







一.相关知识及公式
1.信息熵
熵是信息的度量单位,香农将信息定义为“用来消除不确定性的东西”。
信息熵用H表示,单位是比特/符号,对任意一个随机变量X,熵定义如下:

变量的不确定性越大,信息熵越大,即了解它需要的信息越多
2.huffman编码:一种无失真的变长编码方式(VLC)
基于信源的概率统计模型,大概率的信源符号编短码,小概率的信源符号编长码。
使用二叉树结构,编出的码是即时码。
3.huffman码编码方法
1.将文件以ASCII字符流的形式读入,统计每个符号发生的概率
2.将所有文件中出现过的字 符按照频率 从小到大的顺序排列
3.每一次选出最小的两个值, 作为二叉树的两个叶子节点,将和作为它们的根节点,两个叶子结点不参与比较,根节点参与比较
4.重复步骤三,直到得到和是1的根节点
5.将形成的二叉树左节点标 0,右节点标1,把从最上面的根节点到最下面的叶子节点途中遇到的 0,1序列串起来,就得到了各个符号的编码 。
二.实验过程
使用二叉树数据结构实现编码
1.huffman结点结构
typedef struct huffman_node_tag
{
unsigned char isLeaf;//是否为叶结点
unsigned long count;//信源出现频数
struct huffman_node_tag *parent;//父结点(结构体)指针
//如果不是树叶,此项为左,右结点的指针,否则为某个信源符号
/*union:与struct相似,维护足够的空间来放置多个数据成员的一种,
同一时间只能存储其中的一个数据成员,而不是为每一个数据成员都配置空间*/
union
{
struct
{
struct huffman_node_tag *zero, *one;//zero:左结点,one:右结点 指针
};
unsigned char symbol;//信源符号
};
} huffman_node;
2.huffman码字结点
typedef struct huffman_code_tag
{
/* 码字长度numbits,用来记录从leaf--->root一共走了多少步.
及叶子节点对应字符的编码长度*/
unsigned long numbits;
/* bits用来存储编码,以Byte为单位,
而编码是以bit为单位的, 所以需要根据 numbits 去从 bits 里提取出前numbits 个bit。
numbits 和 bits是有关系的, bits一定不可能超过 numbits/8 */
unsigned char *bits;//位
} huffman_code;
具体的编码流程:
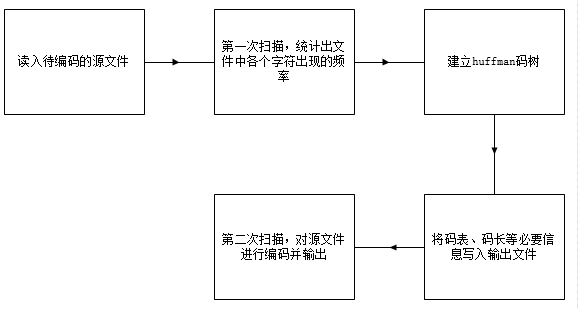
编码函数:
int huffman_encode_file(FILE *in, FILE *out, FILE *out_Table)
{
SymbolFrequencies sf;//用于存储字符频率
SymbolEncoder *se;//存放编码的码字
huffman_node *root = NULL;//根节点
int rc;
unsigned int symbol_count;//字符频数
//
huffman_stat hs;//输出数据结构体
//
/* 计算输入文件中字符出现的总频数 */
symbol_count = get_symbol_frequencies(&sf, in); //
// 依据统计到的频数计算字符对应的频率
huffST_getSymFrequencies(&sf,&hs,symbol_count);
//
/* Build an optimal table from the symbolCount. */
//创建huffman码树
se = calculate_huffman_codes(&sf);
root = sf[0];//根节点
// 获得码字并输出到列表
huffST_getcodeword(se, &hs);
output_huffman_statistics(&hs,out_Table);
//
/* Scan the file again and, using the table
previously built, encode it into the output file. */
//将文件内部的指针重新指向输入文件流的开头
rewind(in);
//将字符频数、码表等写入到输出列表
rc = write_code_table(out, se, symbol_count);//写入成功返回0
//写入成功后进行第二次扫描,对源文件进行编码输出
if(rc == 0)
rc = do_file_encode(in, out, se);
/* Free the Huffman tree and the code. */
free_huffman_tree(root);
free_encoder(se);
return rc;
}
1:读入待编码的文件
//给定输入文件,打开
if(file_in)
{
in = fopen(file_in, "rb");
if(!in)
{
fprintf(stderr,
"Can't open input file '%s': %s\n",
file_in, strerror(errno));
return 1;
}
}
//创建输出文件并打开
if(file_out)
{
out = fopen(file_out, "wb");
if(!out)
{
fprintf(stderr,
"Can't open output file '%s': %s\n",
file_out, strerror(errno));
return 1;
}
}
2:创建用于存储字符频率和码字的结构体:
typedef huffman_node* SymbolFrequencies[MAX_SYMBOLS]; typedef huffman_code* SymbolEncoder[MAX_SYMBOLS];其中:
#define MAX_SYMBOLS 256
//huffman statistics huffman编码的统计结果
typedef struct huffman_statistics_result
{
float freq[256];
unsigned long numbits[256];
