







原创文章,同步首发自作者个人博客。转载请务必在文章开头处注明出处 http://www.jasongj.com/ml/classification/。
摘要
本文详述了如何通过数据预览,探索式数据分析,缺失数据填补,删除关联特征以及派生新特征等方法,在Kaggle的Titanic幸存预测这一分类问题竞赛中获得前2%排名的具体方法。
竞赛内容介绍
Titanic幸存预测是Kaggle上参赛人数最多的竞赛之一。它要求参赛选手通过训练数据集分析出什么类型的人更可能幸存,并预测出测试数据集中的所有乘客是否生还。
该项目是一个二元分类问题
如何取得排名前2%的成绩
加载数据
在加载数据之前,先通过如下代码加载之后会用到的所有R库
library(readr) # File read / write
library(ggplot2) # Data visualization
library(ggthemes) # Data visualization
library(scales) # Data visualization
library(plyr)
library(stringr) # String manipulation
library(InformationValue) # IV / WOE calculation
library(MLmetrics) # Mache learning metrics.e.g. Recall, Precision, Accuracy, AUC
library(rpart) # Decision tree utils
library(randomForest) # Random Forest
library(dplyr) # Data manipulation
library(e1071) # SVM
library(Amelia) # Missing value utils
library(party) # Conditional inference trees
library(gbm) # AdaBoost
library(class) # KNN
library(scales)通过如下代码将训练数据和测试数据分别加载到名为train和test的data.frame中
train <- read_csv("train.csv")
test <- read_csv("test.csv")由于之后需要对训练数据和测试数据做相同的转换,为避免重复操作和出现不一至的情况,更为了避免可能碰到的Categorical类型新level的问题,这里建议将训练数据和测试数据合并,统一操作。
data <- bind_rows(train, test)
train.row <- 1:nrow(train)
test.row <- (1 + nrow(train)):(nrow(train) + nrow(test))数据预览
先观察数据
str(data)## Classes 'tbl_df', 'tbl' and 'data.frame': 1309 obs. of 12 variables:
## $ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
## $ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
## $ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
## $ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ...
## $ Sex : chr "male" "female" "female" "female" ...
