







~每一步中很多代码的注释都是跟着上一句写的,可以把注释连起来看~
一、实验原理
1. Huffman编码步骤
(1)统计各个符号(把文件的一个字节看成一个符号)在文件中出现的概率,按照出现概率从小到大排序。
(2)每一次选出概率最小的两个符号作为二叉树的叶节点,合并两个叶节点的概率,合并后的节点作为它们的父节点,直至合并到根节点。
(3)二叉树的左节点为0,右节点为1,从上到下由根节点到叶节点得到每个叶节点的编码。
因此,将节点和码字的数据类型定义如下
typedef struct huffman_node_tag //节点数据类型
{
unsigned char isLeaf; // 1 表示为叶节点,0 表示不是叶节点
unsigned long count; //这个字节在文件中出现的次数
struct huffman_node_tag *parent; //父节点指针
union{
struct{ //如果不是叶节点,这里为左右子节点指针
struct huffman_node_tag *zero, *one;
};
unsigned char symbol; //如果是叶节点,这里为一个字节的8位二进制数值
};
} huffman_node;
//————————————————————————————————————————————————————————
typedef struct huffman_code_tag //码字数据类型
{
unsigned long numbits; //码字长度
/* 码字,一个unsigned char可以保存8个比特位,
因此码字的第1到第8比特由低到高保存在bits[0]中,第9比特到第16比特保存在bits[1]中,以此类推 */
unsigned char *bits;
} huffman_code;2. 静态链接库的使用
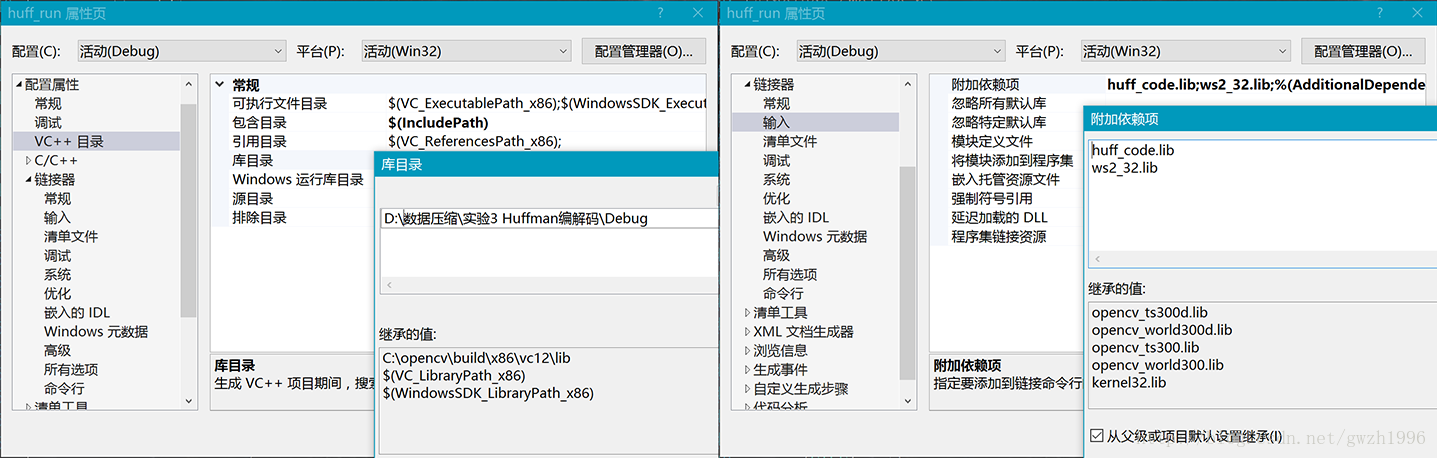
本实验由两个项目组成,第一个项目为 Huffman 编码的具体实现,名为 huff_code,创建项目时选择的是静态库,生成一个 .lib 文件。第二个项目 huff_run 只需要包含这个库即可调用其中的编码函数,后面的其它实验也要用到这个库。项目属性需要配置库目录属性,也就是第一个项目生成文件的路径,和附加依赖性属性,也就是库的名称,如图 1 所示。由于代码中用到了字节序转换的函数 htonl、ntohl,附加依赖项还需包含 ws2_32.lib。
二、实验流程及代码分析
1. Huffman编码流程
(1)读取文件
//--------huffcode.c--------
...
