







Adaboost介绍
Adaboost是adaptive boosting(自适应boosting)的缩写,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。它有一个明显的特点就是排除一些不必要的特征值,把模型训练放在关键特征值数据上。它的算法过程如下:
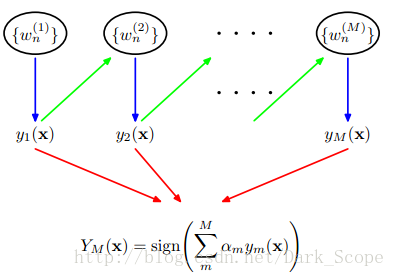
Adaboost从以上概念可以看出它有两种分类器,一种是y1称之为弱分类器,另外一种是Ym称之为强分类器以及一个参数叫alpha,这个值是基于每个弱分类器的错误率进行计算的,其中错误率计算公式如下:

Alpha的计算公式如下:
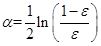
计算出alpha之后就需要对权重向量D进行更新,D的计算方法如下:
正确被分类的权重计算:
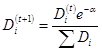
样本被错分之后的权重计算:
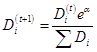
本系统的adaboost是基于单层决策树(decision dump)来构建弱分类器的,单层决策树的算法流程如下:
1、 假设数据特征值分为n列m行,错误率初始化为均值,例如100行数据,初始错误向量值为1/100;
2、 对每一列数据(即维度数据)选择出最大值和最小值;
3、 基于最大和最小值设置每一步的区间,假设100步长,那么步区间为:(max-min)/100
4、 遍历每一步区间,做二分类(1和-1),并记录下本次数据和步长的对比关系(大于或者小于)
5、 依据第4步算出的特征值(1或者-1)计算错误率;
6、 提取最小的错误率、维度、关系运算符以及特征值
我们下面要讲解的spark实现的adaboost算法就是实现上述的算法过程。
算法实现
算法实现和spark的自有MLlib的实现步骤基本相同,主要包括:数据加载、特征提取、模型训练。而adaboost算法模型训练之中又包含:弱分类器训练、权重更新、准确率计算三个部分,我们逐步讲解。
数据加载
public static JavaRDD<SimpleDataPoint> loadLibFileFormatData(
JavaSparkContext sc, String dataFile, boolean labels0Based,
boolean binaryProblem, int minNumPartitions) {
if (sc == null)
throw new NullPointerException("The Spark Context is 'null'");
if (dataFile == null || dataFile.isEmpty())
throw new IllegalArgumentException("The dataFile is 'null'");
//原始文件加载(本文件的特征值及标签是通过tab键分隔,最后一个是标签值)
JavaRDD<String> lines = sc.textFile(dataFile, minNumPartitions).cache();
JavaRDD<SimpleDataPoint> docs = lines.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
//首先进 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









