







正则化
即模型选择
过拟合
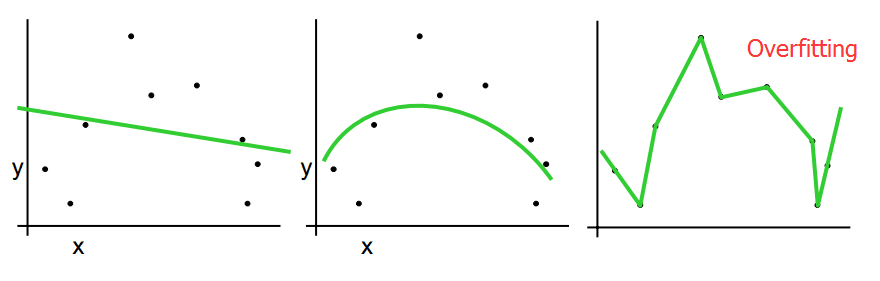
(注:图片来自 Tutorial Slides by Andrew Moore)
交叉验证
交叉验证(Cross-validation,CV)
目的:检测和预防过拟合
| 交叉验证方法 | 优点 | 缺点 |
|---|---|---|
| Test-set | 计算开销小 | 无法评估模型泛化能力 |
| Leave-one-out cross validation(LOOCV) | 不浪费数据 | 计算开销大 |
| k-fold cross validation | 计算开销相对LOOCV小 | 浪费1/k的数据 |
Test-set
将数据集中的全部数据用于模型训练,不考虑模型验证,选择训练集上误差最小的模型为最优模型,易产生过拟合。
LOOCV (Leave-one-out Cross Validation)
下图示例了使用LOOCV方法对线性回归、二次回归、直接点连接模型进行选择的过程.从大小为n的数据集中抽出一个作为模型验证样本,其他的(n-1)个样本用于模型训练,这样对于线性拟合、二次拟合、点连接三种模型分别有n个模型和对应得3个的均方误差(MSE),选择均方差最小 的,即二次拟合为最优模型。
| 线性拟合 | 二次拟合 | 点连接 |
|---|---|---|
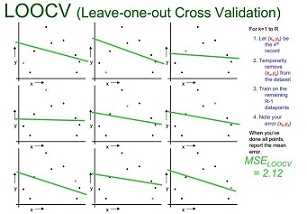 | 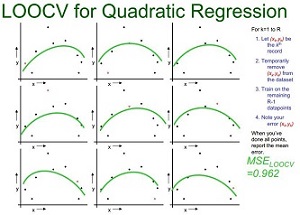 | 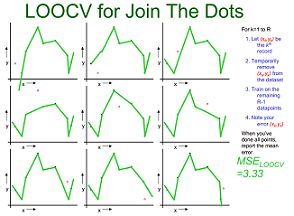 |
k-fold cross validation
以k=3为例,下图示例了使用3-fold交叉验证的方法对线性回归、二次回归、直接点连接模型进行选择的过程,数据集被随机划分为3份,其中2份用来训练模型,1份用来验证,这样针对线性、二次拟合、点连接模型分别有3个训练好的模型和均方误差(MSE),选择均方差最小 的,即二次拟合为最优模型。
| 线性拟合 | 二次拟合 | 点连接 |
|---|---|---|
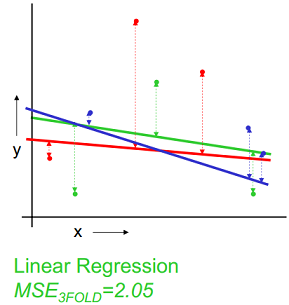 | 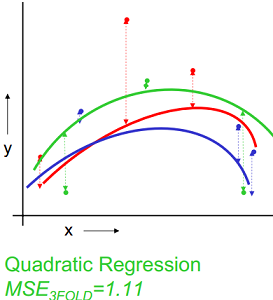 | 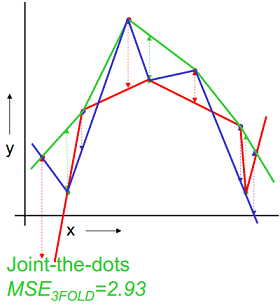 |
数据集
被分为训练集( Training set)、验证集(Validation set)、测试集(Test set)
Ripley, B.D(1996)在他的经典专著Pattern Recognition and Neural Networks中给出了这三个词的定义。
Training set: A set of examples used for learning, which is to fit the parameters [i.e., weights] of the classifier.
Validation set: A set of examples used to tune the parameters [i.e., architecture, not weights] of a classifier, for example to choose the number of hidden units in a neural network.
Test set: A set of examples used only to assess the performance [generalization] of a fully specified classifier.
验证集用来选择模型的超参(hyper-parameter),如学习率、动量、隐藏层结点数等。
损失函数
分类问题
误分率
交叉熵
指数误差
回归问题
均方差
对于方差目标函数,SGD的性能和稳定性一般来说不是很好。
caffe中的MNISTAutoencoder模型(非监督)使用cross_entropy_loss和EuclideanLoss损失函数,而Lenet模型(监督)使用SoftmaxWithLoss.
优化算法
逻辑斯谛模型、最大熵模型、条件随机场都可以归结为目标函数为似然函数的最优化问题,其中目标函数是光滑的凸函数,能保证找到全局最优解。求解算法通常是迭代算法。
改进的迭代尺度算法
梯度下降算法
拟牛顿法
参考文献
1.Dong Yu, Li Deng,Automatic Speech Recognition A Deep Learning Approach
2.http://www.autonlab.org/tutorials/overfit.html















 2666
2666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