static void usage(FILE* out){ //命令行参数格式
fputs("Usage: huffcode [-i<input file>] [-o<output file>] [-d|-c]\n" "..." , out);
}
//————————————————————————————————————————————————————————
int main(int argc, char** argv)
{
char memory = 0; //memory表示是否对内存数据进行操作
char compress = 1; //compress为1表示编码,0表示解码
const char *file_in = NULL, *file_out = NULL;
FILE *in = stdin, *out = stdout;
while((opt = getopt(argc, argv, "i:o:cdhvm")) != -1){ //读取命令行参数的选项
switch(opt){
case 'i': file_in = optarg; break; // i 为输入文件
case 'o': file_out = optarg; break; // o 为输出文件
case 'c': compress = 1; break; // c 为压缩操作
case 'd': compress = 0; break; // d 为解压缩操作
case 'h': usage(stdout); system("pause"); return 0; // h 为输出参数用法说明
case 'v': version(stdout); system("pause"); return 0; // v 为输出版本号信息
case 'm': memory = 1; break; // m 为对内存数据进行编码
default: usage(stderr); system("pause"); return 1;
}
}
if(file_in){ //读取输入输出文件等
in = fopen(file_in, "rb"); if(!in)...
}
...
if(memory) //对内存数据进行编码或解码操作
return compress ?memory_encode_file(in, out) : memory_decode_file(in, out);
//还是对文件数据进行编码或解码操作
return compress ?huffman_encode_file(in, out) : huffman_decode_file(in, out);
} 使用库函数中的getopt解析命令行参数,这个函数的前两个参数为main中的argc和argv,第三个参数为单个字符组成的字符串,每个字符表示不同的选项,单个字符后接一个冒号,表示该选项后必须跟一个参数。
下面先分析对文件的编码流程,之后是其中具体实现各种操作的函数。
//--------huffman.c--------
...
//最大符号数目,由于一个字节一个字节进行编码,因此为256
#define MAX_SYMBOLS 256
typedef huffman_node* SymbolFrequencies[MAX_SYMBOLS]; //信源符号数组,数据类型为之前定义过的树节点类型
typedef huffman_code* SymbolEncoder[MAX_SYMBOLS]; //编码后的码字数组,数据类型为之前定义过的码字类型
//————————————————————————————————————————————————————————
int huffman_encode_file(FILE *in, FILE *out) //对文件进行Huffman编码的函数
{
SymbolFrequencies sf;
SymbolEncoder *se;
huffman_node *root = NULL;
unsigned int symbol_count = get_symbol_frequencies(&sf, in); //第一遍扫描文件,得到文件中各字节的出现频率
se = calculate_huffman_codes(&sf); //再根据得到的符号频率建立一棵Huffman树,还有Huffman码表
root = sf[0]; //编完码表后,Huffman树的根节点为 sf[0],具体原因在后面的分析
rewind(in); //回到文件开头,准备第二遍扫描文件
int rc = write_code_table(out, se, symbol_count); //先在输出文件中写入码表
if(rc == 0) rc = do_file_encode(in, out, se); //写完码表后对文件字节按照码表进行编码
free_huffman_tree(root); free_encoder(se);
return rc;
}(2)统计各字节出现的频率
static unsigned int get_symbol_frequencies(SymbolFrequencies *pSF, FILE *in) //统计中各字节出现频率的函数
{
