






优化Drupal.
译者:老葛 ESKALATE 科技公司
Drupal的内核架构非常简洁并且非常灵活。然而,这种灵活性是有代价的。当启用的模块增加时,处理一个请求的复杂度也会增加。这意味着将耗费更多的服务器资源,必须实现一些策略,在一个站点日渐流行时,来保证Drupal的极其著名的灵活性。通过适当的配置,Drupal可以很容易的满足用户的需求。在本章中,我们将讨论性能(performance)和可升级性(scalability)。性能指的是你的站点响应一个请求所用的时间。可升级性指的是你的系统可以同时处理多少个并发请求,通常用“请求数/秒”来度量。
找出瓶颈
如果你的网站运行性能达不到预期,第一步要做的就是分析问题所在。可能的原因包括web服务器,操作系统,数据库,和网络。
逐步追踪
知道如何估算一个系统的性能和可升级性,即便是在出现大的问题时,它也能使得你能保持自信,从而快速的隔离并找到系统的瓶颈。你可以借助于一些简单的工具,通过询问一些问题,来发现瓶颈。这里有一个方式用来分析一个存在严重性能问题的服务器。首先,我们需要知道性能有哪些因素决定了,CPU,RAM,I/O,或者带宽都是影响性能的因素。那么你需要询问以下问题:
CPU占用率达到最大了吗?检查CPU的使用情况,在Unix上你可以使用top,在Windows上可以使用任务管理器,如果CPU占用率达到了100%,那么你的任务就是找出是什么程序占用了CPU。查看进程列表,可以让你了解到是不是web服务器或者数据库占用了大部分处理器计算资源。这两者都是可以解决的。
服务器的RAM用完了没有?在Unix上你可以使用top,在Windows上可以使用任务管理器,可以很容易的检查这一点。如果服务器还有大量的空闲内存,继续下一个问题。如果服务器用完了内存,你必须找出原因。
磁盘空间不足了吗?检查磁盘子系统,在Unix使用工具vmstat,在Windows下使用性能监测器,如果可用磁盘不能满足需求,同时又有大量空闲内存剩余,那么这就是一个I/O问题。可能的原因包括记录大量的冗余的日志,对数据库不恰当的配置使得在磁盘上创建了许多临时表,后台脚本的执行,对于一个需要大量写操作的系统使用了一个不恰当的RAID级别,等等。
网络带宽用完了吗?如果网络带宽用完了,那么只有两种解决方案。一个是增加带宽。另一个是对发送的信息进行恰当的压缩,从而发送更少的信息。
Web服务器用完了CPU
如果你的CPU占用率达到了100%,而进程列表显示,是web服务器消耗了大量的资源而不是数据库(后面介绍),那么你应该去减少web服务器处理一个请求所耗费的资源。通常PHP代码的执行是罪魁祸首。
PHP最优化措施
在Drupal中,由于PHP代码执行在处理一个请求中占了一大块,所以我们需要知道采取哪些措施才能加快这一进程,这一点非常重要。对编译后的PHP操作代码(opcodes)进行缓存,和剖析应用层来找出低效算法,能够带来重要的性能提升。
缓存操作代码 有两种方式可以减少执行PHP代码所耗费的资源。很明显,一种是减少代码总量,可以通过禁用不必要的Drupal模块和编写高效的代码来达到这一点。另一种方式就是使用一个opcode缓存。PHP对于每个请求,都会将所有代码解析并编译成一种中间形态,这种形态里包含了一系列的操作代码。添加一个opcode缓存可以让PHP能够重用前面编译过的代码,这样就会跳过解析和编译。常见的opcode缓存有Alternative PHP Cache (http://pecl.php.net/package/APC), eAccelerator (http://eaccelerator.net), XCache (http://trac.lighttpd.net/xcache/), 和 Zend Platform (http://zend.com)。Zend是一个商业产品,而其它几个则是免费的。
由于Drupal是一个需要大量数据库操作的程序,所以一个opcode缓存不能作为一个单独的解决方案,但它一个整体方案中的一部份。只需要最小的努力,他人仍然可以代码明显的性能提升。
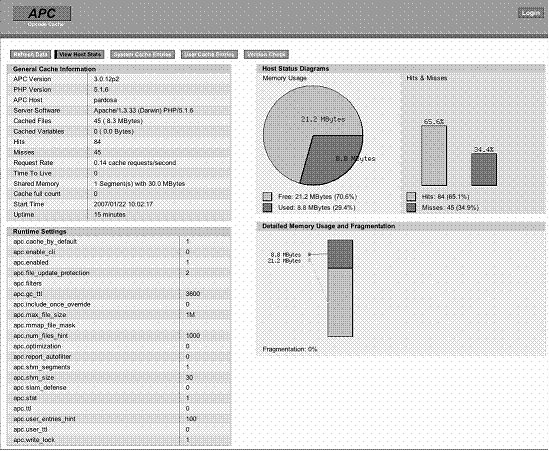
