







1-SQL基本功能
SQL语言集数据查询(Data Query)、数据操纵(Data Manipulation)、数据定义(Data Definition)和数据控制(Data Control)功能于一体,充分体现了关系数据语言的特点和优点。
1.数据定义功能
通过DDL(Data Definition Language)语言来实现。可用来支持定义或建立数据库对象(如表、索引、序列、视图等),定义关系数据库的模式、外模式、内模式。常用DDL语句为不同形式的CREATE、ALTER、 DROP命令。
2.数据操纵功能
数据操纵功能通过DML(Data Manipulation Language)语言来实现,DML包括数据查询和数据更新两种语句,数据查询指对数据库中的数据进行查询、统计、排序、分组、检索等操作.数据更新指对数据的更新、删除、修改等操作。
3.数据控制功能
数据库的数据控制功能指数据的安全性和完整性。通过数据控制语句DCL(Data Control Language)来实现。
2-SQL的动词
| 功能 | 动词 |
|---|---|
| 数据定义 | CREATE、 DROP、 ALTER |
| 数据查询 | SELECT |
| 数据操纵 | INSERT 、UPDATE 、DELETE |
| 数据控制 | GRANT 、REVOKE |
2-SQL之数据定义语言:create-drop-alter
| 级别 | 创建 | 删除 | 修改 |
|---|---|---|---|
| 模式 | create schema | drop schema | |
| 表 | create table | drop table | alter table |
| 视图 | create view | drop view | |
| 索引 | create index | drop index |
2-1 模式
- 创建 :create schema <模式名> authorization <用户名>
如果没有模式名,那么模式名隐含为用户名
示例:定义一个学生-课程模式s-t
create schema "s-t" authorization wang- 删除:Drop Schema <模式名> cascade|restric
CASCADE:删除模式同时删除所有数据对象
RESTRICT:已定义下属数据对象,则拒绝删除模式
Drop Schema "s-t" cascade2-2 表
- 创建:Create table <表名>(<列名>[<数据类型>[列级完整性约束条件]],···)[表级完整性约束条件]
列级完整性约束条件:primary key ; unique
表级完整性约束条件:foreign key <列名> references 表名(列明)
create table s
(sno char(4) primary key, //学号主键
sname varchar(8) unique, //姓名唯一
sage smallint,
sex char(2),
sdeptno char(2),
//primay key(sno),
foreign key sdeptno references Sdept(ID)//定义外键
);- 修改:
Alter table <表名>
[add<列名><数据类型>[完整性约束]
[drop <完整性约束名>]
[drop <列名>]
[alter column <列名><数据类型>[完整性约束]]
Alter table s add sex char(2);- 删除:Drop Table <表名> cascade|restric
CASCADE:删除模式同时删除所有数据对象
RESTRICT:当前表不能有视图,不能有索引,不能被约束引用,不能有触发器
2-3 索引
- 创建 :create [unique][cluster] index <索引名> on <表名>(<列名>[顺序]…)[其它参数]
ASC:升序
DESC:降序
Unique:唯一性索引,不允许两个元组在给定索引中有相同的值。
Cluster:聚簇索引,索引项的顺序与表中记录的物理顺序一致。
例:在表s的sno上建立一个按升序排列的唯一性索引xsno。
create unique index xsno on s (sno) asc; - 删除:drop index indexName
//删除student表上的stusname索引
Drop inde stusname2-4 视图
- 创建:create view <视图名> ([<列名> [,<列名>]…]) as
create view css(sno,sname,sage,sex,sdept)
as (select *
from s
where sdept=‘cs’)- 删除:drop view <视图名>
drop view css;3-SQL之数据查询语言:select
SQL语句执行顺序:
1. FROM子句组装来自不同数据源的数据
2. WHERE子句基于指定的条件对记录进行筛选
3. GROUP BY子句将数据划分为多个分组
4. 使用聚集函数进行计算
5. 使用HAVING子句筛选分组
6. 计算所有的表达式
7. 使用ORDER BY对结果集进行排序
3-1 去重-distinct
3-2 常用的查询条件
SELECT 列名1,列名2 FROM 表名 WHERE 列名1 运算符 值
| 运算符 | 描述 | 示例 | 备注 |
|---|---|---|---|
| = | 等于 | ||
| <> | 不等于 | ||
| > | 大于 | ||
| < | 小于 | ||
| > = | 大于等于 | ||
| <= | 小于等于 | ||
| Between And | 在某个范围内 | SELECT ID,Name,Age FROM Students WHERE Age BETWEEN 18 AND 20 | |
| LIKE | 搜索某种模式 | SELECT ID,Name FROM Students WHERE Name LIKE ‘张%’ | %替代一个或多个字符;_仅替代一个字符;[charlist]字符列中的任何单一字符 |
| In-Not in | 确定集合 | SELECT ID,Name FROM Students WHERE Age IN (18,19,20) | |
| And、Or、Not | 多重条件 | SELECT ID,Name FROM Students WHERE Name NOT LIKE ‘张%’ | |
| Is Null、IsNotNull | 判断空置 | ||
| As | 指定别名 | SELECT ID AS StudentID,Name AS StudentName FROM Students |
3-3 Order By
