






MPEG-1音频压缩编码
基于音频信号的特点,及人耳的听觉特性:掩蔽效应和临界频带对音频信号进行子带编码
1.音频压缩的可能性:
1. 声音信号的冗余:时域:幅度非均匀分布,小幅度的样值比大幅度的样值出现的概率高;频域:功率谱密度非均匀:低频能量高、高频能量低
2.人耳的听觉特性:声音中与“听觉”不相关的东西可以不采样、不编码、不传输.
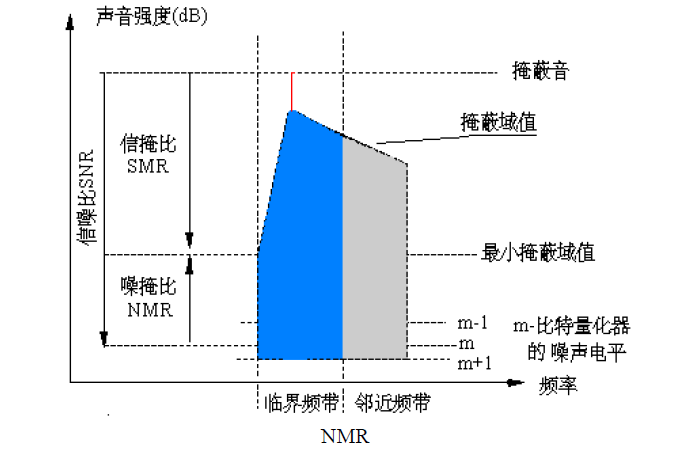
2. 人耳的听觉掩蔽效应:一个强纯音会掩蔽在其附近同时发声的弱纯音,听觉阈值电平是自适应的,随声音频率的变化而变化。