图22-1 Alternative PHP Cache (APC)带有有一个接口,它能够展示内存分配情况和当前缓存中的文件。
剖析应用 通常定制的代码和模块对于小规模的站点能够很好的工作,如果将它放到上线的站点上那么就可能成为站点的瓶颈。耗费CPU的代码循环,占用内存的算法,还有大量的数据库读取,这些都可以通过剖析你的代码来决定PHP在哪里花费了大量时间,因此,找到的关键点也就是你需要花费大量时间进行调试的地方。更多关于PHP调试器和profiler的信息,参看第21章。
如果,即便是添加了opcode并且优化了你的代码以后,你的web服务器仍然不能处理这么大的负载,那么现在你就应该换一个带有更多或者更快的CPU的更强大的服务器,或者更换应用架构,采用多个web服务器。
Web服务器用完了RAM
Web服务器进程处理一个请求时,用到RAM的地方包括,web服务器加载所有的模块(比如Apache的mime_module, rewrite_module,等等),还有PHP解释器使用的内存。启用的web服务器和Drupal模块越多,处理单个请求耗费的RAM就越多。
注意 分配给PHP解释器的最大内存,可通过PHP的php.ini文件中的memory_limit进行设置。它的默认值为8MB,为了留给Drupal足够的空间,至少需要将其翻倍。只有编译你的PHP时使用了Denable-memory-limit,指令memory_limit才会生效。
因为RAM是个有限的资源,你应该决定对于每个请求分配多少内存,还有你的web服务器能够能够同时处理多少个请求。为了知道平均为每个请求使用多少内存,可使用一个向Unix中的top一样的程序来查看你的进程列表。在Apache中,可以使用指令MaxClients来设置能够处理的最大并发请求数。一个常见的错误认为,解决满负荷的web服务器的方案是增加MaxClients的值。这只会让问题变得更加复杂,因为你将同时收到太多的请求。这意味着RAM将被耗尽,而你的服务器将开始进行磁盘交换并变得不能响应请求。让我们假定,你的web服务器拥有2GB的内存,而每个Apache请求大约使用20MB(你可以使用top来检查实际值)。通过下面的公式,你可以为MaxClients计算出一个合适的值;你应该记住你将需要为你的操作系统和其它进程保留一定的内存:
2GB RAM / 20MB per process = 100 MaxClients
如果在禁用了不需要的web服务器模块,并且优化了定制的模块或者代码以后,你的服务器仍然耗尽内存,那么接下来你要做的是确保数据库和操作系统不是产生瓶颈的原因。如果是由它们引起的,那么就添加更多的内存。如果不是,那么问题就很简单了,你收到的请求比你能够处理的请求要多;解决方案就是添加更多的web服务器。
提示 由于Apache进程用到的内存,随着它的子进程处理更加耗费内存的页面,有逐步增加的趋势,通过将MaxRequestsPerChild的值设的小一点比如300(实际的值依赖于你所处的环境)可以收回不少的内存。Apache将会更努力一点的工作来生成新的子进程,而新的子进程比替换掉的旧的子进程所需的内存要少一些,这样你就可以是要较少的内存处理更多的请求。MaxRequestsPerChild的默认值为0,这意味着进程永不过期。(译者注:我不知道这里讲的什么意思,没学过)。
其它web服务器最优化
为了让你的web服务器更有效的运行,这里有一些其它的措施。
Apache最优化
Apache是Drupal最常用的web服务器,通过对它进行调整可以获得更高的性能。下面的部分将建议一些可以尝试的方式。
mod_expires
这个Apache模块将让Drupal发出过期的HTTP头部,在用户的浏览器中对静态文件缓存两周,或者直到存在一个文件的新版本为止。这是用于所有的图片,CSS和JavaScript文件,和其它静态文件。最终的结果是减少带宽,而服务器需要发送的信息将会更少一些。Drupal对于和mod_expires一同工作预先进行了配置,一旦mod_expires可用,Drupal就会使用它。mod_expires的设置可以在Drupal的.htaccess文件中找到。