unsigned char bits[256][100];
}huffman_stat;
3:统计字符出现的频数并创建结点:
//扫描FILE对象,计算FILE对象内的各个字符出现的频率
static unsigned int
get_symbol_frequencies(SymbolFrequencies *pSF, FILE *in)
{
int c;
unsigned int total_count = 0;// FILE对象内的字符总数
/* 初始化频率为0. */
init_frequencies(pSF);
/* Count the frequency of each symbol in the input file. */
while((c = fgetc(in)) != EOF)//扫描输入文件,EOF:即-1,表示文件结束
{
unsigned char uc = c;
//(*pSF)[uc]表示一个字符uc出现的频次 如果这个字符没有出现过则为这个字符建立一个叶子
if(!(*pSF)[uc])
(*pSF)[uc] = new_leaf_node(uc);
//uc字符huffman_node的count自加
++(*pSF)[uc]->count;
++total_count;//总数也自加
}
return total_count;//返回值是字符的总数
}
叶子结点:
new_leaf_node(unsigned char symbol)
{
huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node));
p->isLeaf = 1;//1代表是叶子结点
p->symbol = symbol;// symbol : 该叶子节点表示的字符
p->count = 0;
p->parent = 0;
return p;
}
4.依据统计的频数计算字符相应的频率
int huffST_getSymFrequencies(SymbolFrequencies *SF, huffman_stat *st,int total_count)
{
int i,count =0;
for(i = 0; i < MAX_SYMBOLS; ++i)
{
if((*SF)[i])//字符出现的频率不为0
{
//计算该字符出现的频率存储在结构体huffman_stat中
st->freq[i]=(float)(*SF)[i]->count/total_count;
count+=(*SF)[i]->count;//所有出现的字符的次数之和,目的是为了遍历
}
else
{
st->freq[i]= 0;//该字符出现的频率为0
}
}
if(count==total_count)//遍历了整个文件中的所有字符
return 1;
else
return 0;
}
5.按照字符频率从小到大的顺序建立码树
//建立huffman码树
static SymbolEncoder*
calculate_huffman_codes(SymbolFrequencies * pSF)
{
unsigned int i = 0;
unsigned int n = 0;
huffman_node *m1 = NULL, *m2 = NULL;//m1:左结点 m2:右结点
SymbolEncoder *pSE = NULL;//存放码字的指针
#if 1
printf("BEFORE SORT\n");
print_freqs(pSF); //演示堆栈的使用
#endif
/* Sort the symbol frequency array by ascending frequency.
以symbol频率为依据做升序排列*/
qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp);
#if 1
printf("AFTER SORT\n");
print_freqs(pSF);
#endif
/* Get the number of symbols. */
//计算当前待编码文件中信源符号的总数
for(n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n)//&&:逻辑与
;
/*Construct a Huffman tree.
* Note that this implementation uses a simple count instead of probability.
*/
//使用计数而不是概率
for(i = 0; i < n - 1; ++i)//循环n-1次
{
/* m1,m2设置为频率最低的信源符号 */
m1 = (*pSF)[0];
m2 = (*pSF)[1];
/* 将m1,m2合并成一个huffman结点(非叶结点),存到数组中,
左右结点分别是m1,m2,新的结点的频数是m1,m2频数之和 */
(*pSF)[0] = m1->parent = m2->parent =//将此非叶结点设置成左右结点的父结点
new_nonleaf_node(m1->count + m2->count, m1, m2);
(*pSF)[1] = NULL;//用(*pSF)[0]指向该新建结点,而将(*pSF)[1](下一个结点)置空
/* 重新排序*/
qsort((*pSF), n, sizeof((*pSF)[0]), SFComp);
}
//给码字结点指针数组分配内存空间
pSE = (SymbolEncoder*)malloc(sizeof(SymbolEncoder));
memset(pSE, 0, sizeof(SymbolEncoder));//初始化该数组
build_symbol_encoder((*pSF)[0], pSE);//以此结点为root建立huffman树
return pSE;//返回码字指针
}
主要依靠函数qsort实现;
qsort函数原型:void qsort(void*base,size_t num,size_t width,int(__cdecl*compare)(const void*,const void*));
参数1:待排序数组首地址
参数2:待
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









