清空,并add(i)
for(i=0;i<maxcLen;i++)
{
printf("%c",*(s1+s1_Mindex-cLen+1+i));
}
/*****free array*************/
for(i=0;i<len1;i++)
free(c[i]);
free(c);
return cLen;
}
int main(void) {
char a[]="abcgooglecba";
char b[]="cbagoogleABVC";
printf("\nlcstr = %d\n",lcstr(a,b));
return 0; 两个字符串的最长公共子序列
下面我们同样要构建一个矩阵来存储动态规划过程中子问题的解。这个矩阵中的每个数字代表了该行和该列之前的LCS的长度。与上面刚刚分析出的状态转移议程相对应,矩阵中每个格子里的数字应该这么填,它等于以下3项的最大值:
(1)上面一个格子里的数字
(2)左边一个格子里的数字
(3)左上角那个格子里的数字(如果 C1不等于C2); 左上角那个格子里的数字+1( 如果C1等于C2)
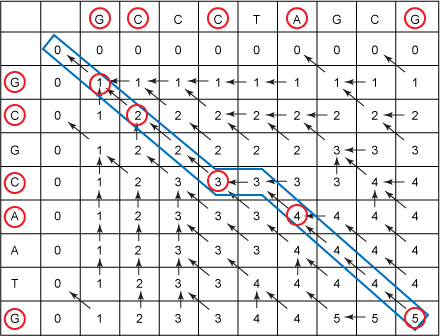
举个例子:
G C T A
0 0 0 0 0
G 0 1 1 1 1
B 0 1 1 1 1
T 0 1 1 2 2
A 0 1 1 2 3
填写最后一个数字时,它应该是下面三个的最大者:
(1)上边的数字2
(2)左边的数字2
(3)左上角的数字2+1=3,因为此时C1==C2
所以最终结果是3。
在填写过程中我们还是记录下当前单元格的数字来自于哪个单元格,以方便最后我们回溯找出最长公共子串。有时候左上、左、上三者中有多个同时达到最大,那么任取其中之一,但是在整个过程中你必须遵循固定的优先标准。在我的代码中优先级别是左上>左>上。
using System;
namespace ConsoleApplication2
{
public class Program
{
static int[,] martix;
static string str1 = "cnblogs";
static string str2 = "belong";
static void Main(string[] args)
{
//注意此处。构建了一个大一圈:多一行一列的矩阵,然后从1下标开始
martix = new int[str1.Length + 1, str2.Length + 1];
// flag = new string[str1.Length + 1, str2.Length + 1];
LCS(str1, str2);
//注意此处,之所以不记录最大值,是由于只要拿出矩阵最后一个位置的数字即可
Console.WriteLine("当前最大公共子序列的长度为:{0}", martix[str1.Length, str2.Length]);
Console.Read();
}
static void LCS(string str1, string str2)
{
//初始化边界,过滤掉0的情况
for (int i = 0; i <= str1.Length; i++) //构建了一个大一圈:多一行一列的矩阵,然后从1下标开始
martix[i, 0] = 0;
for (int j = 0; j <= str2.Length; j++)
martix[0, j] = 0;
//填充矩阵
for (int i = 1; i <= str1.Length; i++)
{
for (int j = 1; j <= str2.Length; j++)
{
//相等的情况
if (str1[i - 1] == str2[j - 1])
{
martix[i, j] = martix[i - 1, j - 1] + 1;
// flag[i, j] = "left_up";
}
else
{
//比较“左边”和“上边“,根据其max来填充
if (martix[i - 1, j] >= martix[i, j - 1])
martix[i, j] = martix[i - 1, j];
// flag[i, j] = "left";
else
martix[i, j] = martix[i, j - 1];
// flag[i, j] = "up";
}
}
}
}
}
}//打印子序列
static void SubSequence(int i, int j)
{
if (i == 0 || j == 0)
return;
if (flag[i, j] == "left_up")
{
Console.WriteLine("{0}: 当前坐标:({1},{2})", str2[j - 1], i - 1, j - 1);
//左前方
SubSequence(i - 1, j - 1);
}
else
{
if (flag[i, j] == "up")
{
SubSequence(i, j - 1);
}
else
{
SubSequence(i - 1, j);
}
}
}














 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