int c; unsigned int total_count = 0;
memset(*pSF, 0, sizeof(SymbolFrequencies)); //首先把所有符号的频率设为0
while((c = fgetc(in)) != EOF) //然后读每一个字节,把一个字节看成一个信源符号,直到文件结束
{
unsigned char uc = c;
if(!(*pSF)[uc]) //如果还没有在数组里建立当前符号的信息
(*pSF)[uc] = new_leaf_node(uc); //那么把这个符号设为一个叶节点
++(*pSF)[uc]->count; //如果已经是一个叶节点了或者叶节点刚刚建立,符号数目都+1
++total_count; //总字节数+1
}
return total_count;
}
//————————————————————————————————————————————————————————
static huffman_node* new_leaf_node(unsigned char symbol) //建立一个叶节点的函数
{
huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node)); //分配一个叶节点的存储空间
p->isLeaf = 1; //表明当前节点为叶节点
p->symbol = symbol; //节点存储的信源符号
p->count = 0; //信源符号数目设为0
p->parent = 0; //父节点为空
return p;
}(3)建立码树
static SymbolEncoder* calculate_huffman_codes(SymbolFrequencies * pSF) //创建一棵Huffman树的函数
{
unsigned int i = 0, n = 0;
huffman_node *m1 = NULL, *m2 = NULL;
SymbolEncoder *pSE = NULL;
qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp); //先使用自定义的顺序对出现次数进行排序,使得下标为0的元素的count最小
for(n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n); //统计下信源符号的真实种类数,因为一个文件中不一定256种字节都会出现
for(i = 0; i < n - 1; ++i)
{
//把出现次数最少的两个信源符号节点设为 m1,m2
m1 = (*pSF)[0];
m2 = (*pSF)[1];
//然后合并这两个符号,把合并后的新节点设为这两个节点的父节点
(*pSF)[0] = m1->parent = m2->parent = new_nonleaf_node(m1->count + m2->count, m1, m2);
(*pSF)[1] = NULL; //合并之后,第二个节点为空
qsort((*pSF), n, sizeof((*pSF)[0]), SFComp); //然后再排一遍序
}
//树构造完成后,为码字数组分配内存空间并初始化
pSE = (SymbolEncoder*)malloc(sizeof(SymbolEncoder));
memset(pSE, 0, sizeof(SymbolEncoder));
build_symbol_encoder((*pSF)[0], pSE); //从树根开始,为每个符号构建码字
return pSE;
}
//————————————————————————————————————————————————————————
static int SFComp(const void *p1, const void *p2) //自定义的排序顺序函数,把节点数组由小到大排序
{
//把两个排序元素设为自定义的树节点类型
const huffman_node *hn1 = *(const huffman_node**)p1;
const huffman_node *hn2 = *(const huffman_node**)p2;
if(hn1 == NULL && hn2 == NULL) return 0; //如果两个节点都空,返回相等
if(hn1 == NULL) return 1; //如果第一个节点为空,则第二个节点大
if(hn2 == NULL) return -1; //反之第二个节点小
//如果都不空,则比较两个节点中的计数属性值,然后同上返回比较结果
if(hn1->count > hn2->count) return 1;
else if(hn1->count < hn2->count) return -1;
return 0;
}
//————————————————————————————————————————————————————————
static huffman_node* new_nonleaf_node(unsigned long count, huffman_node *zero, huffman_node *one) //建立一个内部节点的函数