掩蔽的类型:由乐音信号和窄带噪声组合。乐音信号和窄带噪声作为掩蔽音时产生的掩蔽效果不同
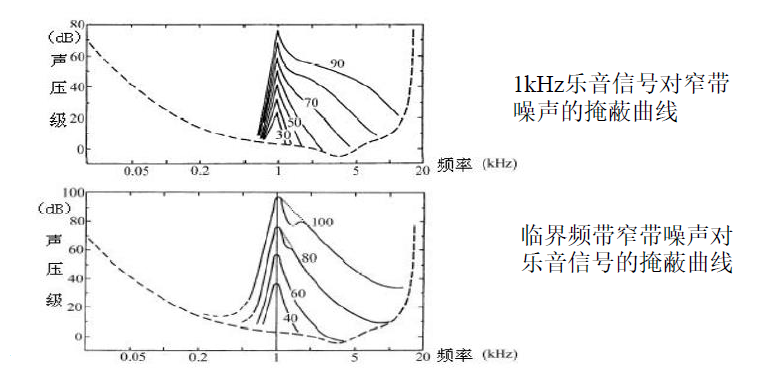
如果有多个频率成分的复杂信号存在,频谱的总掩蔽阈值与频率的关系取决于个掩蔽音的强度,频率及之间的距离
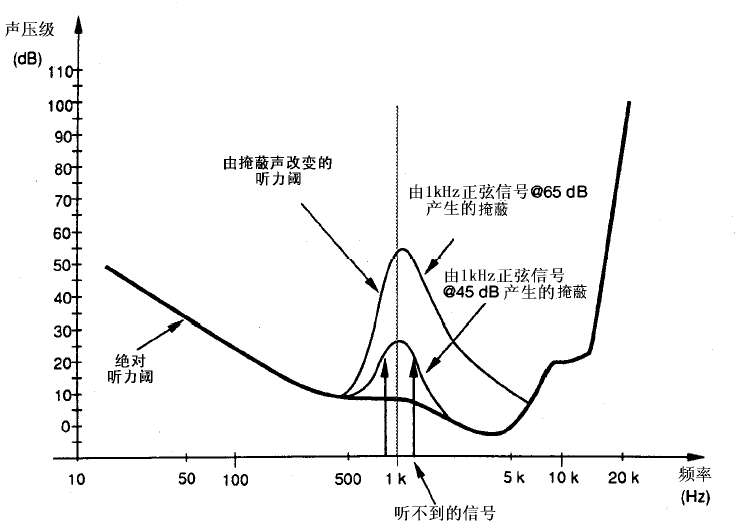
掩蔽效应的利用:去除被掩蔽的信号分量,不理会可能被掩蔽的量化噪声.
3.临界频带:当某个纯音被以它为中心频率、且具有一定带宽的连续噪声所掩蔽时,如果该纯音刚好被听到时的功率等于这一频带内的噪声功率,这个带宽为临界频带宽度。
人类听觉系统相当于一个在0KHz~20KHz范围内一个由25个重叠的带通滤波器组成的滤波器组。人耳不能区分同一个频带内同时发生的不同声音。临界频带的宽度用bark来衡量,500Hz以下临界频带宽度约为100Hz,从500Hz起临界频带带宽线性增加。
4.子带编码的基本思想:使用一组带通滤波器将输入的音频信号分成若干个连续的频带,即子带,对每个子带单独量化编码。复合起来送入信道传输。在接收端,对每个子带单独解码,再复合起来组成原始信号。
理想的频带分割应该模仿临界频带,即各子带的宽度不一致,随频率的升高而增加。
每个子带根据各自的信号掩蔽比确定相应的量化级数,分配比特使量化噪声和掩蔽阈值越接近,数据压缩越充分。
子带越多越窄,相同音质下编码所得的数据率越低。
5.MPEG-1音频压缩的流程:
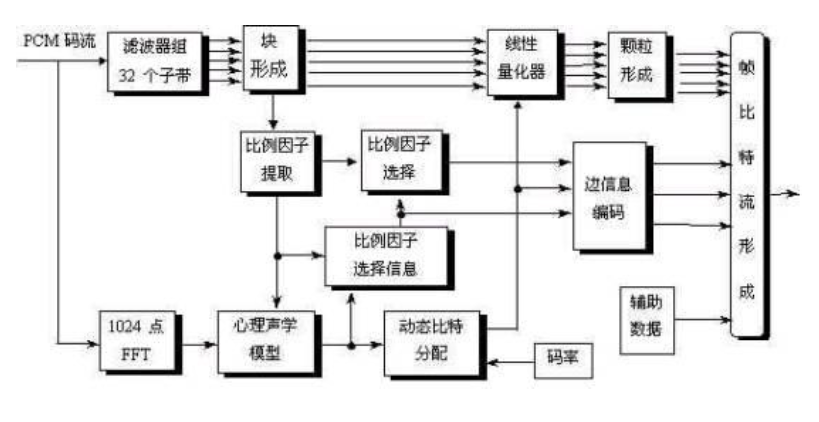
1. 多相滤波器组:分割子带,分成32个等宽的子带
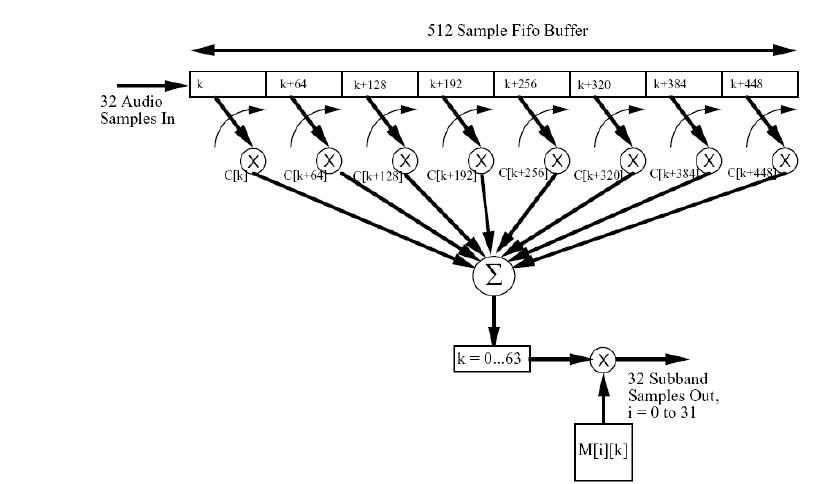
最低频的滤波器为低通滤波器,其余为带通滤波器
缺点:
1.等带宽的滤波器组与人类听觉系统的临界频带不对应,低频区单个子带会覆盖过个临界频带,此时量化比特数不能兼顾每个子带
2.滤波器组及其逆过程会引入较小的失真。
3.相邻子带间有频谱混叠
2.快速傅里叶变换::为满足掩蔽阈计算所需的精确的频谱分析,提高低频率范围的频率分辨率,与听觉特性相适应。
MPEG的layer1:512点的FFT,采样频率为48KHz时,频率分辨率为93.75Hz.layer2:1024点FFT。Layer1每帧384个样值,512个样本足够覆盖。Layer2每帧1152个样值,每帧计算两次。
3.心理声学模型:依据快速傅里叶变换的输出计算信号掩蔽比SMR,并将其传递到编码单元。
4.提取比例因子:
layer1:对各个子带每12个样点进行一次比例因子计算。先定出12个样点中绝对值的最大值。查比例因子表中比这个最大值大的最小值作为比例因子。
Layer2:每个子带有36个样值。将每个子带中的三个比例因子一起考虑,划分成集中特定模式,1个、2个或3个比例因子和比例因子选择信息一起传送,以降低码率。
5.动态比特分配:在调整到固定码率之前,确定可用于样值编码的有效比特数,这取决于比例因子,比例因子选择信息,比特分配信息和辅助数据所需要的比特数。
比特分配,依据已经计算出的SMR和标准给定的SNR计算出掩蔽噪声比MNR=SNR-SMR。比特分配使每帧和帧中的每个子带的掩蔽噪声比最小。是一个循环的过程:对最低MNR的子带分配比特,使获益最大的子带的两户级别增加一级,并重新计算分配了更多比特的子带的MNR。
6.成帧:为降低解码的复杂性、减少延时,便于编辑,对码流进行如下方式的组织:
Layer1:

