







 本文详细探讨了支持向量机(SVM)的概念,包括超平面、支持向量和间隔最大化。通过优化目标的转换,介绍了如何从原始问题转化为拉格朗日乘子法形式,并处理异常点,引入松弛变量以适应不可分数据。最后,简要提及了SMO算法在优化过程中的作用。
本文详细探讨了支持向量机(SVM)的概念,包括超平面、支持向量和间隔最大化。通过优化目标的转换,介绍了如何从原始问题转化为拉格朗日乘子法形式,并处理异常点,引入松弛变量以适应不可分数据。最后,简要提及了SMO算法在优化过程中的作用。
最近在研读《机器学习实战》这本书,发现支持向量机这一章理论部分比较少,不太好理解。针对SVM,虽然有很多Python的库可以调用,但是在理论方面还是需要好好研究一下的。
基本概念
- 超平面:分类的决策边界
- 支持向量:离分割超平面最近的那些点
- 间隔(margin):支持向量到分割超平面的距离
- 目标:最大化间隔
优化目标
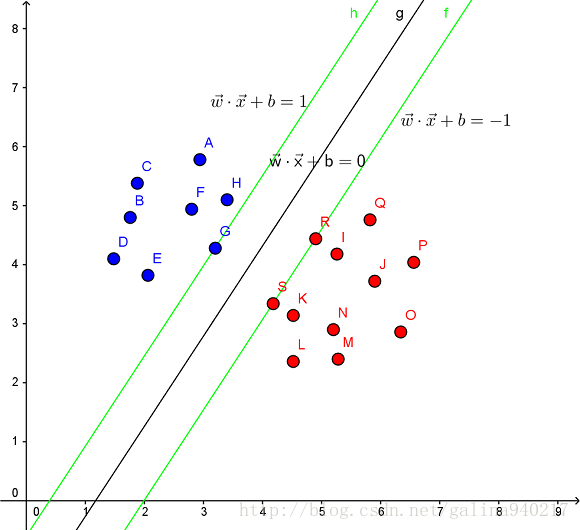
为了最大化支持向量到分隔面的距离(找到最小间隔的数据点,即支持向量,然后对该间隔最大化),可以写作:
argmaxw,b{minn(label⋅(wTx+b))⋅1||w||}
subject to:
label⋅f(x)=label⋅(wTx+b)≥1,i=1,2,...,n
其中,
label
为类别标签,±1,是点
x
的分类值;
1||w||
是为了防止
label⋅(wTx+b)
随着w和b等比例增大。
支持向量使得上述约束条件的等号成立,因此该问题可以转换为:
argmaxw,b{1||w||}
subject to:
label⋅(wTx+b)≥1,i=1,2,...,n
再做一次等价转换,得到:
argminw,b{12||w||2}
subject to:
label⋅(wTx+b)≥1,i=1,2,...,n
简化问题
上述问题是一个带约束的优化问题,可以采用拉格朗日乘子法,问题变为:
argmaxαW(α)=L(w,b,α)=12||w||2−∑ni=1αi(labeli(xiwT+b)−1)
subject to:
αi>=0,i=1,2,...,n
令
L(w,b,α)
对
w
和
∑ni=1αilabeli=0
w=∑ni=1αilabelixi
消除 w 后,问题变为:
subject to:
αi≥0,i=1,2,...,n
∑ni=1αilabeli=0
处理异常点
参考:机器学习算法与Python实践之(二)支持向量机(SVM)初级

如果数据不那么“干净”,即不是100%可分的,如上图所示。
对于上面说的这种偏离正常位置很远的数据点,我们称之为 outlier,它有可能是采集训练样本的时候的噪声,也有可能是某个标数据的大叔打瞌睡标错了,把正样本标成负样本了。那一般来说,如果我们直接忽略它,原来的分隔超平面还是挺好的,但是由于这个 outlier 的出现,导致分隔超平面不得不被挤歪了,同时 margin 也相应变小了。当然,更严重的情况是,如果出现右图的这种outlier,我们将无法构造出能将数据线性分开的超平面来。
为了处理这种情况,我们允许数据点在一定程度上偏离超平面。也就是允许一些点跑到H1和H2之间,也就是他们到分类面的间隔会小于1。如下图:

为了解决这个问题,引入松弛变量(slack variable)
ξ
。
约束条件变为:
wTx+b≥1−ξ,i=1,2,...,n
问题变为:
argmaxαW(α)=L(w,b,α)=∑ni=1αi−12 ∑ni,j=1αiαjlabelilabeljxTixj
subject to:
0≤αi≤C,i=1,2,...,n
∑ni=1αilabeli=0
其中,C是离群点的权重,C越大表明离群点对目标函数影响越大,也就是越不希望看到离群点。这时候,间隔也会很小。常数C用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0”这两个目标的权重。
SMO高效优化算法
SMO表示序列最小优化(Sequential Minimal Optimization)。
SMO工作原理:每次循环选取两个
α
,调整这两个值。















 5559
5559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