{
huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node)); //分配一个节点的存储空间
p->isLeaf = 0; //内部节点,不是叶节点
//根据参数,设置这个节点的符号数和左右子节点
p->count = count; p->zero = zero; p->one = one;
p->parent = 0; //父节点设为空
return p;
} qsort为标准库中自带的快速排序函数,参数为 <待排序数组> <数组元素个数> <元素的大小> <自定义比较数组元素的函数>。
临时变量 m1,m2 不断地设为信源符号数组中出现次数最少的两个元素,数组第一个元素一直是出现次数最小的两个符号的合并,这样循环结束后,pSF 数组中所有元素除第一个 pSF[0] 以外都空,而这些新建立的节点分布在内存中各个角落,通过节点属性中的左右两个子节点指针指向各自的子节点,构建出一棵二叉树结构,把这些节点连在一起,pSF[0] 就是这棵树的根节点。因此如果要遍历这棵树,只要 pSF[0] 就够了。
(4)生成码字
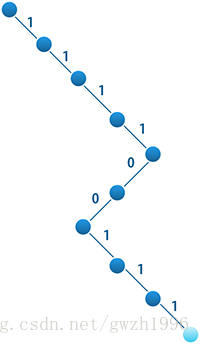
这个实验里码字的编制比较麻烦,原因在于码字数组中的一个元素为 unsigned char 类型,一个元素保存了 8 位的码字,一个码字中的一位(0或1)在存储时确实只占用了 1 bit。 假如有一个叶节点在树中的位置如图 2 所示(浅蓝色节点),那么按照编码规则码字应该从根到叶编码,为 111100111。


static void build_symbol_encoder(huffman_node *subtree, SymbolEncoder *pSE) //遍历码树的函数
{
if(subtree == NULL) return; //如果是空树,返回
if(subtree->isLeaf) //如果是叶节点,则对叶节点进行编码
(*pSE)[subtree->symbol] = new_code(subtree);
else //如果都不是,那么先访问左节点,到了叶节点之后再访问右节点
{
build_symbol_encoder(subtree->zero, pSE);
build_symbol_encoder(subtree->one, pSE);
}
}
//————————————————————————————————————————————————————————
static huffman_code* new_code(const huffman_node* leaf) //生成码字的函数
{
//码字的位数 numbits,也就是树从下到上的第几层,还有保存码字的数组 bits
unsigned long numbits = 0;
unsigned char* bits = NULL;
while(leaf && leaf->parent) //如果还没到根节点
{
//那么得到当前节点的父节点,由码字位数得到码字在字节中的位置和码字的字节数
huffman_node *parent = leaf->parent;
unsigned char cur_bit = (unsigned char)(numbits % 8);
unsigned long cur_byte = numbits / 8;
if(cur_bit == 0) //如果比特位数为0,说明到了下一个字节,新建一个字节保存后面的码字
{
size_t newSize = cur_byte + 1; //新的字节数为当前字节数+1,size_t 即为 unsigned int 类型
bits = (char*)realloc(bits, newSize); //数组按照新的字节数重新分配空间
bits[newSize - 1] = 0; //并把新增加的字节设为0
}
if(leaf == parent->one) //如果是右子节点,按照Huffman树左0右1的原则,应当把当前字节中当前位置1
//先把1右移到当前位(cur_bit)位置,再把当前字节(bits[cur_byte])与移位后的1做或操作
bits[cur_byte] |= 1 << cur_bit;
++numbits; //然后码字的位数加1
leaf = parent; //下一位码字在父节点所在的那一层
}
//回到根之后编码完毕,对码字进行倒序
if(bits)
reverse_bits(bits, numbits);
//倒序后,输出码字数组
huffman_code *p = (huffman_code*)malloc(sizeof(huffman_code));
p->numbits = numbits; p->bits = bits;
return p;
}
//————————————————————————————————————————————————————————
static void reverse_bits(unsigned char* bits, unsigned long numbits) //对码字进行倒序的函数
{
//先判断码字最多需要多少个字节存储
