






译者:老葛
根据词语(term)查看内容
你可以通过进入一个词语的URL来查看该词语下面的所有节点。例如,在URL http://example.com/?q=taxonomy/term/5,5是你希望查看的词语的term ID。结果将是一列包含了每个使用该词作为标签的节点的标题和Teaser。
在URL中使用AND和OR
构建支持AND和OR的分类(taxonomy)URL的语法为,分别使用逗号“,”和加号“+”。下面是一些例子。
指定了词语ID为5和6的所有节点的展示,使用下面的URL:
http://example.com/?q=taxonomy/term/5,6
使用下面的URL展示指定了词语ID为1或2,或者3的所有节点
http://example.com/?q=taxonomy/term/1+2+3
taxonomy.module对混合使用AND和OR目前还没有提供支持。
提示:使用path模块,来为你这些分类URL设置用户友好的URL,这样他们后面就不会有这些令人害怕的数字了。
为多层级词汇表声明深度
在前面的例子中,我们是用了一个隐含的参数。例如,URL http://example.com/?q=taxonomy/term/5实际上是
http://example.com/?q=taxonomy/term/5/0
当为了展示准备结果集时,最后一个参数0就是所要搜索的层级数;如果参数为all时,这意味着包括所有的层级。假定你有一个多层级词汇表,如表14-3所示。
表 14-3.一个地理多层级词汇表
(子词语为它们父亲后面,缩进了)
Term ID Name
1 Canada
2 British Columbia
3 Vancouver
4 Ontario
5 Toronto
第一层级是国家(Canada);它有两个孩子,British Columbia 和 Ontario省。每一个省都包含一个孩子,一个Drupal异常活跃的加拿大的重要城市。下面是修改URL的深度参数所起到的作用。
所有标记了Vancouver的节点使用下面的URL:
http://example.com?q=taxonomy/term/3 or http://example.com?q=taxonomy/term/3/0
为了展示所有标记了British Columbia(但是没有标记Vancouver)的节点,使用下面的URL:
http://example.com?q=taxonomy/term/2
为了展示所有标记了British Columbia(包含标记Vancouver的)的节点(注意我们这里将层级深度设为了1),使用下面的URL:
http://example.com?q=taxonomy/term/2/1
任何标记了Canada或者标记了任意一个加拿大省份或者城市的节点都可使用下面的URL来展示:
http://example.com?q=taxonomy/term/1/all
注意 结果集是作为普通的节点列表展示出来的。如果你想层次化的展示节点标题或者teaser,你需要自己编写一个定制的主题函数,或者使用views模块(http://drupal.org/project/views)。
自动的RSS种子
每个词语都有一个自动的RSS种子,用来展示最近标记了该词语的节点。例如,词语ID的种子位于
http://example.com/?q=taxonomy/term/3/0/feed
注意深度参数(这里为0)是必须的.和期望的一样,你可以使用AND或者OR来联合词语构建一个联合的种子,下面是词语2 或 4的种子,包含了所有的儿子(不包括儿子的儿子。。。):
http://example.com/?q=taxonomy/term/2+4/1/feed
下面是包含所有子孙的种子:
http://example.com/?q=taxonomy/term/2+4/all/feed
分类的存储
如果你不想局限于Drupal内置的分类能力,那么这将驱使着你去理解分类是如何存储在数据库中的。在一个典型的非Drupal数据库中,你可能通过简单的向数据库表中添加一列来创建一个扁平的分类。正如你所看到的那样,Drupal使用普通的数据库表来添加一个分类。图14-4展示了数据库表结构
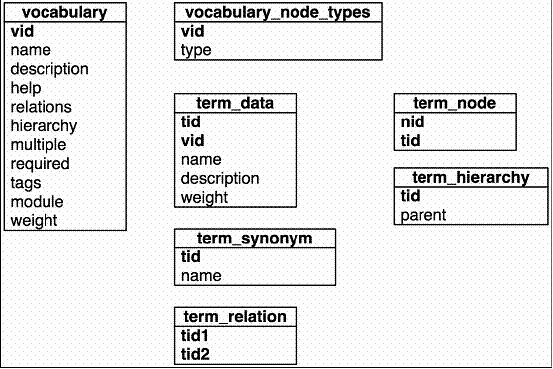
图14-4 Drupal分类的数据库表。主键使用了粗体
下列表组成了Drupal的分类存储系统:
• vocabulary:这个表存储了词汇表的相关信息,通过Drupal后台的分类接口可以修改词汇表。
• vocabulary_node_types: 这个表用来追踪一个词汇表适用于哪些节点类型。该类型是Drupal的内部节点类型名称(例如,blog),它对应于node表的type列。
• term_data: 这个表包含了词语的真实名称,它所在的词汇表,它的可选描述,以及它的重量,用来决定它在展示给用户的词语下拉选择框中的相对位置(例如,在节点提交表单中)。
• term_synonym: 这个表包含了给定词语ID的同义词。
• term_relation:当定义一个词语时,这个表用来追踪与该词语有关的词语。
• term_hierarchy:这个表包含了词语的ID和它父亲的ID。如果一个词语位于根部(也就是说,它没有父亲),那么它父亲的ID为0.