# Requires mod_expires to be enabled.
<IfModule mod_expires.c>
# Enable expirations.
ExpiresActive On
# Cache all files for 2 weeks after access (A).
ExpiresDefault A1209600
# Do not cache dynamically generated pages.
ExpiresByType text/html A1
</IfModule>
我们不能让mod_expires缓存HTML内容,这是由于Drupal输出的HTML内容不总是静态的。这也是Drupal拥有自己的内部缓存系统的原因,内置缓存系统可对它的HTML输出进行缓存(比如,页面缓存)。
迁移.htaccess文件
Drupal自带了两个.htaccess文件:一个位于Drupal根路径,而另一个将被自动创建,在你创建了存储上传文件的目录以后,访问Administer ➤ File system设置目录的位置,此时系统将为你自动创建一个.htaccess文件。在处理每个请求时,任何.htaccess文件都将被搜索,读取,和解析。相反,httpd.conf只在Apache启动时才被读取。Apache指令可以放在这两种文件中。如果你能够控制你自己的服务器,你应该将.htaccess文件中的内容转移到Apache主配置文件(httpd.conf)中,并通过将AllowOverride设置为None来禁用在你的web服务器根路径下查找.htaccess文件:
<Directory />
AllowOverride None
...
</Directory>
对于每个请求,这将阻止Apache穿过目录树来查找要执行的.htaccess文件。这样对于每个请求,Apache要做的工作就会有所减少,这就使得它能够处理更多请求。
其它的Web服务器
另一种选项是使用另一个服务器来代替Apache。Benchmarks已经说明了这一点,例如,LightTPD web服务器一般情况下每秒能够为Drupal处理更多的请求。更多详细比较,参看http://buytaert.net/drupal-webserver-configurations-compared。
Database Bottlenecks
数据库瓶颈
Drupal需要进行大量的数据库操作,特别是对于验证的用户和定制的模块。数据库常常会成为产生瓶颈的原因。这里有一些基本的策略用于优化Drupal中数据库的使用。
启用MySQL的查询语句缓存
MySQL是Drupal最常用的数据库。它具有在内存中缓存常用查询语句的能力,这样一个给定的查询语句再次被调用时,MySQL将立即从缓存中将其返回。然而,在大多数MySQL中,这一特性默认是被禁用的。为了启用它,向你的MySQL配置选项文件添加下列代码;该文件的名称为my.cnf,它用来声明变量和你的MySQL服务器的行为(参看http://dev.mysql.com/doc/refman/5.1/en/option-files.html)。在这里,我们将查询语句缓存设为64MB:
# The MySQL server
[mysqld]
query_cache_size=64M
当前的查询语句缓存的大小可以通过MySQL的SHOW VARIABLES命令的输入来查看:
mysql>SHOW VARIABLES;
...
| query_cache_size | 67108864
| query_cache_type | ON
...
不断的试验查询语句缓存的大小通常是有用的。缓存太小就意味着缓存了的查询语句很快就会过期。缓存太大就意味着搜索一个缓存可能需要花费相对较长的时间;还有就是使用内存进行缓存比使用其它一些方式要好,比如更多的web服务器处理或者操作系统的文件缓存。
提示 访问Administer ➤ Logs ➤ Status report,点击MySQL版本号,来快速浏览一些更重要的MySQL变量的值。你也可以从该页检查查询语句缓存是否被启用了。
识别耗费资源查询
如果你想了解在生成一个给定页面时都发生了什么,那么devel.module就会非常有用。它拥有一个选项,用来展示生成页面所用到的所有的查询语句,以及每个查询所用的时间。关于如何使用devel.module,通过EXPLAIN语法来识别和优化数据库查询的更详细的讨论,参看第21章。
找出执行时间过长的查询的另一种方式是,在MySQL中启用缓慢查询日志。为了启用它,需要在MySQL的配置选项文件(my.cnf)中这样设置:
# The MySQL server
[mysqld]
log-slow-queries
这会将超过10秒的查询记录到MySQL数据目录中的日志文件example.com-slow.log中去。你可以修改秒数以及日志的位置,如下面的代码所示,这里我们将缓慢查询的最小值设为5秒:
# The MySQL server
[mysqld]
long_query_time = 5
log-slow-queries = /var/log/mysql/example-slow.log
识别耗费资源的页面
为了找出哪些页面是最耗费资源的,需要启用Drupal自带的统计模块。尽管统计模块增加了你的服务器的负担(由于它将你的站点的访问统计记录到了数据库中),但它能够帮助我们找出哪些页面的访问量最大,对这些页面我们要进行更多的优化。它也可以用来追踪一个时期内的生成页面的总的时间,你可以在Administer ➤ Logs ➤ Access log settings中进行声明。这对于识别耗费系统资源的不能控制的网络爬虫非常有用,通过访问Administer ➤ Logs ➤ Top visitors并点击“ban”(“禁用”)来当场禁止该网络爬虫的访问。你还需要小心一点——你有时候会很容易的禁用掉一个好的网络爬虫,它能够给你的站点带来访问量。在禁止网络爬虫以前,你要确保调查了它的出处。
优化查询
看一下下面耗费资源的代码:
// Very expensive, silly way to get node titles. First we get the node IDs.
