









1、Spring Ioc容器实现原理
Spring Ioc容器实现分为三个步骤:分别是Resource的定位,由ResourceLoader通过输出Reource接口来完成;BeanDefinition的载入,这个过程是把用户定义好的bean载入到IOC的内部数据结构表示形式,这个过程就是将你定义的关于bean的信息(例如类名,是否单例,依赖关系,是否懒加载等等信息)存储到一个POJO的过程;向IOC容器注册这些BeanDefinition,它的完成是通过BeanDefinitionRegistry来完成的。
IOC容器接口类设计图如图1:
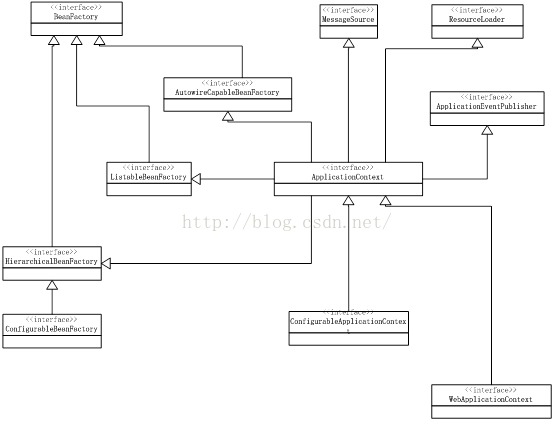
图1、SPRING IOC容器UML图
从代码层面上分析Spring IOC容器以BeanFactory和ApplicationContext为主线演变发展,BeanFactory是一个简单工厂的设计接口,所有的Bean的产生都是从BeanFactory得来的。所以可以初步看做BeanFacotey是spring IOC容器的一个规范接口类,它提供了一个Bean获取最基本的操作接口,在它的基础上扩展有各类BeanFactory的实现,其中ListableBeanFacotry的一个实现为DefaultListableBeanFacotry就是一个spring容器的基本实现。在这个基本容器的实现基础上演变出了一个更为高级的容器接口就是ApplicationContext,从继承关系可以看出ApplicationContext是可以从双亲获取bean的一个容器,同时他还扩展了messageResource可以作为国际化的资源获取,以及对资源的多方式定位及加载,最后还有一个事件发布监听功能。
1.1、Resource的定位
Spring IOC的资源定位方式有很多,但是最终都是通过ResourceLoader来定位的。同时读取配置资源都是通过BeanDefinitionReader来读取的,通过一个编程式的方式来大体展示下资源定位的过程。

通过以上编程式阐述,可以对照类比一下,第一步ClassPathResource的获取过程就是ResourceLoader所负责的工作,而第二步之前已经讲到他就是IOC的Bean容器;第三步和第四步代码就是一个reader去读取这个资源文件,这个工作就是BeanDefinitionReader去完成的。有了以上大体轮廓影响之后就可以进入代码对其实现过程进行详细分析。以FileSystemXmlApplicationContext为例解析。
首先看下FileSystemXmlApplicationContext的类继承关系,如图2所示:
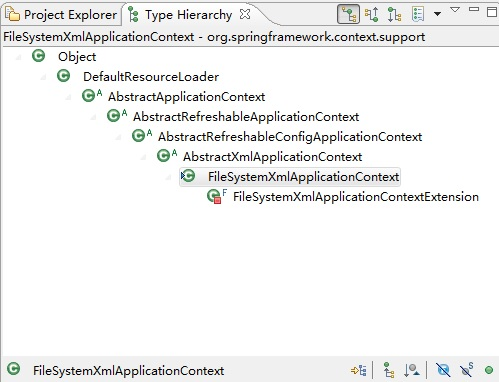
图2、FileSystemXmlApplicationContext的类继承关系
接下来看下这个类的构造函数,如下:
public FileSystemXmlApplicationContext(String[]configLocations, boolean refresh, ApplicationContext parent) throwsBeansException {
super(parent);
setConfigLocations(configLocations);
if(refresh) {
refresh();
}
}首先设置双亲的资源,这个就是继承了HierarchicalBeanFactory的特性,设置资源的路径,之后进入IOC容器初始化的主要过程就是refresh().这个refresh过程中关于资源定位部分的时序图如下图3所示:
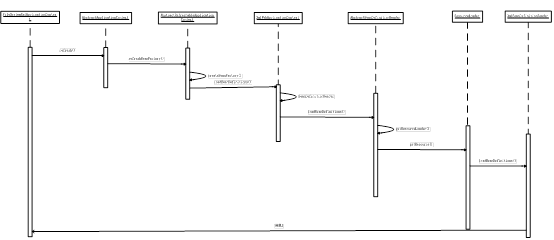
图3、spring IOC资源定位时序图
从时序图可以看出资源的加载和解析都是如编程式方式一样的步骤。下面可以看下资源定位ResourceLoader是如何工作的?
