







现在让我们来继续认识一下到底什么是机器学习呢?在机器学习中,最常见的问题就是分类(classification)问题,所谓的分类问题,就比如我们用机器学习算法,将病人的检查结果分为有病和健康,是一个医学方面的二分类问题(将要区分的数据分为两个类别)。再例如在电子邮箱中,收到邮件之后,电子邮箱会将我们的邮件分为广告邮件,垃圾邮件和正常邮件,这就是一个多分类的问题(将要区分的数据分为多个类别)。
为什么我们着重的介绍分类的问题呢?因为分类问题是机器学习中的基础,其他的很多应用都可以从分类的问题演变而来,同时很多问题都可以转化成分类的问题,比如图像中的图像分割,最简单的实现方法就是对每一个像素进行分类,在自然场景的分割中,我们就判断这个像素点是不是房子的一部分,如果是的话,那么他的标签就是房子。
在机器学习中,能够完成分类任务的算法,我们通常把它叫做一个分类器(classifier)。要想评价一个分类器的好坏,我们就要有评价指标,最常见的就是准确率(accuracy),准确率是指被分类器分类正确的数据的数量占所有数据数量的百分比。但是我们可以在不提及数据集的情况下就说一个分类器要比另一个分类器的效果更好么?答案是否定的,具体原因还记得吗?请回看我之前的文章,没有免费午餐理论。
知道了分类器我们就要具体的研究数据了,通常我们会管我们处理的数据叫做数据集(data set)一个数据集通常来说包括三个部分,1,训练数据(training data)及其标签,2,验证数据(validation data)及其标签,3,测试数据(testing data) 。需要特别强调的是,这三部分都是各自独立的,也就是说训练数据中的数据不能再出现在验证数据以及测试数据中,验证数据最好也不要出现在测试数据中,这点在训练分类器的时候一定要特别注意。(这三个部分有时候是可以变成两个部分的,这个我在大家认识了这三部分之后再详细的介绍。)
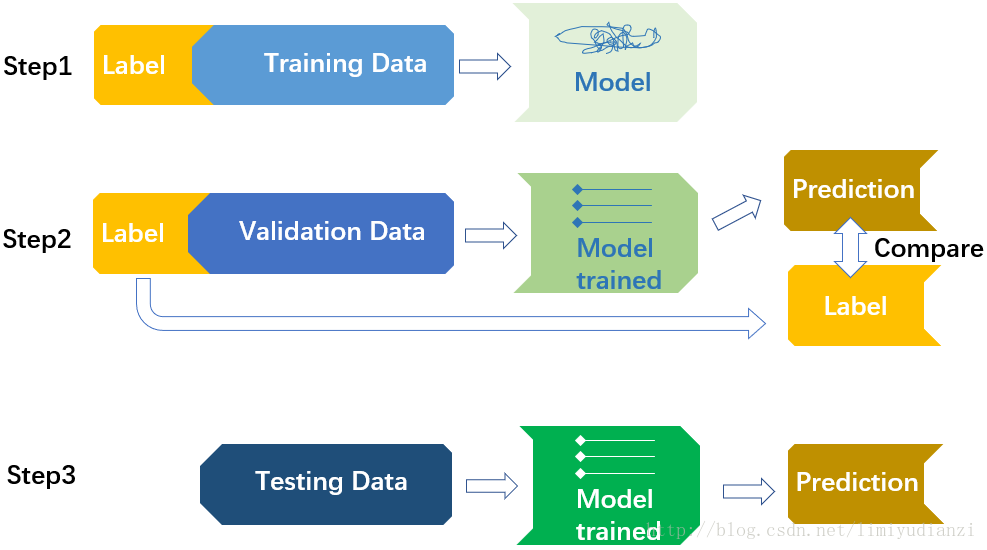
下面我们来讲分类器的训练,如上图所示,训练一个分类器通常需要三个步骤,第一个步骤就是使用训练数据和其标签训练模型,这就好比教育一个小孩子通过观察知道什么是苹果的过程,我们要让他反复的看到各种样式的苹果的照片以及其他不是苹果的物体的照片(训练数据),并且告诉他哪些照片是苹果,哪些不是(训练数据的标签),通过这样的过程让小孩子学习。
第二个步骤就是将验证数据输入模型中,比较验证数据的标签和模型分类结果的区别,进而评价算法的学习效果,通常来说一个机器学习算法的准确率或者其他指标就是在验证数据上得到的。这就好像我们教了孩子一段时间之后,我们拿一个黑白电视机的照片(在之前的教育过程中,小孩子只见过彩色电视机没见过黑白的电视机,这是和训练数据不同的验证数据,“不是苹果”这个结论就是验证数据的标签),问小孩子这是不是苹果,看小孩子能否答对,进而评价小孩子的学习效果。
第三个步骤是机器学习算法的实际应用过程,等到我们认为模型已经训练的足够好了,在验证数据上取得了很好的效果之后,我们就将这个模型真正的运用于实际中去,代替我们工作,有时候在一些科研项目中是不存在这个步骤的,因为如果要衡量一个机器学习算法的优越性,使用第二步中有标签的数据就可以做到,什么时候那个算法真正在现实生活中应用了,那么才会有很多的无标签数据让机器去代替人们完成任务。就像小孩子认识了什么是苹果,那么他就可以从事对照片分类的工作了,他可以基本正确的分辨出哪些照片是苹果而哪些不是,这样以后就不用大人手工的挑选照片了,这个艰巨而又无聊的选择苹果照片的任务就交给小孩子了。
上面讲的就是最标准的拥有三类数据(训练,验证,测试)的情况,下面我们将介绍两部分数据的情况。有些时候,我们得到的数据只有训练数据(有标签)和测试数据(无标签),这时候我们就需要人为的将训练数据中的一部分拿出来作为验证数据,这部分验证数据不参与分类器的学习过程,通常训练数据和验证数据的比例是7比3,就是拿出70%的有标签数据作为训练数据,30%的有标签数据作为验证数据。
还有时我们的数据都是有标签的数据,那么这时候我们通常来说也按照7比3的比例,将有标签的数据分为训练数据和验证数据,通过验证数据衡量模型在这套数据上的性能,从而省略第三个步骤。















 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









