






 本文详细介绍了在Django框架中如何实现多对多关系,包括创建模型、实例化对象、关联对象、查询关联关系、反向查询、删除关系等操作,并通过代码示例进行演示。
本文详细介绍了在Django框架中如何实现多对多关系,包括创建模型、实例化对象、关联对象、查询关联关系、反向查询、删除关系等操作,并通过代码示例进行演示。
要定义多对多关系,使用ManyToManyField字。 (注:django版本1.4)
本例中,一篇文章可以被很多出版社发表,而一个出版社也会发表多个文章。
from django.db import models
class Publication(models.Model):
title = models.CharField(max_length=30)
# On Python 3: def __str__(self):
def __unicode__(self):
return self.title
class Meta:
ordering = ('title',)
class Article(models.Model):
headline = models.CharField(max_length=100)
publications = models.ManyToManyField(Publication)
# On Python 3: def __str__(self):
def __unicode__(self):
return self.headline
class Meta:
ordering = ('headline',)
创建两个出版社:
>>> p1 = Publication(title='The Python Journal')
>>> p1.save()
>>> p2 = Publication(title='Science News')
>>> p2.save()
>>> p3 = Publication(title='Science Weekly')
>>> p3.save()
>>> a1 = Article(headline='Django lets you build Web apps easily')只有把它保存了,才能把它和出版社关联在一起。否则会出错如下:
>>> a1.publications.add(p1)
Traceback (most recent call last):
...
ValueError: 'Article' instance needs to have a primary key value before a many-to-many relationship can be used.保存。
>>> a1.save()
关联文章和出版社。
建立第2篇文章,让它在两个出版社中出现。
>>> a2 = Article(headline='NASA uses Python')
>>> a2.save()
>>> a2.publications.add(p1, p2)
>>> a2.publications.add(p3)
再次添加也OK
>>> a2.publications.add(p3)
如果添加错误类型的对象会发生 TypeError:
>>> a2.publications.add(a1)
Traceback (most recent call last):
...
TypeError: 'Publication' instance expected
使用create()一次创建并把出版社指派到一篇文章:
>>> new_publication = a2.publications.create(title='Highlights for Children')
>>> a1.publications.all()
[<Publication: The Python Journal>]
>>> a2.publications.all()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]出版社对象也有权访问与它们相关联的文章对象:
>>> p2.article_set.all()
[<Article: NASA uses Python>]
>>> p1.article_set.all()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Publication.objects.get(id=4).article_set.all()
[<Article: NASA uses Python>]
使用 lookups across relationships 来query多对多关系:
>>> Article.objects.filter(publications__id__exact=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__pk=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications=p1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__title__startswith="Science")
[<Article: NASA uses Python>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__title__startswith="Science").distinct()count()函数与distinct()表现相同:
>>> Article.objects.filter(publications__title__startswith="Science").count()
2
>>> Article.objects.filter(publications__title__startswith="Science").distinct().count()
1
>>> Article.objects.filter(publications__in=[1,2]).distinct()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__in=[p1,p2]).distinct()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
反向 m2m查询也被支持(如,开始的表格没有 ManyToManyField):
>>> Publication.objects.filter(id__exact=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(pk=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__headline__startswith="NASA")
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]
>>> Publication.objects.filter(article__id__exact=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__pk=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article=a1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__in=[1,2]).distinct()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>>> Publication.objects.filter(article__in=[a1,a2]).distinct()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication>, <Publication: Science Weekly>, <Publication: The Python Journal>]
也可以按自己预期的那样排除一个相关的项目(尽管使用的SQL语句有一点复杂):
>>> Article.objects.exclude(publications=p2)
[<Article: Django lets you build Web apps easily>]如果我们删除一个出版社,那么它的文章就不能够被访问:
>>> p1.delete()
>>> Publication.objects.all()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>]
>>> a1 = Article.objects.get(pk=1)
>>> a1.publications.all()
[]
>>> a2.delete()
>>> Article.objects.all()
[<Article: Django lets you build Web apps easily>]
>>> p2.article_set.all()
[]
经由m2m的另一方法来添加:
>>> a4 = Article(headline='NASA finds intelligent life on Earth')
>>> a4.save()
>>> p2.article_set.add(a4)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>]
>>> a4.publications.all()
[<Publication: Science News>]
经由关键字的另一方法添加:
>>> new_article = p2.article_set.create(headline='Oxygen-free diet works wonders')
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]
>>> a5 = p2.article_set.all()[1]
>>> a5.publications.all()
[<Publication: Science News>]
从文章中移除出版社:
>>> a4.publications.remove(p2)
>>> p2.article_set.all()
[<Article: Oxygen-free diet works wonders>]
>>> a4.publications.all()
[]
从出版社中移除文章:
>>> p2.article_set.remove(a5)
>>> p2.article_set.all()
[]
>>> a5.publications.all()
[]
关系集合可以被分配。分配时所有已经存在的集合成员会被清除:
>>> a4.publications.all()
[<Publication: Science News>]
>>> a4.publications = [p3]
>>> a4.publications.all()
[<Publication: Science Weekly>]
关系集合可以清除:
>>> p2.article_set.clear()
>>> p2.article_set.all()
[]
而且你也可以从另一端清除(注:关系的另一端):
>>> p2.article_set.add(a4, a5)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]
>>> a4.publications.all()
[<Publication: Science News>, <Publication: Science Weekly>]
>>> a4.publications.clear()
>>> a4.publications.all()
[]
>>> p2.article_set.all()
[<Article: Oxygen-free diet works wonders>]
重建我们删除过的文章和出版社:
>>> p1 = Publication(title='The Python Journal')
>>> p1.save()
>>> a2 = Article(headline='NASA uses Python')
>>> a2.save()
>>> a2.publications.add(p1, p2, p3)批量删除一些出版社-引用的被删出版社应当去掉:
>>> Publication.objects.filter(title__startswith='Science').delete()
>>> Publication.objects.all()
>>> Article.objects.all()
[<Article: Django lets you build Web apps easily>, <Article: NASA finds intelligent life on Earth>, <Article: NASA uses Python>,<Article: Oxygen-free diet works wonders>]
>>> a2.publications.all()
[<Publication: The Python Journal>]
>>> q = Article.objects.filter(headline__startswith='Django')
>>> print(q)
[<Article: Django lets you build Web apps easily>]
>>> q.delete()
在delete()以后,QuerySet缓存需要清理,而且引用对象应该被去掉:
>>> print(q)
[]
>>> p1.article_set.all()
[<Article: NASA uses Python>]
除了调用clear()之外,可以赋值一个空的集合:
>>> p1.article_set = []
>>> p1.article_set.all()
[]
>>> a2.publications = [p1, new_publication]
>>> a2.publications.all()
[<Publication: Highlights for Children>, <Publication: The Python Journal>]
>>> a2.publications = []
>>> a2.publications.all()
[]
附:
The Django Book中的1个例子。
按部就班照着它做,没看到它写如何添加Book。
model.py类
#coding=utf-8
from django.db import models
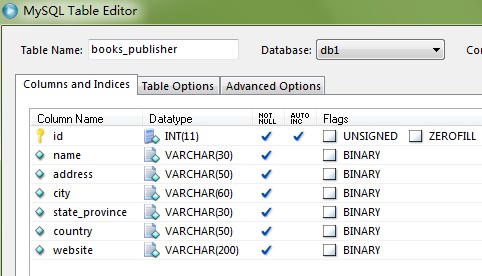
class Publisher(models.Model):
name=models.CharField(max_length=30)
address=models.CharField(max_length=50)
city=models.CharField(max_length=60)
state_province=models.CharField(max_length=30)
country=models.CharField(max_length=50)
website=models.URLField()
def __unicode__(self):
return self.name
class Meta:
ordering=['name']
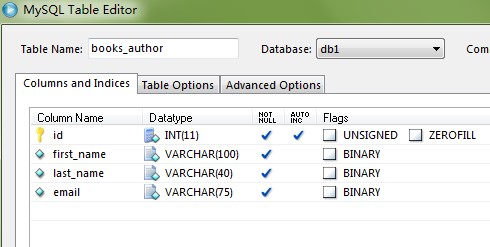
class Author(models.Model):
first_name=models.CharField(max_length=100)
last_name=models.CharField(max_length=40)
email=models.EmailField(max_length=40,verbose_name='email_address',blank=True)
def __unicode__(self):
return u'%s %s' % (self.first_name,self.last_name)
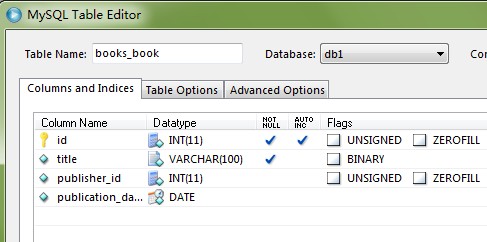
class Book(models.Model):
title=models.CharField(max_length=100)
authors=models.ManyToManyField(Author)
publisher=models.ForeignKey(Publisher)
publication_date=models.DateField()
def __unicode__(self):
return

