







1:查询频繁 2:区分度高 3:长度小 4: 尽量能覆盖常用查询字段.
1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
针对列中的值,从左往右截取部分,来建索引
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度.
所以, 要在 区分度 + 长度 两者上,取得一个平衡.
但从 商城的实际业务业务看, 顾客一般先选大分类->小分类->品牌,
最终选择 index(cat_id,brand_id)来建立索引
有如下表(innodb引擎), sql语句在笔记中,
给定日照市,查询子地区, 且查询子地区的功能非常频繁,
如何优化索引及语句?
2: 给name加索引
3: 在Pid上也加索引
1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
针对列中的值,从左往右截取部分,来建索引
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度.
所以, 要在 区分度 + 长度 两者上,取得一个平衡.
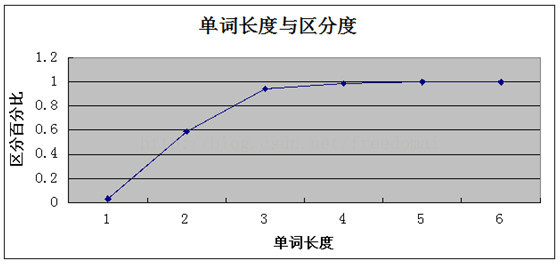
惯用手法: 截取不同长度,并测试其区分度,
<span style="font-size:18px;">select count(distinct left(word,6))/count(*) from dict;
+---------------------------------------+
| count(distinct left(word,6))/count(*) |
+---------------------------------------+
| 0.9992 |
+---------------------------------------+</span>截取word字段长度,从1开始截取,计算字符前缀没有重复的字符占全部数据的比例
对于一般的系统应用: 区别度能达到0.1,索引的性能就可以接受.
3:多列索引
3.1 多列索引的考虑因素---
列的查询频率 , 列的区分度,
以ecshop商城为例, goods表中的cat_id,brand_id,做多列索引
从区分度看,Brand_id区分度更高,
select count(distinct cat_id) / count(*) from goods;
+-----------------------------------+
| count(distinct cat_id) / count(*) |
+-----------------------------------+
| 0.2903 |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select count(distinct brand_id) / count(*) from goods;
+-------------------------------------+
| count(distinct brand_id) / count(*) |
+-------------------------------------+
| 0.3871 |
+-------------------------------------+
1 row in set (0.00 sec)但从 商城的实际业务业务看, 顾客一般先选大分类->小分类->品牌,
最终选择 index(cat_id,brand_id)来建立索引
有如下表(innodb引擎), sql语句在笔记中,
给定日照市,查询子地区, 且查询子地区的功能非常频繁,
如何优化索引及语句?
+------+-----------+------+
| id | name | pid |
+------+-----------+------+
| .... | .... | .... |
| 1584 | 日照市 | 1476 |
| 1586 | 东港区 | 1584 |
| 1587 | 五莲县 | 1584 |
| 1588 | 莒县 | 1584 |
+------+-----------+------+
1: 不加任何索引,自身连接查询
explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3263
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3263
Extra: Using where; Using join buffer
2 rows in set (0.00 sec)2: 给name加索引
explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ref
possible_keys: name
key: name
key_len: 93
ref: const
rows: 1
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 3243
Extra: Using where; Using join buffer
2 rows in set (0.00 sec)3: 在Pid上也加索引
explain select s.id,s.name from it_area as p inner join it_area as s on p.id=s.pid where p.name='日照市' \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: p
type: ref
possible_keys: name
key: name
key_len: 93
ref: const
rows: 1
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: s
type: ref
possible_keys: pid
key: pid
key_len: 5
ref: big_data.p.id
rows: 4
Extra: Using where
2 rows in set (0.00 sec)

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