$sql = "SELECT n.nid FROM {node} n WHERE n.status = 1";
// We wrap our node query in db_rewrite_sql() so that node access is respected.
$result = db_rewrite_sql(db_query($sql));
// Now we do a node_load() on each individual node.
while ($data = db_fetch_object($result)) {
$node = node_load($data->nid);
$titles[$node->nid] = $node->title;
}
完全加载一个节点是一个耗费资源的操作:运行钩子函数,模块处理数据库查询来添加或者修改节点,使用内存来在node_load()内部缓存中缓存节点。如果你不依赖于某一模块对节点的修改,直接对节点表进行你自己的查询,速度将会更快。当然这仅仅是一个人为的例子,但是常常会遇到同样的模式,也就是,常常数据是通过多个查询来取回的,而实际上可以将多个查询合并成一个简单的查询,或者不需要加载整个节点。
提示 Drupal拥有一个内部的缓存机制(使用静态变量),当在一个请求中多次记载同一节点时使用这一机制。例如,如果调用了node_load(1)。节点1将被完全加载并被缓存。当在同一个web请求中再次调用node_load(1)时,Drupal将会返回前面使用相同节点ID加载节点的缓存过结果。
作为一个实际的例子,假定你的站点拥有一个很大的分类,而你又想为每个词语(term)展示一列节点。回想一下在第14章“使用一个定制查询根据词语对内容分类”部分中的例子的代码,它使用一个单独的查询(尽管复杂)来取得所有的东西。将其与使用分类(taxonomy)模块函数taxonomy_select_nodes()的代码进行比较,其中taxonomy_select_nodes()为每个词语进行以下查询($tids是词语ID列表):
foreach ($tids as $index => $tid) {
// taxonomy_get_term() executes a database query.
$term = taxonomy_get_term($tid);
// taxonomy_get_tree() executes a database query.
$tree = taxonomy_get_tree($term->vid, $tid, -1, $depth);
$descendant_tids[] = array_merge(array($tid),
array_map('_taxonomy_get_tid_from_term', $tree));
}
如果你的分类词语的数量巨大,那么单个查询和上百个查询的区别就会非常明显了。
优化表结构
另外,SQL的缓慢可能是由第3方模块中的SQL表的不良实现引起的。例如,没有索引的列会引起查询缓慢。一个快速查看MySQL如何执行查询的方式,是从你的缓慢查询日志中取出一个查询,在其前面加上单词EXPLAIN,然后将这个查询发给MySQL。那么结果就是得到了一个显示使用了哪些索引的表。更多信息可参看MySQL的相关书籍。
手工缓存查询语句
如果你必须要进行非常昂贵的查询时,那么你可以在你的模块中亲自将结果缓存起来。关于更多Drupal缓存API的详细信息,参看第15章。
将表类型从MyISAM改为InnoDB
MySQL有两种常见的存储引擎,通常也称为表类型,它们是MyISAM 和InnoDB。Drupal默认使用MyISAM。
MyISAM使用表级别的锁机制,而InnoDB使用行级别的锁机制。锁对于数据库的完整性非常重要;它可以阻止两个数据库进程试图同时对同一数据进行更新操作。在实际中,锁机制策略的不同意味着当你对MyISAM表进行写操作时,整个表将被锁住。因此,在一个繁忙的Drupal站点上,当正在添加多个评论时,在插入一个新评论的同时所有的评论都不能被读取。而在InnoDB上,这就不是一个问题,因为只有正被插入的那一行被锁住了,从而允许其它的服务器线程对其它各行继续进行操作。然而,在MyISAM中,表的读取更快,而数据维护和恢复工具更加完善。MySQL表的存储架构的更多信息,参看http://dev.mysql.com/tech-resources/articles/storage-engine/part_1.html。
为了测试表级锁是不是引起性能缓慢的原因,你可以通过在MySQL中检查状态变量Table_locks_immediate和Table_locks_waited的值来分析对锁竞争的程度。
mysql> SHOW STATUS LIKE 'Table%';
+-----------------------+---------+