public Resource getResource(Stringlocation) {
Assert.notNull(location,"Location must not be null");
if(location.startsWith(CLASSPATH_URL_PREFIX)) {
return
newClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()),getClassLoader());
}
else{
try{
//Try to parse the location as a URL...
URLurl = new URL(location);
returnnew UrlResource(url);
}
catch(MalformedURLException ex) {
//No URL -> resolve as resource path.
returngetResourceByPath(location);
}
}
}代码对资源定位并解析为reource过程,首先判断是否是我们熟悉的classpath:开头的资源,如果是直接使用ClassPathResource加载完成,如果不是就首先尝试使用URL建立resource资源,如果解析不正确就调用一个模板方法getResourceByPath(location);这样就完成了整个资源的定位。接下来就是将一个Resouce读取出来并进行加载和注册,这个是后面要讲的内容。
1.2、Resource的定位的设计模式
从1.1最后得知getResourceByPath(location);使用的就是一个模板方法,首先了解下模板方法的设计理念:
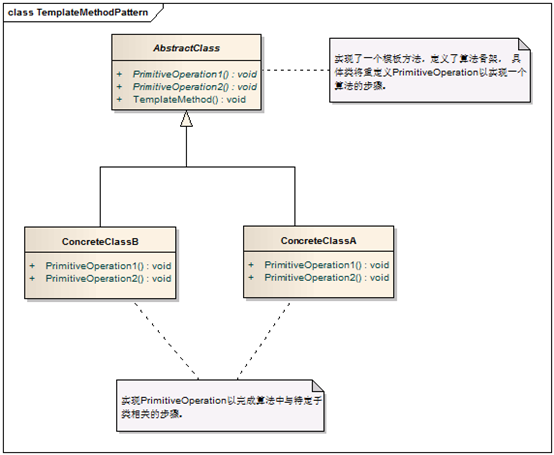
图4、模板方法模式的设计类图
在getResourceByPath中代替AbstractClass的就是DefaultResourceLoader,而分别扩展了它的类ConcreteClassB或A就如下图所示:
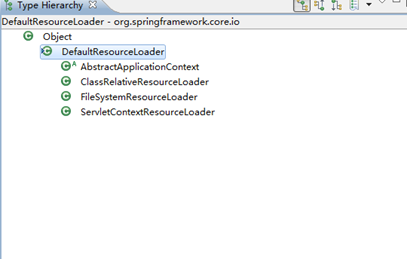
图5、DefaultResourceLoader的扩展类
这些扩展类分别实现getResourceByPath的具体形式,例如FileSystemXmlApplicationContext所使用到的reourceLoader就是FileSystemResourceLoader,它具体实现的getResourceByPath如下所示:
@Override
protectedResource getResourceByPath(String path) {
if(path != null && path.startsWith("/")) {
path= path.substring(1);
}
returnnew FileSystemContextResource(path);
}模板方法模式的总结如下:
l 优点
1) 模板方法模式通过把不变的行为搬移到超类,去除了子类中的重复代码。
2) 子类实现算法的某些细节,有助于算法的扩展。
3) 通过一个父类调用子类实现的操作,通过子类扩展增加新的行为,符合“开放-封闭原则”。
l 缺点
1) 每个不同的实现都需要定义一个子类,这会导致类的个数的增加,设计更加抽象。
l 适用场景
1)有相同代码逻辑的地方抽象出来,并构成一个基本逻辑流程
1.3、Resource的载入
Resource的载入过程首先是拿到reource之后读入成为一个document对象,进而采用xml解析并且存入到beandefinition的过程,具体的时序图如下:
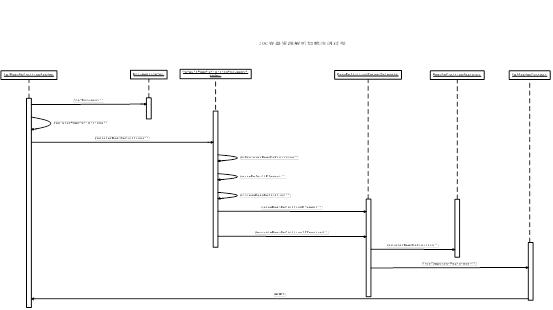
图6、IOC容器解析加载注册时序图
首先得到reource之后需要解析为Document对象,具体代码如下:
protected intdoLoadBeanDefinitions(InputSource inputSource, Resource resource)
throwsBeanDefinitionStoreException {
try{
