







 本文详细介绍了如何搭建Spark standalone集群,包括安装、配置SSH无密登录和启动集群。接着,文章说明了如何使用Spark-shell,以及提交任务的方式。通过示例展示了Spark任务提交的参数解释和小实例的运行结果。
本文详细介绍了如何搭建Spark standalone集群,包括安装、配置SSH无密登录和启动集群。接着,文章说明了如何使用Spark-shell,以及提交任务的方式。通过示例展示了Spark任务提交的参数解释和小实例的运行结果。
spark提供了三种集群模式:standalone、yarn以及Mesos,三种模式里面standalone模式是一个基础,本篇先从standalone模式讲解一个基础的spark集群搭建过程,并且基于这个集群我们再介绍一下spark-shell的使用、spark提供的例子如何运行,以及开发一个简单的例子通过任务提交的方式运行起来。
Spark集群搭建(standalone模式)
安装
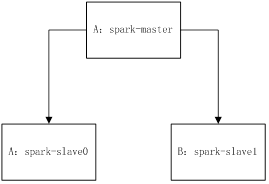
我们以两台机器作为集群搭建,其中spark-master作为master,同时也作为slave,名称为spark-slave0,另外一台机器作为slava,名称为spark-slave1,他们的网络架构如下图所示:
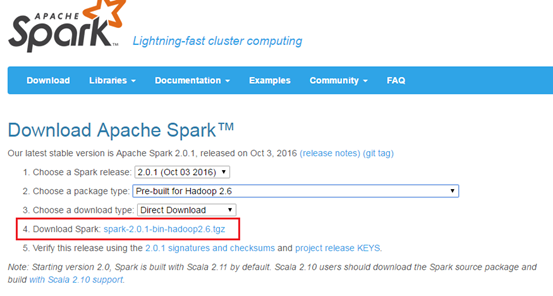
步骤1:进入spark官网下载bin安装包,http://spark.apache.org/downloads.html
步骤2:tar -xvf spark-2.0.1-bin-hadoop2.6
步骤3:cd ./spark-2.0.1-bin-hadoop2.6/conf
步骤4:cp slaves.template slaves
步骤5:cp spark-env.sh.template spark-env.sh
步骤6:修改启动环境变量脚本vim spark-env.sh,添加
export JAVA_HOME="/usr/local/java"
export SCALA_HOME="/usr/local/scala"
export SPARK_HOME="/data/spark-2.0.1-bin-hadoop2.6"
export SPARK_MASTER_HOST=spark-master
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}步骤7:修改slaves配置,vim slaves,添加
spark-slave0
spark-slave1
步骤8:系统环境变量配置(假设系统已安装jdk及scala),vim /etc/profile,添加
export JAVA_HOME="/usr/local/java"
export SPARK_HOME="/data/spark-2.0.1-bin-hadoop2.6"
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib
步骤9:source /etc/profile
步骤10:修改host配置 vim /etc/hosts 添加
A-host-ip spar 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