unsigned long numbytes = numbytes_from_numbits(numbits);
//分配字节数所需的存储空间,还有当前字节数和比特位数
unsigned char *tmp = (unsigned char*)alloca(numbytes);
unsigned long curbit;
long curbyte = 0;
memset(tmp, 0, numbytes);
for(curbit = 0; curbit < numbits; ++curbit)
{
//判断当前位是字节里的哪一位,到了下一个字节,字节数+1
unsigned int bitpos = curbit % 8;
if(curbit > 0 && curbit % 8 == 0) ++curbyte;
//从后往前取码字中的每一位,再移位到所在字节的正确位置
tmp[curbyte] |= (get_bit(bits, numbits - curbit - 1) << bitpos);
}
memcpy(bits, tmp, numbytes);
}
//由比特位长度得到字节数。除以8取整,如果还有余数说明要再加一个字节
static unsigned long numbytes_from_numbits(unsigned long numbits)
{ return numbits / 8 + (numbits % 8 ? 1 : 0); }
/* 取出码字 bits 中的第 i 位
第 i 位在第 i/8 字节的第 i%8 位,把这一位移到字节最低位处,和 0000 0001 做与操作,从而只留下这一位,返回*/
static unsigned char get_bit(unsigned char* bits, unsigned long i)
{ return (bits[i / 8] >> i % 8) & 1; } 遍历码树时,先一直向下访问到叶节点中的左子节点,再回到根,再访问叶节点中的右子节点,pSE 的下标就是待编码的信源符号。
码字由数组 bits 存储,数组的一个元素有 8 位(一个字节),因此定义了 cur_bit 和 cur_byte 两个变量,用于标识当前的一位码字在 bits 中的字节位置和字节里的位位置。默认情况下码字数组 bits 全为 0,需要置 1 的情况就和 1 进行或操作把某些比特位置 1。
(5)写入码表,对文件进行编码
static int write_code_table(FILE* out, SymbolEncoder *se, unsigned int symbol_count) //写入码表的函数
{
unsigned long i, count = 0;
//还是要先统计下真实的码字种类,不一定256种都有
for(i = 0; i < MAX_SYMBOLS; ++i)
if((*se)[i]) ++count;
//把字节种类数和字节总数变成大端保存的形式,写入文件中
i = htonl(count);
if(fwrite(&i, sizeof(i), 1, out) != 1) return 1;
symbol_count = htonl(symbol_count);
if(fwrite(&symbol_count, sizeof(symbol_count), 1, out) != 1) return 1;
//然后开始写入码表
for(i = 0; i < MAX_SYMBOLS; ++i)
{
huffman_code *p = (*se)[i];
if(p)
{
fputc((unsigned char)i, out); //码表中有三种数据,先写入字节符号
fputc(p->numbits, out); //再写入码长
//最后得到字节数,写入码字
unsigned int numbytes = numbytes_from_numbits(p->numbits);
if(fwrite(p->bits, 1, numbytes, out) != numbytes) return 1;
}
}
return 0;
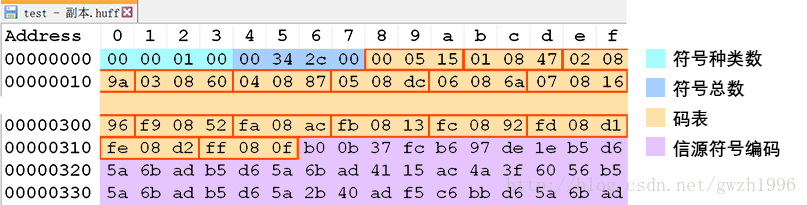
} 在文件中写入字节种类数和字节数时,系统按照小端方式写入,比如 256(100H) 写入后变为 00 01 00 00。为了在文件中能从左到右直接读出真实数据(图 3),这里先把它们变成了大端方式保存再写入文件,在解码时还要做一次转换。经过上述处理后,编码后的文件结构如图 3 所示
static int do_file_encode(FILE* in, FILE* out, SymbolEncoder *se) //对文件符号进行编码的函数
{
unsigned char curbyte = 0;
unsigned char curbit = 0;
int c;
while((c = fgetc(in)) != EOF)
{
//逐字节读取待编码的文件,要找到当前符号(字节)uc对应的码字code,只需要把uc作为码字数组se的下标即可
unsigned char uc = (unsigned char)c;
