







 本文深入探讨了ASCII码、Unicode码和UTF-8码。ASCII码使用7位表示127个基础字符;Unicode码为兼容更多字符,使用16位并兼容ASCII;UTF-8则通过变长编码节省空间,支持多语种。
本文深入探讨了ASCII码、Unicode码和UTF-8码。ASCII码使用7位表示127个基础字符;Unicode码为兼容更多字符,使用16位并兼容ASCII;UTF-8则通过变长编码节省空间,支持多语种。
浅谈 ACSII,Unicode 和 UTF-8
(文中例子的语言都是ruby)
ACSII码
最初的编码,用7bits表示127的基础字符,包括拉丁字符和数字,具体对照如下
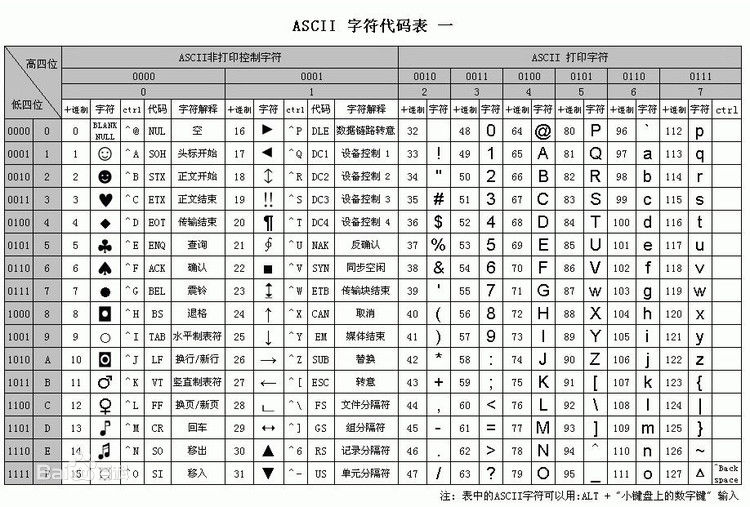
举个小例子说明
a_string = 'a'
a_string.force_encoding(Encoding::ASCII)
a_string.bytes #=> [97]
a_string.bytes[0].to_s(2) #=> '01100001' 转化为2进制Unicode码
为了加进其他符号和其他文字,比如中文和韩文等,需要扩充编码库,所以又发明了Unicode码。
其特点如下:
- 所有字符都用16bits表示
- 与ACSII码兼容,因为多出来的bits都补0
- 支持General Category
例子时间
puts "\u0061" #=> 'a'
# '0061' 是16进制数,每位分别代表4bit
# '0061' = '0000 0000 0110 0001'
# \u代表为Unicode编码
# 0061 = 97(10进制)
#下面看中文的
puts "\u4e2d" #=> '中'Unicode 编码时还考虑了其他字符属性,比如大小写等,这些附加属性就是 General Category。在正则表达式里有大用 。具体说明链接 点我
UTF-8码
Unicode虽然好,但是对存储空间有很大浪费:例如拉丁字母和数字相对于ACSII码增加了一倍的存储空间,而且世界上存储的大部分都是它们。为了解决这问题,人们又引入了UTF-8,其既可以节省ACSII码包含的字符占用的的空间,又支持多语种。
UTF-8通过下面的规则,把Unicode转化为UTF-8:
UTF-8最多可用到6个字节
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8中可以用来表示字符编码的实际位数最多有31位,即上表中x所表示的位。除去那些控制位(每字节开头的10等),这些x表示的位与UNICODE编码是一一对应的,位高低顺序也相同。
实际将UNICODE转换为UTF-8编码时应先去除高位0,然后根据所剩编码的位数决定所需最小的UTF-8编码位数。
因此那些基本ASCII字符集中的字符只需要一个字节的UTF-8编码(7个二进制位)便可以表示。
例子时间
#ruby1.9后默认编码方式是UTF-8
puts "a".unpack('B8') #=> ['01100001']
#上面是把'a'通过2进制形式显示出来,符合上表 1字节规则
puts "中".unpack('B8B8B8') #=> ["11100100", "10111000", "10101101"]
# 按照3字节规则 ,识别出的有效位 = ['01001110' '00101101']
# 换算成16进制 = 4e2d = '中'的Unicode编码谢谢观赏!















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









