







说明:
solr 是一个非常完善的开源项目,非常优秀,他不紧紧是做个索引这么简单,而是可以做成一个垂直的网站,比如团购网站,快速搭建页面。
而且solr带了一个非常优秀的管理后台。可以查看管理,导入数据,重建索引,同步主从数据,非常强大。
这里主要展示的是solr 可以快速搭建一个团购网站,并且将代码做成demo放到github上面供大家学习参考。
代码修改的比较仓促还在不断完善。
1,环境搭建,使用solr4.10 版本
从apache 官方网站下载最新的 solr 4.10.0 http://lucene.apache.org/solr/
团购数据从 hao123 的官方网站接口找到的,大家都可以获得,公开的数据。
http://www.hao123.com/redian/api.htm 美团数据下载:http://www.meituan.com/api/deals/hao123 一共 1.27G 非常大,因为是没有压缩的xml数据,(使用htttp下载,用工具可能会被封。)。
将工程修改成maven的工程,因为不是开发solr而是使用solr,在example下面有个war包,解压缩到maven工程。
2,配置solr
下载的数据是xml的格式:
<urlset>
<url>
<loc>http://bj.meituan.com/deal/6330826.html?source=hao123</loc>
<data>
<display>
<website>美团网</website>
<siteurl>http://bj.meituan.com</siteurl>
<city>北京</city>
<sort>休闲娱乐</sort>
<title>【2店通用】CGV星星国际影城单人电影票1张,2D/3D可兑</title>
<image>http://p1.meituan.net/275.168/deal/201301/04/173144_2860489.jpg</image>
<startTime>1373040000</startTime>
<endTime>1377943200</endTime>
<value>100</value>
<price>30</price>
<rebate>3折</rebate>
<bought>13593</bought>
<spend_start_time>1373040000</spend_start_time>
<spend_close_time>1377964799</spend_close_time>
<longitude>116.490591</longitude>
<latitude>39.970472</latitude>
<collections>0</collections>
<type>2</type>
<soldout>no</soldout>
</display>
</data>
</url>
....
</urlset>
在工程根目录下面 有个solr文件夹,下面是solr的配置文件,其中一个子文件夹,tuan是团购的配置文件夹。
工程是用mave搭建的,扩展性更强。
根据美团的数据,将配置solr的数据文件。
参考:
配置 schema.xml
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true"
required="true" multiValued="false" />
<field name="title" type="text_general" indexed="true" stored="true" />
<field name="image" type="string" indexed="false" stored="true" />
<field name="value" type="double" indexed="false" stored="true" />
<field name="price" type="double" indexed="true" stored="true" />
<field name="rebate" type="double" indexed="true" stored="true" />
<field name="bought" type="long" indexed="true" stored="true" />
<field name="city" type="string" indexed="true" stored="true" />
<field name="sort" type="string" indexed="true" stored="true" />
<field name="loc" type="string" indexed="true" stored="true" />
<field name="startTime" type="date" indexed="true" stored="true" />
<field name="endTime" type="date" indexed="true" stored="true" />
<!-- catchall field, containing all other searchable text fields (implemented
via copyField further on in this schema -->
<field name="text" type="text_general" indexed="true" stored="false"
multiValued="true" />
<field name="_version_" type="long" indexed="true" stored="true" />
</fields>
<uniqueKey>id</uniqueKey>
<copyField source="title" dest="text" />
<types>
<fieldType name="string" class="solr.StrField"
sortMissingLast="true" />
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField"
sortMissingLast="true" />
<fieldType name="int" class="solr.TrieIntField"
precisionStep="0" positionIncrementGap="0" />
<fieldType name="float" class="solr.TrieFloatField"
precisionStep="0" positionIncrementGap="0" />
<fieldType name="long" class="solr.TrieLongField"
precisionStep="0" positionIncrementGap="0" />
<fieldType name="double" class="solr.TrieDoubleField"
precisionStep="0" positionIncrementGap="0" />
<fieldType name="tint" class="solr.TrieIntField"
precisionStep="8" positionIncrementGap="0" />
<fieldType name="tfloat" class="solr.TrieFloatField"
precisionStep="8" positionIncrementGap="0" />
<fieldType name="tlong" class="solr.TrieLongField"
precisionStep="8" positionIncrementGap="0" />
<fieldType name="tdouble" class="solr.TrieDoubleField"
precisionStep="8" positionIncrementGap="0" />