• term_node: 这张表用来追踪哪些节点使用该词语标记了。
基于模块的词汇表
除了使用Drupal后台管理接口Administer ➤ Content ➤ Categories创建词汇表以外,模块也可以使用这些分类数据库表来存储它们自己的词汇表。例如,forum(论坛)模块使用这些分类数据库表来存放一个关于容器和论坛的词汇表。Image(图片)模块使用这些表来管理相册。任何时候,当你发现自己需要实现一个层级化词语时,你都需要考虑一下,如果使用taxonomy(分类)模块和基于模块的词汇表,是否会更好一些?
Vocabulary表中的module列用来标识拥有一个词汇表的模块。一般情况下,这一列包含的是taxonomy(分类),这是因为taxonomy(分类)模块管理着大多数词汇表。
创建一个基于模块的词汇表
让我们看一个基于模块的词汇表的例子。第3方的相册模块(image gallery module)使用分类来管理不同的相册。它通过代码(如下面的例子所示)创建了它自己的词汇表,并且通过将$vocabulary数组的module键设为该模块的名字(不带.module)来锁定该词汇表的所有权。
/**
* Returns (and possibly creates) a new vocabulary for Image galleries.
*/
function _image_gallery_get_vid() {
$vid = variable_get('image_gallery_nav_vocabulary', '');
if (empty($vid)) {
// Check to see if an image gallery vocabulary exists.
$vid = db_result(db_query("SELECT vid FROM {vocabulary} WHERE
module='image_gallery'"));
if (!$vid) {
$vocabulary = array(
'name' => t('Image Galleries'),
'multiple' => '0',
'required' => '0',
'hierarchy' => '1',
'relations' => '0',
'module' => 'image_gallery',
'nodes' => array(
'image' => 1
)
);
taxonomy_save_vocabulary($vocabulary);
$vid = $vocabulary['vid'];
}
variable_set('image_gallery_nav_vocabulary', $vid);
}
return $vid;
}
为词语提供定制路径
如果你的模块负责维护一个词汇表,你可能想为该模块控制的词语提供定制的路径,来代替由taxonomy.module提供的默认路径taxonomy/term/[term id]。当为一个词语生成一个连接时,调用下面列出的taxonomy.module中的函数(你应该调用这个函数,而不是自己为分类词语创建链接;不要假定taxonomy(分类)模块维护了一个分类)。注意,在下面的代码中是如何检查拥有该词汇表的模块的:
/**
* For vocabularies not maintained by taxonomy.module, give the maintaining
* module a chance to provide a path for terms in that vocabulary.
*
* @param $term
* A term object.
* @return
* An internal Drupal path.
*/
function taxonomy_term_path($term) {
$vocabulary = taxonomy_get_vocabulary($term->vid);
if ($vocabulary->module != 'taxonomy' &&
$path = module_invoke($vocabulary->module, 'term_path', $term)) {
return $path;
}
return 'taxonomy/term/'. $term->tid;
}
例如,image_gallery.module将路径重定向到了image/tid/[term id]:
function image_gallery_term_path($term) {
return 'image/tid/'. $term->tid;
}
使用hook_taxonomy()来获悉词汇表的修改
如果你自己的模块维护了一个词汇表,当使用标准的分类用户接口修改你的词汇表时,你想收到词汇表的相应修改信息。对于由taxonomy.module维护的已存在的一个词汇表,当它被修改时,你也想收到相应的修改信息。在任何一种情况下,通过实现hook_taxonomy(),当词汇表修改时都会通知你。下面的模块实现了hook_taxonomy(),当词汇表修改时,将会使用e-mail通知你。下面是taxonomymonitor.info文件:
; $Id$
name = Taxonomy Monitor
description = Sends email to notify of changes to taxonomy vocabularies.
dependencies = taxonomy
version = $Name$
下面是taxonomymonitor.module:
<?php
// $Id$
/**
* Implementation of hook_taxonomy().
*
* Sends email when changes to vocabularies or terms occur.
*/
function taxonomymonitor_taxonomy($op, $type, $array = array()) {
$to = 'me@example.com';
$name = check_plain($array['name']);
// $type is either 'vocabulary' or 'term'.
switch ($type) {
case 'vocabulary':
switch($op) {
case 'insert':
$subject = t('Vocabulary @voc was added.', array('@voc' => $name));
break;
case 'update':
$subject = t('Vocabulary @voc was changed.', array('@voc' => $name));
break;
case 'delete':
$subject = t('Vocabulary @voc was deleted.', array('@voc' => $name));
break;
}
break;
case 'term':
switch($op) {
case 'insert':
$subject = t('Term @term was added.', array('@term' => $name));
break;
case 'update':
$subject = t('Term @term was changed.', array('@term' => $name));
break;
case 'delete':
$subject = t('Term @term was deleted.', array('@term' => $name));
break;
}
}
// Dump the vocabulary or term information out and send it along.