intvalidationMode = getValidationModeForResource(resource);
Documentdoc = this.documentLoader.loadDocument(
inputSource,getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
returnregisterBeanDefinitions(doc, resource);
}而Document是接下来进行资源解析的前提,其解析是委托一个BeanDefinitionParserDelegate来完成的,首先解析的是DefaultElement,这些关键字我们在xml定义里面已经很熟悉:
privatevoid parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if(delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
elseif (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
elseif (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele,delegate);
}
elseif (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
//recurse
doRegisterBeanDefinitions(ele);
}
}其中importBeanDefinitionResource是触发对引入资源的重新加载,重要的是processBeanDefinition,从这里可以看到这个解析是BeanDefinitionParserDelegate完成的。
protected voidprocessBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolderbdHolder = delegate.parseBeanDefinitionElement(ele);
if(bdHolder != null) {
bdHolder= delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try{
//Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder,getReaderContext().getRegistry());
}
catch(BeanDefinitionStoreException ex) {
getReaderContext().error("Failedto register bean definition with name '" +
bdHolder.getBeanName()+ "'", ele, ex);
}
//Send registration event.
getReaderContext().fireComponentRegistered(newBeanComponentDefinition(bdHolder));
}
}Delegate解析得到的是一个BeanDefinitionHolder,这个BeanDefinitionHolder其实是一个BeanDefinition的封装,其中还包含beanName以及别名alias,对于Element对象被BeanDefinitionParserDelegate解析过程可以详细查看其实现代码。解析完成之后调用registerBeanDefinition进行注册,在BeanDefinition完成注册之后向监听者发送注册完成消息,这是一个订阅者模式的设计。同时decorateBeanDefinitionIfRequired在处理过程中有装饰者模式的设计。
1.2、Resource的载入的设计模式
装饰者模式的设计理念如下:
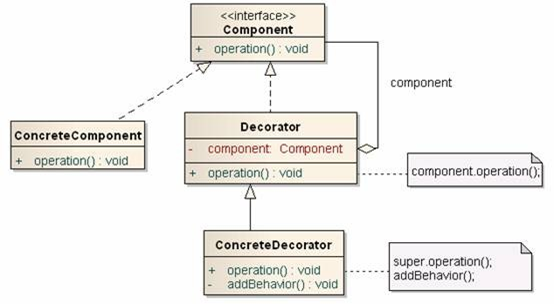
图7、装饰者模式