huffman_code *code = (*se)[uc];
unsigned long i;
for(i = 0; i < code->numbits; ++i)
{
//把码字中的一个比特位放到编码字节的相应位置
curbyte |= get_bit(code->bits, i) << curbit;
//每次写入一个字节
if(++curbit == 8){
fputc(curbyte, out);
curbyte = 0; curbit = 0;
}
}
}
//处理一下最后一个字节的编码不足一字节的情况
if(curbit > 0) fputc(curbyte, out);
return 0;
}对文件进行编码时,一个字节一个字节地读文件,把字节作为信源符号,查找码字数组得到码字。写文件也是一个字节一个字节写,有时候一些码字可能不足一个字节或超过一个字节(8位码字),那么就等到下一个符号的编码,直到凑足一个字节的长度再写入文件。因此编码后的数据中一个字节可能包含有原来文件的多个符号(字节),从而达到了数据压缩的目的。
2. Huffman解码流程
(1)读取码表
static huffman_node* read_code_table(FILE* in, unsigned int *pDataBytes)
{
huffman_node *root = new_nonleaf_node(0, NULL, NULL);
unsigned int count;
//读文件和写文件一样,按照小端方式读
if(fread(&count, sizeof(count), 1, in) != 1{
free_huffman_tree(root); return NULL;
}
//所以按照大端方式存放的数据count,再转换一次就得到了正确结果
count = ntohl(count);
//原文件的总字节数pDataBytes同理
if(fread(pDataBytes, sizeof(*pDataBytes), 1, in) != 1){
free_huffman_tree(root); return NULL;
}
*pDataBytes = ntohl(*pDataBytes);
//————————————————————————————————————————————————————————
while(count-- > 0) //读完这些后,文件指针指向了码表开头,依次读取码表中的每一项,每一项由符号,码长,码字三种数据组成
{
int c;
unsigned int curbit;
unsigned char symbol, numbits, numbytes;
unsigned char *bytes;
huffman_node *p = root;
if((c = fgetc(in)) == EOF) //一次读一个字节,第一个字节是信源符号symbol
{
free_huffman_tree(root); return NULL;
}
symbol = (unsigned char)c;
if((c = fgetc(in)) == EOF) //第二个字节是码长数据numbits
{
free_huffman_tree(root); return NULL;
}
numbits = (unsigned char)c;
//计算出这样一个码长需要多少个字节(numbytes个)保存,开辟与字节数对应的空间
numbytes = (unsigned char)numbytes_from_numbits(numbits);
bytes = (unsigned char*)malloc(numbytes);
if(fread(bytes, 1, numbytes, in) != numbytes) //然后读取numbytes个字节得到码字bytes
{
free(bytes); free_huffman_tree(root); return NULL;
}
//————————————————————————————————————————————————————————
for(curbit = 0; curbit < numbits; ++curbit) //读完码表一项三种数据后,开始由码字建立Huffman树
{
if(get_bit(bytes, curbit)) //如果码字中的当前位为1
{
if(p->one == NULL) //那么应该建立一个右子节点(如果没有的话)
{
//如果读到了最后一位,那么新建一个叶节点,否则建立一个内部节点
p->one = curbit == (unsigned char)(numbits - 1)
? new_leaf_node(symbol)
: new_nonleaf_node(0, NULL, NULL);
p->one->parent = p; //设置好新建节点的父节点
}
p = p->one; //不管右子节点是不是新建的,都要把这个节点当成父节点,以便建立它后续的子节点
}
else //如果码字中的当前位为0
{
if(p->zero == NULL) //那么应该建立一个左子节点(如果没有的话)
{
//同理,选择节点类型并确定节点之间的关系
