







 本文介绍了Druid的基本特性和架构,详细阐述了Druid的高可用性,并提供了安装Druid的步骤,包括安装环境的准备、使用Imply套件进行安装的过程,以及数据导入和查询的演示。
本文介绍了Druid的基本特性和架构,详细阐述了Druid的高可用性,并提供了安装Druid的步骤,包括安装环境的准备、使用Imply套件进行安装的过程,以及数据导入和查询的演示。
1.Druid介绍
参考文章:
链接地址
Druid是一个为在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个高级的索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。
特性
为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描优必要的元素被优化。Aggregate和 filter没有坐等结果。
高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描优必要的元素被优化。Aggregate和 filter没有坐等结果。
高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
使用场景:
第一:适用于清洗好的记录实时录入,但不需要更新操作
第二:支持宽表,不用join的方式(换句话说就是一张单表)
第三:可以总结出基础的统计指标,可以用一个字段表示
第四:对时区和时间维度(year、month、week、day、hour等)要求高的(甚至到分钟级别)
第五:实时性很重要
第六:对数据质量的敏感度不高
第七:用于定位效果分析和策略决策参考
第二:支持宽表,不用join的方式(换句话说就是一张单表)
第三:可以总结出基础的统计指标,可以用一个字段表示
第四:对时区和时间维度(year、month、week、day、hour等)要求高的(甚至到分钟级别)
第五:实时性很重要
第六:对数据质量的敏感度不高
第七:用于定位效果分析和策略决策参考
架构
它的架构如图所示:
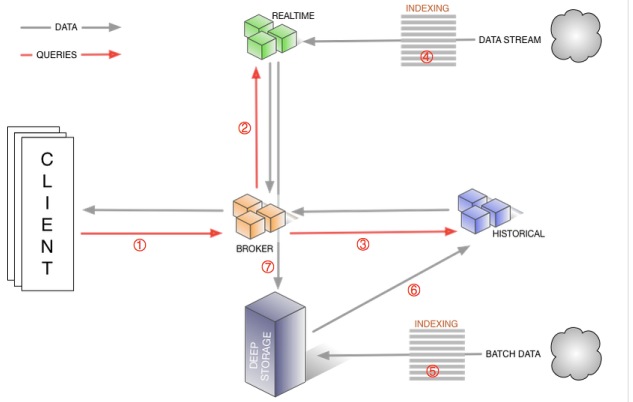
- 查询路径:红色箭头:①客户端向Broker发起请求,Broker会将请求路由到②实时节点和③历史节点
- Druid数据流转:黑色箭头:数据源包括实时流和批量数据. ④实时流经过索引直接写到实时节点,⑤批量数据通过IndexService存储到DeepStorage,⑥再由历史节点加载. ⑦实时节点也可以将数据转存到DeepStorage
Historical节点是对“historical”数据(非实时)进行处理存储和查询的地方。hist
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









