







<script type="text/JavaScript"> </script> <script src="http://a.alimama.cn/inf.js" type="text/javascript"></script>
这几天又把《数据挖掘概念与技术》这本书翻出来看了看,随便做了个演示程序实现了书中的K-Means算法。也算是一种复习和积累吧。最先这个算法完全是用C#来做的,数据样本点是用的类作为其数据结构,后来在测试中发现运行速度不太理想。就改为用C++实现算法本身,然后通过C#调用(P/Invoke)C++导出的函数来完成。最终的效果如下面的图所示,图中小十字叉是聚类中心:

图一:K=5
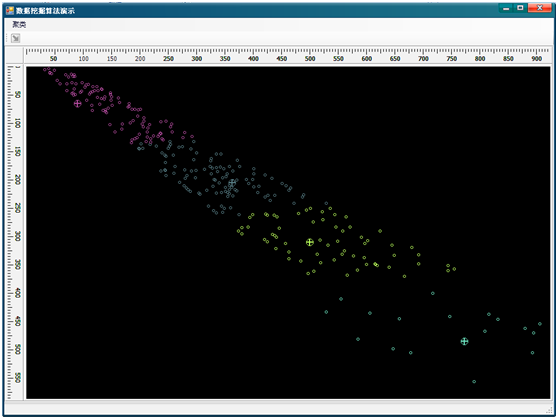
图二:K=4

图三:K=3
K-Means算法是聚类算法的一种,它通过计算样本数据点之间的逻辑距离来判断某个样本数据点属于哪一个簇,算法最终的目的是要把用于算法的样本数据点分配到K个簇中,使簇内的点有较大的相似度,而簇间的点有较小的相似度。K-Means中的K表示聚类中心的个数,在算法运行过程中,要反复扫描所有样本数据点,要计算每个非中心数据点与某个聚类中心点的距离,并将这个数据点归为与其距离最小的那个聚类中心对应的簇之中。每扫描一次就要重新计算每个聚类中心点的位置。当聚类中心点的位置变化在一定的阈值之内的时候停止处理,最后就可以得到K个簇,并且簇中每个样本数据点到本簇的中心的距离都小于到其它簇中心的距离。
现在来看看代码,解决方案中包括两个主要的项目,如图,其中SimpleKMeans.Core项目是算法的实现,是用C++ STL完成的,它用于处理二维的数据,另一个主要用于数据获取和结果显示,通过PInvoke调用算法函数并将结果图形化地显示出来:
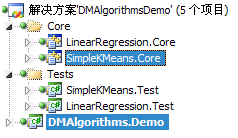
图四:选中的两个就是KMeans使用到的项目
在SimpleKMeans.Core中有一个导出的函数DataMining_KMeans。这个函数要接收C#传过来的原始数据、K值及其它参数,同时还要将处理的结果赋值给引用参数以便在C#中可以接收到处理结果。DataMining_KMeans函数的原型如下:
/*
* @Author:YinPSoft
* @param:
* raw: 原始数据
* count: 数据点个数
* K: 聚类中心个数
* means: 初始聚类中心
* minOffset: 聚类中心的最小偏移量,用于控制聚类处理的精度。
* times: 最大迭代次数
* c:每个聚类的数据点索引值
* sizes:每个聚类的容量
* finalMeans:最终的聚类中心位置
*/
void DataMining_KMeans(double* data,
int count,
int K,
int* means,
double minOffset,
int times,
int* c,
int* sizes,
double* finalMeans);
在这个原型声明中可以看到初始聚类中心点要从外部输入,而之前的版本是直接通过随机产生的。从外部输入这种方式有更大的灵活性,当有特定的初始聚类中心生成策略的时候可能通过这个策略来生成中心点,而没有策略的时候也可以通过随机来生成。初始聚类中心的值可以很大程度地影响到整个算法的效率,适当的选择聚类中心点可以减少算法的迭代次数。
接下来继续分析DataMining_KMeans函数中的代码,首先是初始化,如下面的代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