p->zero = curbit == (unsigned char)(numbits - 1)
? new_leaf_node(symbol)
: new_nonleaf_node(0, NULL, NULL);
p->zero->parent = p;
}
p = p->zero;
}
}
free(bytes);
}
return root; //和编码一样,只要有最上面的根节点就能遍历整棵树
}
(2)根据码树进行解码
int huffman_decode_file(FILE *in, FILE *out) //Huffman解码函数
{
huffman_node *root, *p; int c;
unsigned int data_count;
root = read_code_table(in, &data_count); //打开文件后首先读入码表,建立Huffman树,并且获取原文件的字节数
if(!root) return 1;
p = root;
while(data_count > 0 && (c = fgetc(in)) != EOF) //准备好码树之后,一次读一个字节进行解码
{
unsigned char byte = (unsigned char)c;
unsigned char mask = 1;
//mask负责提取字节中的每一位,提取完之后向左移动一位来提取下一位。因此移动8位之后变成0,循环退出,读下一个字节
while(data_count > 0 && mask)
{
//如果当前字节为0,就转到左子树,否则转到右子树
p = byte & mask ? p->one : p->zero;
mask <<= 1; //准备读下一个字节
if(p->isLeaf) //如果走到了叶节点
{
fputc(p->symbol, out); //就输出叶节点中存储的符号
p = root; //然后转到根节点,再从头读下一个码字
--data_count; //而且剩下没解码的符号数-1
}
}
}
free_huffman_tree(root);
return 0;
}3. 对内存数据的Huffman编解码
(建设中。。。)
三、实验结果与总结
实验中需要添加代码将编码结果列表输出,输出列表主要包含四项:信源符号,符号频率(或出现次数),符号的码字长度,码字。信源符号可以通过数组下标得到,信源符号出现的次数在节点数据类型中,码字和字长在码字数据类型中。为了方便,重新定义了如下的结构,一起保存这三项数据:
typedef struct huffman_stat_tag //信源符号的统计数据类型
{
unsigned long numbits; //码字长度
unsigned char *bits; //码字
double freq; //信源符号出现的频率
}huffman_stat;
typedef huffman_stat* SymbolStatices[MAX_SYMBOLS];在命令行参数中需要再多加一个参数来指定输出的文本文件,添加命令行参数方法在读入编码文件部分分析过。
void getStatFreq(SymbolStatices* stat, SymbolFrequencies* sf, unsigned int symbol_count) //由信源符号数组得到出现频率的函数
{
unsigned int i;
for (i = 0; i < MAX_SYMBOLS; i++)
(*stat)[i] = (huffman_stat*)malloc(sizeof(huffman_stat)); //把统计数组信源符号的每个位置分配一块空间
for (i = 0; i < MAX_SYMBOLS; i++)
{
if ((*sf)[i]) //如果符号数组当前元素不为空
{
unsigned int j = (*sf)[i]->symbol; //那么得到当前元素保存的信源符号
(*stat)[j]->freq = (double)(*sf)[i]->count / symbol_count; //把符号作为下标,对 freq 赋值
}
}
for (i = 0; i < MAX_SYMBOLS; i++)
{
if (!(*sf)[i]) //找到那些信源符号为空的数组
(*stat)[i]->freq = 0; //信源符号频率为0
}
}
//————————————————————————————————————————————————————————
void getStatCode(SymbolStatices* stat, SymbolEncoder *se) //由码字数组得到统计数组中其它两项信息的函数
{
unsigned int i;
for (i = 0; i < MAX_SYMBOLS; i++)
{
//之前已经分配过存储空间了,如果当前符号存在,得到符号的码长和码字
if ((*se)[i])
{
(*stat)[i]->numbits = (*se)[i]->numbits;
(*stat)[i]->bits = (*se)[i]->bits;
}
}
}
//————————————————————————————————————————————————————————
