







Hadoop学习笔记(三)一个实例
1.辅助类GenericOptionsParser,Tool和ToolRunner
上一章使用了GenericOptionsParser这个类,它用来解释常用的Hadoop命令行选项,并根据需要,对Configuration对象设置相应的值。通常不直接使用GenericOptionsParser类,更方便的方法是:实现Tool接口,通过ToolRunner来调用,而ToolRunner内部最终还是调用的GenericOptionsParser类。
public interface Tool extends Configurable {
int run(String[] args) throws Exception;
}然后给出一个Tool的简单实现,这里我用来处理每天的日志信息:
import java.util.Calendar;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger;
public class Load extends Configured implements Tool {
private final static Logger logger = Logger.getLogger(Load.class);
/**
* @param args
*/
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new Load(), args);
System.exit(res);
}
@Override
public int run(String[] args) throws Exception {
// 要处理哪天的数据
final java.util.Date date;
if (args.length >= 1) {
String st = args[0];
java.text.SimpleDateFormat sdf = new java.text.SimpleDateFormat("yyyyMMdd");
try {
date = sdf.parse(st);
} catch (java.text.ParseException ex) {
throw new RuntimeException("input format error," + st);
}
} else {
Calendar cal = Calendar.getInstance();
cal.add(Calendar.DAY_OF_MONTH, -1);
date = cal.getTime();
}
Job job = new Job(this.getConf(), "load_" + new java.text.SimpleDateFormat("MMdd").format(date));
job.setJarByClass(Load.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(LoadMapper.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(SearchLogProtobufWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
FileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
FileOutputFormat.setOutputCompressorClass(job, SnappyCodec.class);
// 输入目录,hadoop文件
java.text.SimpleDateFormat sdf = new java.text.SimpleDateFormat("yyyyMMdd");
String inputdir = "/log/raw/" + sdf.format(date) + "/*access.log*.gz";
logger.info("inputdir = " + inputdir);
/* 本地文件
java.text.SimpleDateFormat sdf = new java.text.SimpleDateFormat("yyyy/yyyyMM/yyyyMMdd");
String inputdir = "file:///opt/log/" + sdf.format(date) + "/*access.log*.gz";
logger.info("inputdir = " + inputdir);*/
// 输出目录
final String outfilename = "/log/" + new java.text.SimpleDateFormat("yyyyMMdd").format(date) + "/access";
logger.info("outfile dir = " + outfilename);
Path outFile = new Path(outfilename);
FileSystem.get(job.getConfiguration()).delete(outFile, true);
FileInputFormat.addInputPath(job, new Path(inputdir));
FileOutputFormat.setOutputPath(job, outFile);
job.waitForCompletion(true);
return 0;
}
}这么个构造函数,以下是他的关系图:
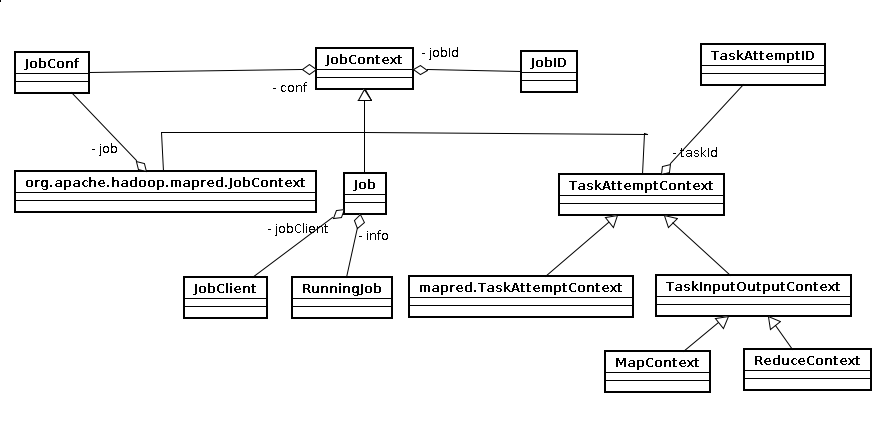
JobContext它提供只读属性,它含有两个成员JobConf以及JobID。它提供的只读属性除了jobId保存在JobID中以外,所有的属性都是从jobConf中读取,包括以下属性:
1.mapred.reduce.tasks,默认值为1
2.mapred.working.dir,文件系统的工作目录
3.mapred.job.name,用户设置的job 的名字
4.mapreduce.map.class
5.mapreduce.inputformat.class
6.mapreduce.combine.class
7.mapreduce.reduce.class
8.mapreduce.outputformat.class
9.mapreduce.partitioner.class
Job:The job submitter's view of the Job. It allows the user to configure the job, submit it, control its execution, and query the state. The set methods only work until the job is submitted, afterwards they will throw an IllegalStateException.它可以对job进行配置,提交,控制其执行,查询状态。
它有两个成员:JobClient和RunningJob
然后我们来看一下Mapper
Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
这是Mapper类,它内置了一个Context类
public class MRLoadMapper extends Mapper<LongWritable, Text, LongWritable, SearchLogProtobufWritable> {
private final static Logger logger = Logger.getLogger(MRLoadMapper.class);
private long id = 0;
private final SimpleDateFormat sdf = new SimpleDateFormat("-dd/MMM/yyyy:HH:mm:ss Z");
private final LongWritable outputkey = new LongWritable();
private final SearchLogProtobufWritable outputvalue = new SearchLogProtobufWritable();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
int taskid = context.getTaskAttemptID().getTaskID().getId();
this.id = taskid << 40;
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
final SearchLog.Builder builder;
