







跳表是一种随机化的数据结构,基于并联的链表,它的查找效率可以红黑树相提并论(对于大多数操作需要O(log n)平均时间)。基本上,跳表是对有序的链表增加上附加的前进链接,增加十一随机化的方式进行的,所以在链表中的查找可以快速的跳过一部分链表,因此得名。所有操作都以对数的随机化时间进行。具体见图例
定义
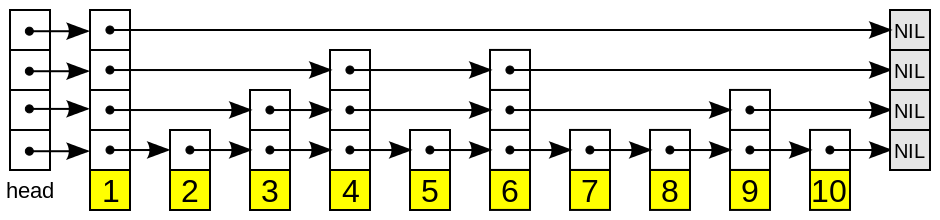
从上面的图中我们可以看出,跳表主要由以下的几个部分来组成:
- 表头(head):负责维护跳跃表的节点指针。
- 跳跃表节点:保存元素值,以及多个层。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于底层的指针,为了提高查找效率,程序总是从高层开始查找,然后随着元素值范围的缩小,慢慢层次降低。
- 表尾:全部由
NULL组成,表示跳表已经到了末尾。
正是由于跳表这样的定义,它具有下面的几个特征:
- 一个跳表应该有几层组成。
- 跳表的最底层(也就是第一层)包含所有的元素。
- 每一层都是一个有序的链表。
- 如果元素
x出现在滴i层,则所有比i小的层都包含x。
具体的描述
既然已经大致的介绍的跳表是一个什么鬼,那么下一步我们看一看它到底怎么使得查找效率和红黑树一样的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