| 标识 | 含义 | 备注 |
|---|---|---|
| ASC | 升序 | 默认 |
| DESC | 倒序 |
SELECT ID,Name,Score FROM Students ORDER BY Score DESC,ID ASC3-4 聚合函数
| 运算符 | 描述 | 示例 | 备注 |
|---|---|---|---|
| Max、Min | 求一列的最大过最小值 | SELECT MAX(Score) FROM Students | null不计算在内 |
| Sum、Avg | 求和、求平均 | SELECT AVG(Age) AS AgeAverage FROM Students | |
| count | 统计个数 | SELECT COUNT(DISTINCT Age) FROM Students统计年龄层—————-SELECT COUNT(Age) FROM Students统计有年龄信息的学生个数 |
3-5 group by
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
1)查询男女生分布,上面已经给了答案。
SELECT Sex,COUNT(ID) FROM Students GROUP BY Sex2) 查询学生的城市分布情况
SELECT City,COUNT(ID) FROM Students GROUP BY City3)学生的平均成绩,查询结果包括:学生ID,平均成绩
SELECT StudentID,AVG(Score) FROM SC GROUP BY StudentID4)删除学生信息中重复记录
根据列进行分组,如果全部列相同才定义为重复,则就需要GROUP BY所有字段。否则可按指定字段进行处理。
DELETE FROM Students WHERE ID NOT IN (SELECT MAX(ID) FROM Students GROUP BY ID,Name,Age,Sex,City,MajorID)3-6 HAVING针对组的筛选
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value查询平均成绩大于等于60,且学生ID等于1的学生的ID及平均成绩。
SELECT StudentID,AVG(Score) FROM SC
WHERE StudentID='1'
GROUP BY StudentID
HAVING AVG(Score)>=603-7 Case语句
查询学习信息,如果Sex为0则显示为男,如果为1显示为女,其他显示为其他。
SELECT ID, Name, CASE Sex WHEN '0' THEN '男' WHEN '1' THEN '女' ELSE '其他' END AS Sex
FROM Students
查询学生信息,根据年龄统计是否成年,大于等于18为成年,小于18为未成年
SELECT ID, Name, CASE WHEN Age>=18 THEN '成年' ELSE '未成年'END AS 是否成年
FROM Students3-8 多表查询
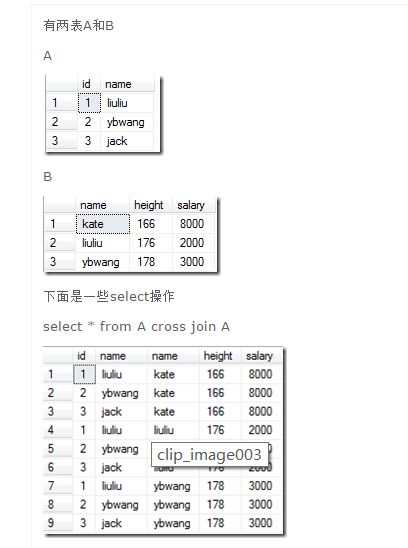
select * from A join B on A.name = B.name就是对笛卡尔积,也即上边的cross join的结果进行进一步筛选,选出满足A.name=B.name的行。
只有两行符合条件
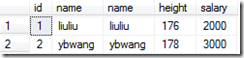
左连接:select * from A left join B on A.name = B.name
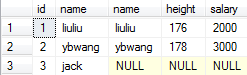
右连接:select * from A right join B on A.name = B.name
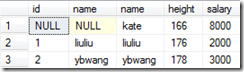
全链接:select * from A full join B on A.name = B.name
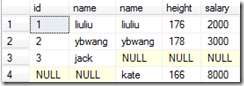
3-9 嵌套查询
- in子查询
- 连接符>=<子查询
- exists查询
查询所有选修了1号课程的学生姓名。
select sname from student
where exists (
select *
from sc
where sno=student.sno and cno='1'
);
//使用存在量词exists后,若内层查询结果非空,则外层的where子句返回真值,否则返回假值。由于exists引出的子查询,其目标列表达式通常用*,因为带exists的子查询只返回真值或假值,给出列名无实际意义。
//首先取外层查询中(student)表的第一个元组,根据它与内层查询相关的属性值(sno值)处理内层查询,若where子句返回值为真,则取外层查询中该元组的sname放入结果表;然后再取(student)表的下一个元组;重复这一过程,直至外层(student)表全部检查完为止。4-SQL之数据操作语言:insert-delete-update
4-1 插入 insert
insert into <表名>[<列名>[,<列名>]…]
values (<常量>[,<常量>]…)
insert into sc (sno,cno) values (‘s2’,’c2’); 4-2 删除delete
delete
from <基表>
where <逻辑条件>
delete
from s
where sname=‘王林’;4-3 更新操作update
update <表名>
set <列名>=表达式[,<列名>=表达式]…
where <逻辑条件>
update s
set sdept=‘cs’
where sno=‘s16’;5-SQL之数据空置语言:grant,revoke
5-1 授权grant
Grant <权限> on 表名[(列名)] to 用户 With grant option
GRANT <权限> ON <数据对象> FROM <数据库用户>
grant select,update(sname)
on table sc
to u2
with grant option
//create role r1
grant select,update(sname)
on table sc
to r1;
grant r1
to u2;5-2 回收revoke
revoke <权限> on 表名[(列名)] from 用户 With grant option cascade|restric















 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