$body = print_r($array, TRUE);
// Send the email.
drupal_mail('taxonomymonitor-notify', $to, $subject, $body);
}
你可以做的更多,比如通过修改这一模块,将修改者的名字也包含进来。
常见任务
当你使用分类时,下面是你可能遇到的常见任务。
在一个节点对象中查找分类词语
通过在taxonomy.module中实现hook_nodeapi(),分类词语将在node_load()期间被加载到节点对象中。这将会在节点中产生一个以taxonomy(分类)为键的词语对象数组:
print_r($node->taxonomy);
Array (
[3] => stdClass Object (
[tid] => 3
[vid] => 1
[name] => Vancouver
[description] => By Land, Sea, and Air we Prosper.
[weight] => 0 )
)
为一个节点ID得到所有相关词语
如果你知道节点ID,但你还没有完全加载整个节点对象,当你仅仅想要关联的词语时,那么加载整个节点对象就是耗费资源的,同时也是没有必要的;你可以这样做:
$nid = 3;
$terms = taxonomy_node_get_terms($nid);
结果如下:
Array (
[7] => stdClass Object (
[tid] => 7
[vid] => 3
[name] => Apple
[description] => maker of shiny things
[weight] => 0 )
[8] => stdClass Object (
[tid] => 8
[vid] => 3
[name] => Lenovo
[description] => known for laptops
[weight] => 0 )
)
构建你自己的分类查询
如果你需要生成某些分类的一个节点列表,你最终可能希望一切都简单一些;你可能希望Drupal在node表中保存了分类词语,因此你就可以这样写SQL了:
SELECT * FROM node WHERE vocabulary = 1 and term = 'cheeseburger'
灵活性的代价是Drupal开发者需要做更多一些工作。在Drupal中你不能使用这么简单的查询,你必须学习使用JOIN来直接对分类表进行查询。
使用taxonomy_select_nodes()
在你开始编写一个查询以前,考虑一下,使用一个已存在的函数是否也能够得到你想要的。例如,如果你想得到由词语ID 5和6标记的所有节点的标题,你可以使用taxonomy_select_nodes():
$tids = array(5, 6);
$result = taxonomy_select_nodes($tids, 'and');
$titles = array();
while ($data = db_fetch_object($result)) {
$titles[] = $data->title;
}
使用一个定制查询根据词语对结果分组
使用taxonomy_select_nodes()意味着执行大量的数据库查询。如果你的词汇表比较大,那么使用一个单个查询来获取结果,效率会更高一些,但是这也更复杂一点。如果你最终决定直接对分类表进行查询,记住一定要将查询封装在db_rewrite_sql()中,这样任何实现了访问控制的模块都可以对查询进行合适的限制。
在下面的例子中,你的目的是输出一列分类词语作为大标题,由该词语标记的所有节点的标题将作为一个无序列表放在大标题的下面:
$vid = 3;
$sql = db_rewrite_sql("
SELECT n.nid, d.tid, d.name, n.title, n.created
FROM {term_data} d
INNER JOIN {term_node} t on t.tid = d.tid
LEFT JOIN {node} n on t.nid = n.nid
WHERE d.vid = %d
AND n.type = 'page'
ORDER BY d.name ASC, n.created DESC",
'n', 'nid');
// Eliminate the DISTINCT that db_rewrite_sql() inserted.
$sql = str_replace('DISTINCT(n.nid)', 'n.nid', $sql);
// Do the query, inserting our vocabulary ID.
$result = db_query($sql, $vid);
$last = '';
while ($data = db_fetch_object($result)) {
$month = format_date($data->created, 'custom', 'm/Y'); // e.g., 3/2007
if ($last == $data->name) {
$output .= '<li>' . l($data->title, "node/$data->nid") . " ($month)</li>";
}
else {
if ($last) {
$output .= '</ul>';
}
$last = $data->name;
$output .= '<h3>' . check_plain($data->name) . '</h3>';
$output .= '<ul>';
$output .= '<li>' . l($data->title, "node/$data->nid") . " ($month)</li>";
}
}
$output .= '</ul>';
return $output;
这种方式的好处是他仅包含一个单独的数据库查询。该例的输出很简单,就是一些列的以词语为大标题的无序列表,如图14-5所示。

图14-5 前面代码的输出。每个词语是一个大标题,而由该词语标记的节点出现在下方的无序列表中
在你的SQL语句中你调用了db_rewrite_sql()。这样,它就可以修改SQL,对于受到访问控制保护的节点将不会被包含在列表中,除非用户具有合适的权限。然而,db_rewrite_sql()向n.nid列添加了一个DISTINCT关键字。一般情况下,这就是想要的,因为节点不应该被列出两次。然而,在我们这里,你是根据词语列出节点的,而且如果一个节点有两个词语标记的话,那么它就应该同时出现在两个词语的下面。















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