void output_statistics(FILE* table, SymbolStatices stat) //将码字列表写入文件的函数
{
unsigned long i,j, count = 0;
for (i = 0; i < MAX_SYMBOLS; ++i)
if (stat[i]) ++count;
fprintf(table, "Symbol\t Frequency\t Length\t Code\n"); //表头每一项的说明
for (i = 0; i < count; i++)
{
fprintf(table, "%d\t", i); //第一列为信源符号
fprintf(table, "%f\t", stat[i]->freq); //第二列为符号的出现频率
//如果信源符号频率为零,码字为空指针,因此输出一个 0 作为码字长度然后输出下一个符号
if (stat[i]->freq == 0)
{
fprintf(table,"0\n");
continue;
}
fprintf(table, "%d\t", stat[i]->numbits); //第三列为码字长度
for (j = 0; j < numbytes_from_numbits(stat[i]->numbits); j++)
{
fprintf(table, "%x", stat[i]->bits[j]); //第四列为用十六进制表示的码字,可以与编码后文件中的码表对应
}
fprintf(table, "\t");
for (j = 0; j < stat[i]->numbits; j++)
{
//还有用二进制方式表示的码字,每次取出码字的一位,输出到文件中
unsigned char c = get_bit(stat[i]->bits, j);
fprintf(table, "%d", c);
}
fprintf(table, "\n");
}
} 统计数组中符号频率的赋值 getStatFreq 放在编码函数 huffman_encode_file 中 get_symbol_frequencies 后面,码长和码字的赋值 getStatCode 放在 calculate_huffman_codes 后面,最后使用 output_statistics 输出要求的编码结果文件即可。
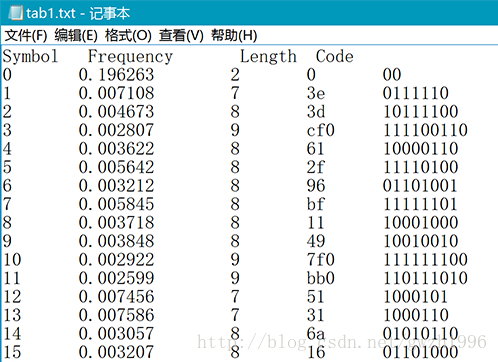
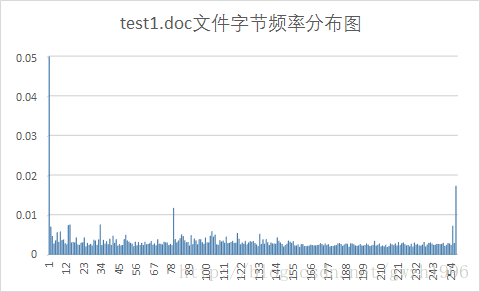
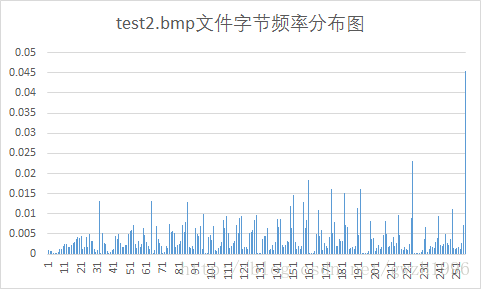
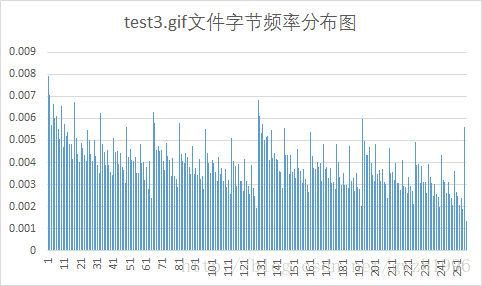
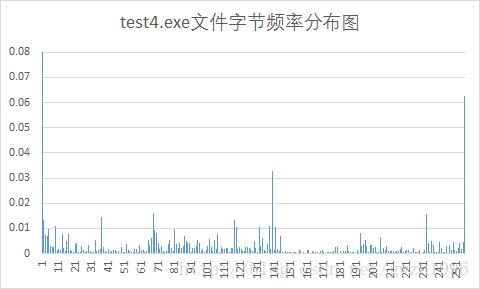
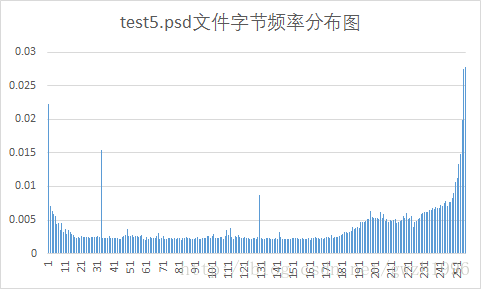
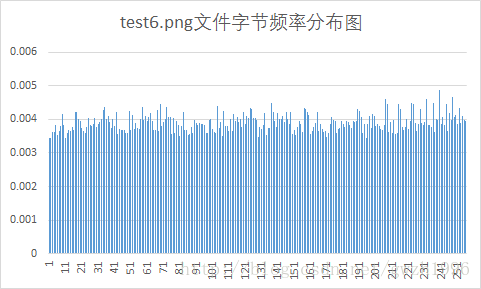
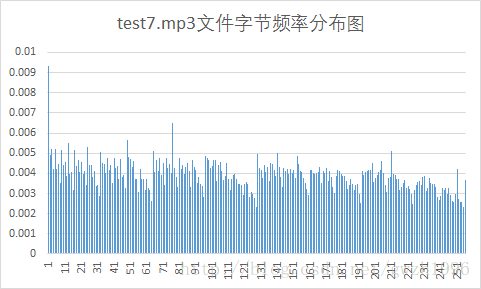
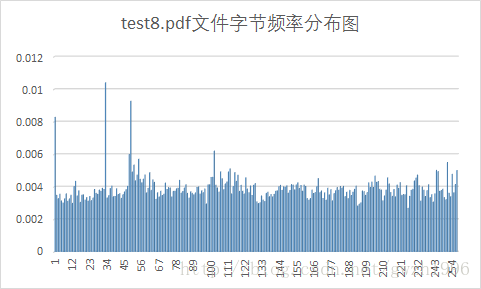
另外,第二列频率值可以计算文件的信源熵,第二列和第三列可以计算平均码长。总共选择了九种不同格式的文件对它们进行压缩,实验用文件如图 5 所示,实验结果如表 1 所示。其中压缩比为原文件大小除以压缩后的文件大小。

| 文件类型 | 平均码长 | 信源熵(bit/sym) | 原文件大小(KB) | 压缩后文件大小(KB) | 压缩比 |
|---|---|---|---|---|---|
| doc | 7.09 | 7.05 | 203 | 181 | 1.122 |
| bmp | 7.39 | 7.36 | 704 | 651 | 1.081 |
| gif | 7.97 | 7.94 | 3443 | 3433 | 1.003 |
| exe | 6.10 | 6.08 | 308 | 206 | 1.495 |
| psd | 7.71 | 7.68 | 1170 | 1129 | 1.036 |
| png | 8.00 | 7.99 | 3644 | 3645 | 0.999 |
| mp3 | 7.99 | 7.98 | 5252 | 5248 | 1.001 |
| 7.99 | 7.97 | 2861 | 2858 | 1.001 | |
| xls | 4.67 | 4.64 | 274 | 161 | 1.702 |
 |  |  |
|---|---|---|
 |  |  |
 |  | 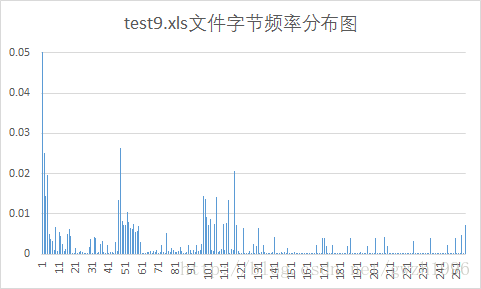 |
Huffman编码对于字节分布不均匀的文件压缩效果好,而对于每个字节出现概率接近等概的文件就不能按照大概率短码,小概率长码的原则进行编码,最终使得文件基本没有压缩,特别是第 6 个测试的 png 文件,编码结果显示每个符号的码长都是 8 位,再加上存储的码表使得文件反而比压缩前更大了。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