<fieldType name="date" class="solr.TrieDateField"
precisionStep="0" positionIncrementGap="0" />
<fieldType name="tdate" class="solr.TrieDateField"
precisionStep="6" positionIncrementGap="0" />
<fieldtype name="binary" class="solr.BinaryField" />
<fieldType name="pint" class="solr.IntField" />
<fieldType name="plong" class="solr.LongField" />
<fieldType name="pfloat" class="solr.FloatField" />
<fieldType name="pdouble" class="solr.DoubleField" />
<fieldType name="pdate" class="solr.DateField"
sortMissingLast="true" />
<fieldType name="random" class="solr.RandomSortField"
indexed="true" />
<fieldType name="text_ws" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory" />
</analyzer>
</fieldType>
<fieldType name="text_general" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!-- CJK bigram (see text_ja for a Japanese configuration using morphological
analysis) -->
<fieldType name="text_cjk" class="solr.TextField"
positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory" />
<!-- normalize width before bigram, as e.g. half-width dakuten combine -->
<filter class="solr.CJKWidthFilterFactory" />
<!-- for any non-CJK -->
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.CJKBigramFilterFactory" />
</analyzer>
</fieldType>
</types>
</schema>
配置:solrconfig.xml
<!-- 增加xml 数据导入 -->
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">xml-data-config.xml</str>
</lst>
</requestHandler>
<requestHandler name="/browse" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<!-- VelocityResponseWriter settings -->
<str name="wt">velocity</str>
<str name="v.properties">velocity.properties</str>
<str name="v.contentType">text/html;charset=utf-8</str>
<str name="v.template">browse</str>
<str name="v.layout">layout</str>
<str name="title">团购网站demo</str>
<!-- Query settings -->
<str name="defType">edismax</str>
<str name="df">text</str>
<str name="mm">100%</str>
<str name="q.alt">*:*</str>
<str name="rows">32</str>
<str name="fl">*,score</str>
<!-- Faceting defaults -->
<str name="facet">on</str>
<str name="facet.field">city</str>
<str name="facet.field">sort</str>
<str name="facet.range">price</str>
<int name="f.price.facet.range.start">100</int>
<int name="f.price.facet.range.end">1500</int>
<int name="f.price.facet.range.gap">200</int>
<!-- Highlighting defaults -->
<str name="hl">on</str>
<str name="hl.fl">title</str>
<str name="hl.encoder">html</str>
<str name="hl.simple.pre"><font colr='red' ></str>
<str name="hl.simple.post"></font></str>
<str name="f.title.hl.fragsize">0</str>
<str name="f.title.hl.alternateField">title</str>
<!-- Spell checking defaults -->
<str name="spellcheck">on</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.count">5</str>
<str name="spellcheck.alternativeTermCount">2</str>
<str name="spellcheck.maxResultsForSuggest">5</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
<str name="spellcheck.maxCollationTries">5</str>
<str name="spellcheck.maxCollations">3</str>
</lst>
<!-- append spellchecking to our list of components -->
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
配置:xml-data-import.xml
<dataConfig>
<script><![CDATA[
function ReplaceLocAddId(row) {
var loc_1 = row.get('loc').split('/deal/');
var loc_2 = loc_1[1].split('.html');
var id = loc_2[0];
row.put('id', id);
//格式化时间.
var sdf = new java.text.SimpleDateFormat('yyyy-MM-dd HH:mm:ss');
//开始时间.
row.put('startTime', com.demo.tuan.DateUtils.format(row.get('startTime')));
//结束时间.
row.put('endTime', com.demo.tuan.DateUtils.format(row.get('endTime')));
//去掉折扣汉字.