在这里装饰者是BeanDefinitionParserDelegate,而装饰的对象就是BeanDefinitionHodler,对于BeanDefinitionHodler进行动态数据形式的扩展或删除。
装饰者模式总结:
适用性:
1. 需要扩展一个类的功能,或给一个类添加附加职责。
2. 需要动态的给一个对象添加功能,这些功能可以再动态的撤销。
3. 需要增加由一些基本功能的排列组合而产生的非常大量的功能,从而使继承关系变的不现实。
4. 当不能采用生成子类的方法进行扩充时。一种情况是,可能有大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆炸性增长。另一种情况可能是因为类定义被隐藏,或类定义不能用于生成子类。
优点:
1. Decorator模式与继承关系的目的都是要扩展对象的功能,但是Decorator可以提供比继承更多的灵活性。
2. 通过使用不同的具体装饰类以及这些装饰类的排列组合,设计师可以创造出很多不同行为的组合。
缺点:
1. 这种比继承更加灵活机动的特性,也同时意味着更加多的复杂性。
2. 装饰模式会导致设计中出现许多小类,如果过度使用,会使程序变得很复杂。
3.装饰模式是针对抽象组件(Component)类型编程。但是,如果你要针对具体组件编程时,就应该重新思考你的应用架构,以及装饰者是否合适。当然也可以改变Component接口,增加新的公开的行为,实现“半透明”的装饰者模式。在实际项目中要做出最佳选择。
观察者模式设计理念如下:
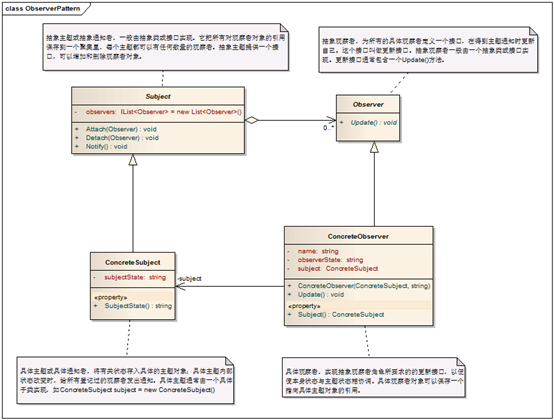
图8、观察者模式
在这段代码中
getReaderContext().fireComponentRegistered(newBeanComponentDefinition(bdHolder));
Subject是抽象主题,对应的就是ReaderContext,具体主题实现也就是ConcreteSubject就是XmlReaderContext,而对应于抽象主题的方法就是fireComponentRegistered。而抽象观察者也就是Obsever就是ReaderEventListener,具体的观察者就是EmptyReaderEventListener,他们接受对应update的方法就是订阅者就是componentRegistered。而在主题的具体实现类XmlReaderContext中存储了观察者具体实现,如下代码:
public ReaderContext(Resource resource,ProblemReporter problemReporter,
ReaderEventListenereventListener, SourceExtractor sourceExtractor) {
this.resource= resource;
this.problemReporter= problemReporter;
this.eventListener= eventListener;
this.sourceExtractor= sourceExtractor;
}eventListener在ReaderContext初始化的过程中就已经设置进去,当然这里的主题他不是一个抽象类或是一个接口,它也是一个具体的class而已。在观察者的实现中,他们都共同需要实现方法componentRegistered(),完成bean加载完成之后的各种操作。
观察者模式总结
优点
1)观察者模式解除了主题和具体观察者的耦合,让耦合的双方都依赖于抽象,而不是依赖具体。从而使得各自的变化都不会影响另一边的变化。
缺点
1)依赖关系并未完全解除,抽象通知者依旧依赖抽象的观察者。
适用场景
1)当一个对象的改变需要给变其它对象时,而且它不知道具体有多少个对象有待改变时。
2)一个抽象某型有两个方面,当其中一个方面依赖于另一个方面,这时用观察者模式可以将这两者封装在独立的对象中使它们各自独立地改变和复用。
spring容器初始化就到此结束,下一节我们讲解Spring容器依赖注入,敬请关注。














 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