layer2:
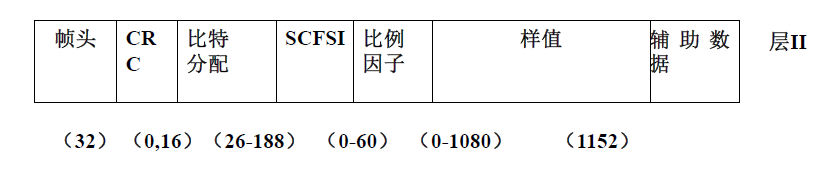
帧头:32比特,包含同步和状态信息,layer1和layer2相同
循环冗余校验:16比特,做误码检验,layer1和layer2相同
比特分配:4比特,告知解码器每个样值用了多少比特来编码
比例因子:6比特,比例因子是否出现取决于对应的比特分配的数值
比例因子选择信息:layer2中出现,layer2中每个子带方分成3个组,每组12个样值,每个子带对应3个比例因子,传输比例因子选择信息。
样值:layer1:32个子带,每个子带12个样值,共384个,抽样频率为48KHz时,每个音频帧长8ms;layer2:32个子带,每个子带有3个组,每组12个样值,抽样频率为48KHz时,音频帧长为24ms。
辅助数据:传输附加数据信息6.实验结果
以match2文件为例:
创建信息文件
char *textname="match2_info.txt";
FILE *textfile=fopen(textname,"wb");输出音频的采样码率及目标码率:
fprintf(textfile,"sampling_frequency:%d KHz\r\n",header.sampling_frequency); fprintf(textfile,"bitrate:%d KHz\r\n", bitrate[header.version][header.bitrate_index]);输出
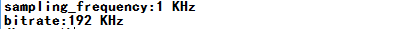
选择第150帧:
fprintf(textfile,"available bits:%d\r\n", adb);
fprintf(textfile,"channel num:%d\r\n", nch);
//scalefactor[sf_index[ch][gr][sb]]
for(ch=0;ch<nch;ch++)
{
fprintf(textfile,"channel:%d\r\n",ch+1);
for(sb=0;sb<frame.sblimit;sb++)
{
fprintf(textfile,"sub band:%d\t",sb+1);
for( gr=0;gr<3;gr++)
{
fprintf(textfile,"%d\t",scalar[ch][gr][sb]);
}
fprintf(textfile,"\r\n");
}
}


比特分配:
if(frameNum==150)
{
fprintf(textfile,"bit allocation:\r\n");
for(ch=0;ch<nch;ch++)
{
fprintf(textfile,"channel:%d\r\n",ch+1);
for(sb=0;sb<frame.sblimit;sb++)
{
fprintf(textfile,"sub band:%d\t",sb+1);
fprintf(textfile,"%d\r\n",bit_alloc[ch][sb]);
}
}
}
实验中将帧数选择为第150帧,对于match2.WAV文件和test.wav文件没有问题,但对于START.WAV文件,信息文件中没有任何写入,因此将frameNum设为较小的10。


多相滤波器将输入的音频信号分成32个子带,每个子带分别计算SMR和MNR进行比例因子选择和比特分配,查看输出文件,发现match2.WAV文件只有27个子带有比特分配信息,START.WAV和test.wav有30个子带有对应的 比特分配信息,说明一些子带并没有进行编码传输。















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