| Variable_name | Value |
+-----------------------+---------+
| Table_locks_immediate | 1151552 |
| Table_locks_waited | 15324 |
+-----------------------+---------+
Table_locks_immediate指的是能够立即获得表级锁的次数,而Table_locks_waited指的是不能立即获取表级锁而需要等待的次数。如果Table_locks_waited的值比较大的话,并且你遇到了性能问题,你可能希望将大表切分成小表;例如,你可以为一个定制模块创建一个专有的缓存(cache)表,或者通过其它方式来减小表的大小,或者减小表级锁命令的频率。对于一些表,比如cache_*,Watchdog, 和 accesslog表,减少表的大小的一种方式是减少数据的生命周期。使用Drupal的后台管理接口可以设置数据的生命周期。还有,确保每小时能够运行一次cron,从而能够不断的清理这些表中的过期数据。
因为Drupal可以运行在不同的应用下,所以不可能一刀切的具体到某个表就应该使用某个表引擎。然而,一般情况下,适合转变为InnoDB的表有cache, watchdog, sessions, 和 accesslog 表。幸运的是,转变到InnoDB上非常简单:
ALTER TABLE accesslog TYPE='InnoDB';
当然,这一转变应该在站点下线并且已经为你的数据做好备份时进行,而且你也应该首先知道InnoDB表的不同的特性。
注意 由于Drupal对于InnoDB表仍然使用LOCK TABLE命令,你应该确保禁用了MySQL的自动提交模式,否则MySQL 和 InnoDB都将采用表级锁。更多信息参看http://dev.mysql.com/doc/refman/5.1/en/lock-tables.html。
关于MySQL的性能调优,参看http://www.day32.com/MySQL/的性能调优脚本,这里提供了调整MySQL服务器变量的建议。
Memcached(内存对象缓存)
当数据必须使用缓慢的设备比如一个硬盘进行交互时,系统通常会遇到一个性能问题。如果你能够为数据绕过这一操作,而且你能够承受的起数据的丢失(比如session数据),那会怎么样呢?此时我们可以使用memcached,这个系统将读写操作都放到内存中进行。与本章中介绍了其它解决方案相比,Memcached更加复杂,而且更难设定。,但是当你的系统需要在可升级性方面有所提高时还是值得考虑这一方案的。
Drupal有一个内置的数据库缓存用来缓存页面,菜单,和其它Drupal数据,而MySQL数据库也能够缓存常用查询,但是当你的数据库不堪重负时那会怎样?你可以再买一台数据库服务器,或者你也可以直接将数据存放在内存中而不是数据库中从而完全减轻数据库的重负。Memcached库(see http://www.danga.com/memcached/)和PECL Memcache PHP 扩展 (see http://pecl.php.net/package/memcache)都是专门为你做这件事的工具。
Memcached将任意数据都保存在随即存取的内存中,而且能够迅速的从中读取数据。使用这种方式比任何使用磁盘的方式在性能上都要好一些。Memcached存储对象并使用唯一的键来引用对象。哪些对象应该被放到memcached中,这由程序员决定。对放到Memcached中的对象,Memcached不知对象的类型和本质;在它眼中,一切都是一堆比特,带有键并且等待取回。
系统的简单性是它的优点。当为Drupal编写支持memcached的代码时,开发者可以决定对任何引起瓶颈的主要因素进行缓存。这可能是运行过于频繁的数据库查询的结果,比如路径查找,或者甚至更复杂的构造比如完全加载的节点和分类词汇,这些都需要许多数据库查询和大量的PHP处理才能得到。
Memcached的不足之处是它仅对于一小部分Drupal用户适用——他们的站点非常的流行以至于普通的硬件不能满足其需求——因此用于决定缓存什么和什么时候缓存的逻辑一直没有直接放到Drupal(内核)中去。替代的是,任何想要构建一个异常快速的Drupal站点的人,必须要在Drupal内核打上一系列的补丁。这些补丁,以及Drupal的memcache模块和使用PECL Memcache接口的Drupal专有API可在Drupal的Memcache工程中找到(参看 http://drupal.org/project/memcache)。















 3566
3566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