row.put('rebate', row.get('rebate').replace('折',''));
return row;
}
]]></script>
<dataSource type="FileDataSource" encoding="utf-8" />
<document>
<entity name="tuan" pk="loc"
url="/data/workspace.freewebsys/solr4_demo/doc/meituan_hao123.xml"
processor="XPathEntityProcessor" forEach="/urlset/url"
transformer="script:ReplaceLocAddId,DateFormatTransformer">
<field column="loc" xpath="/urlset/url/loc" commonField="true" />
<field column="city" xpath="/urlset/url/data/display/city"
commonField="true" />
<field column="sort" xpath="/urlset/url/data/display/sort"
commonField="true" />
<field column="title" xpath="/urlset/url/data/display/title"
commonField="true" />
<field column="image" xpath="/urlset/url/data/display/image"
commonField="true" />
<field column="value" xpath="/urlset/url/data/display/value"
commonField="true" />
<field column="price" xpath="/urlset/url/data/display/price"
commonField="true" />
<field column="rebate" xpath="/urlset/url/data/display/rebate"
commonField="true" />
<field column="bought" xpath="/urlset/url/data/display/bought"
commonField="true" />
<field column="startTime" xpath="/urlset/url/data/display/startTime"
dateTimeFormat="yyyy-MM-dd HH:mm:ss" commonField="true" />
<field column="endTime" xpath="/urlset/url/data/display/endTime"
dateTimeFormat="yyyy-MM-dd HH:mm:ss" commonField="true" />
</entity>
</document>
</dataConfig>
配置好了,开始导入数据:管理后台,使用超级方便。界面也非常漂亮。

倒入数据成功。
3,修改页面显示
修改样式:将原始页面进行修改,套用别的团购网站样式。数据里面直接可显示图片等信息。
可以使用nginx 直接将 /tuan/browse 代理到线上部署,前端最好再加上一层varnish做页面缓存,性能更好。

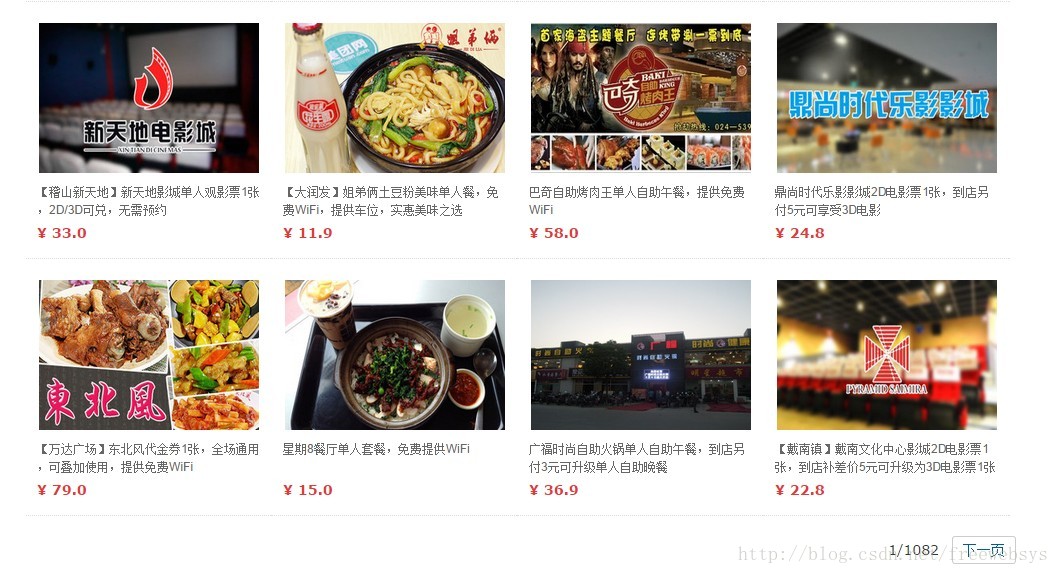
solr 已经将很多东西集成进来了,比如分类数据,区间分类数据,数据推荐,相关推荐等,非常强大,越研究越有味道。
4,代码提交:
代码和配置已经上传到github上面了:
包括全部代码,配置文件,本地就可以直接使用jetty运行。














 474
474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