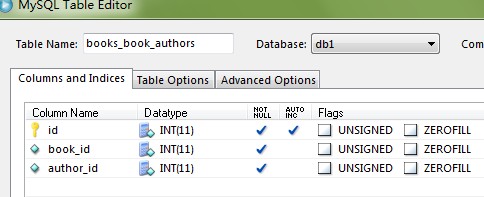
表中字段为:
setting.py中installed app要加上mysite.books。
cmd进入命令行,在站点下运行命令:I:\mysite>manage.py shell>>>from mysite.books.models import Publisher,Author,Book
>>>import datetime
>>>b1=Book(title='Beginer osf Labview',publisher=Publisher.objects.all()[1],publication_date=datetime.datetime.strptime('20130726','%Y%m%d'))
>>>b1.save() #保存一下,得到一个book的ID
>>>b1.authors.add(Author.objects.all()[1])
>>>b1<Book: Beginer osf Labview>>>> Book.objects.all()[<Book: Learn C>, <Book: Learn Python>, <Book: Beginer osf Labview>]>>>b2=Book()
>>>b2.save()
IntegrityError: (1048, "Column 'publisher_id' cannot be null")
在Book类中可以看到Publisher是外键,在表中会有一个publisher_id不允许为空。
而对于ManyToMany字段,Book中的Author只能使用add方法来添加,添加之前需要通过save()取得一个book的id。
Add以后,不用再次save,也可以保存到数据库?

















 2480
2480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