SearchLog msg = null;
try {
String[] cols = line.split("\\t");
if (cols.length != 9) {
context.getCounter("bad", "colsMissMatch").increment(1);
logger.info("处理文件的第" + key.get() + "行内容时出错,内容为【" + line + "】,列数不符合");
return;
}
String remote_addr = cols[0];
String time_local = cols[1]; // todo: set time
String remote_user = cols[2];
String url = cols[3];
String status = cols[4];
String body_bytes_sent = cols[5];
String http_user_agent = cols[6];
String dummy2 = cols[7];
String dummy3 = cols[8];
builder = SearchLog.newBuilder().setRemoteAddr(remote_addr).setStatus(Integer.valueOf(status))
.setId(++this.id).setTime(this.sdf.parse(time_local).getTime())
.setBodyBytesSent(Integer.valueOf(body_bytes_sent)).setUa(http_user_agent);
com.sunchangming.searchlog.LoadPlainLog.parseURL(url, builder);
msg = builder.build();
} catch (LocationCannotNull ex) {
context.getCounter("bad", "lo为空").increment(1);
context.getCounter("bad", "parseError").increment(1);
logger.info("处理文件内容时出错,lo为空,内容为【" + line + "】");
} catch (UriSchemeIsLocal ex) {
context.getCounter("bad", "URIscheme是file").increment(1);
context.getCounter("bad", "parseError").increment(1);
} catch (UriSchemeError ex) {
context.getCounter("bad", "UriSchemeError").increment(1);
context.getCounter("bad", "parseError").increment(1);
} catch (Exception ex) {
context.getCounter("bad", "parseError").increment(1);
logger.info("处理文件内容时出错,内容为【" + line + "】,出错信息是【" + ex.toString() + "】");
}
if (msg != null) {
this.outputkey.set(this.id);
this.outputvalue.set(msg);
context.write(this.outputkey, this.outputvalue);
}
}
}整个程序只用了一个Mapper,将数据转化,传输到HDFS中。接着,学习一下使用Pig来处理这些数据。
2.Pig简介
http://pig.apache.org/docs/r0.10.0/start.html
这个链接是关于Pig的教程
Loading Data
Use the LOAD operator and the load/store functions to read data into Pig (PigStorage is the default load function).
Working with Data
Pig allows you to transform data in many ways. As a starting point, become familiar with these operators:
-
Use the FILTER operator to work with tuples or rows of data. Use the FOREACH operator to work with columns of data.
-
Use the GROUP operator to group data in a single relation. Use the COGROUP, inner JOIN, and outer JOIN operators to group or join data in two or more relations.
-
Use the UNION operator to merge the contents of two or more relations. Use the SPLIT operator to partition the contents of a relation into multiple relations
Storing Intermediate Results
Pig stores the intermediate data generated between MapReduce jobs in a temporary location on HDFS. This location must already exist on HDFS prior to use. This location can be configured using the pig.temp.dir property. The property's default value is "/tmp" which is the same as the hardcoded location in Pig 0.7.0 and earlier versions.
Storing Final Results
Use the STORE operator and the load/store functions to write results to the file system (PigStorage is the default store function).
与MapReduce相比,Pig提供了更丰富的数据结构,还提供了强大的数据转换操作
这里给出一个我对于上述Map出来的数据的处理:
register /home/app_admin/scripts/piglib/*.jar
/** SearchLog类在这里面 */
register /home/app_admin/scripts/loadplainlog/loadplainlog.jar
rmf /result/keyword/$logdate
a = LOAD '/log/$logdate/access/part-m-*' USING com.searchlog.AccessLogPigLoader;
/** 然后过滤。 当前页域名是www.****.com,关键字不为空,第一页,有直达区结果或者普通搜索结果,当前页url是特定路径*/
a_all = FILTER a BY location.host == 'www.****.com' and keyword is not null and keyword != '' and pageno == 1 ;
/** 按照keyword做分组 */
b_all = GROUP a_all BY keyword;
/** 对分组后的结果计算count */
c_all = FOREACH b_all GENERATE group, COUNT(a_all.id) as keywordSearchCount, MAX(a_all.vs) as vs;
/** 把计算结果按照搜索次数排序 */
d_all = ORDER c_all by keywordSearchCount DESC;
result = FOREACH d_all GENERATE group,keywordSearchCount,vs;
/** 把结果存文件中 */
store result into '/result/keyword/$logdate/' USING PigStorage();














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