## $ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
## $ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
## $ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
## $ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ...
## $ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
## $ Cabin : chr NA "C85" NA "C123" ...
## $ Embarked : chr "S" "C" "S" "S" ...
从上可见,数据集包含12个变量,1309条数据,其中891条为训练数据,418条为测试数据
- PassengerId 整型变量,标识乘客的ID,递增变量,对预测无帮助
- Survived 整型变量,标识该乘客是否幸存。0表示遇难,1表示幸存。将其转换为factor变量比较方便处理
- Pclass 整型变量,标识乘客的社会-经济状态,1代表Upper,2代表Middle,3代表Lower
- Name 字符型变量,除包含姓和名以外,还包含Mr. Mrs. Dr.这样的具有西方文化特点的信息
- Sex 字符型变量,标识乘客性别,适合转换为factor类型变量
- Age 整型变量,标识乘客年龄,有缺失值
- SibSp 整型变量,代表兄弟姐妹及配偶的个数。其中Sib代表Sibling也即兄弟姐妹,Sp代表Spouse也即配偶
- Parch 整型变量,代表父母或子女的个数。其中Par代表Parent也即父母,Ch代表Child也即子女
- Ticket 字符型变量,代表乘客的船票号
- Fare 数值型,代表乘客的船票价
- Cabin 字符型,代表乘客所在的舱位,有缺失值
- Embarked 字符型,代表乘客登船口岸,适合转换为factor型变量
探索式数据分析
乘客社会等级越高,幸存率越高
对于第一个变量Pclass,先将其转换为factor类型变量。
data$Survived <- factor(data$Survived)可通过如下方式统计出每个Pclass幸存和遇难人数,如下
ggplot(data = data[1:nrow(train),], mapping = aes(x = Pclass, y = ..count.., fill=Survived)) +
geom_bar(stat = "count", position='dodge') +
xlab('Pclass') +
ylab('Count') +
ggtitle('How Pclass impact survivor') +
scale_fill_manual(values=c("#FF0000", "#00FF00")) +
geom_text(stat = "count", aes(label = ..count..), position=position_dodge(width=1), , vjust=-0.5) +
theme(plot.title = element_text(hjust = 0.5), legend.position="bottom")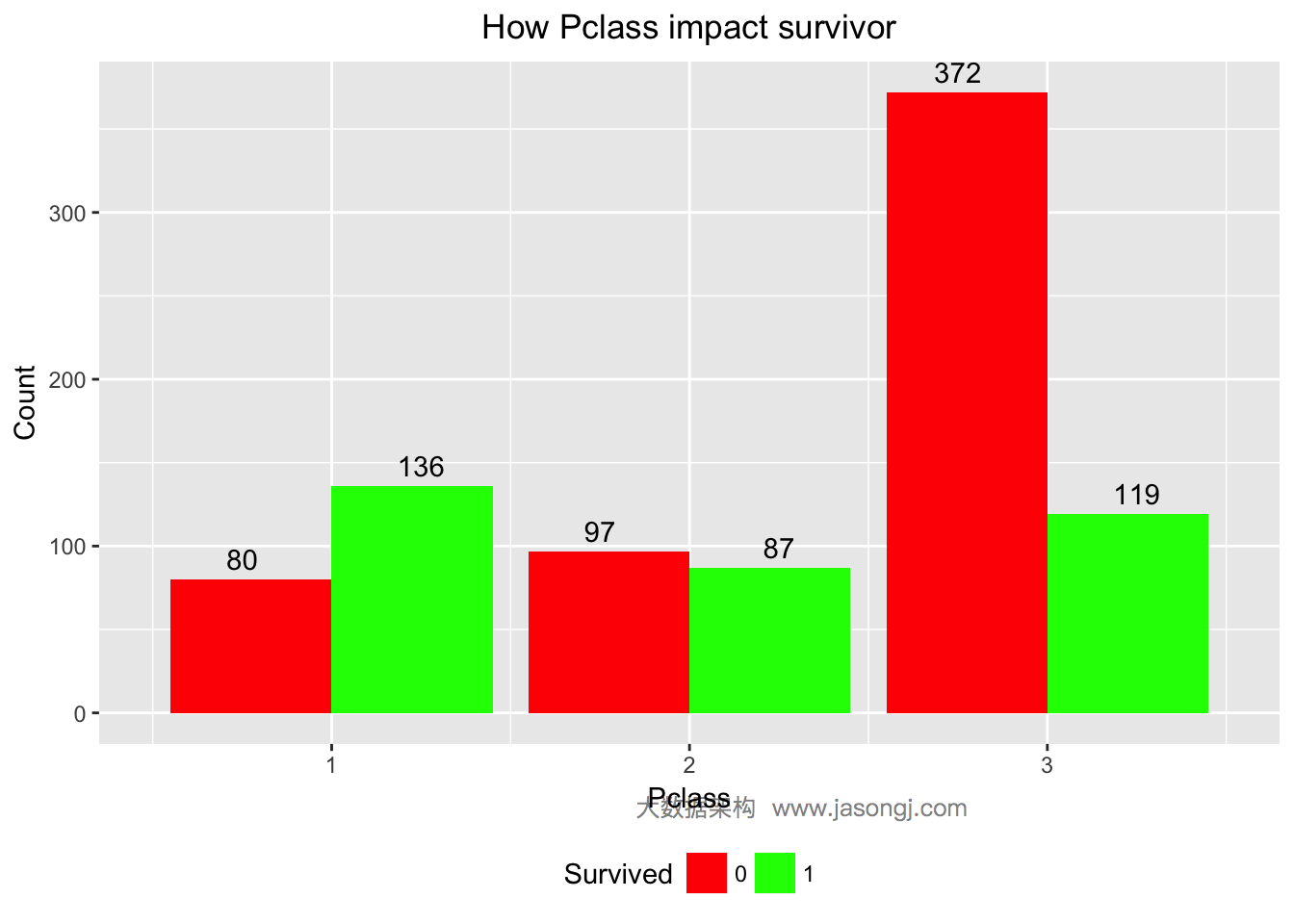
从上图可见,Pclass=1的乘客大部分幸存,Pclass=2的乘客接近一半幸存,而Pclass=3的乘客只有不到25%幸存。
为了更为定量的计算Pclass的预测价值,可以算出Pclass的WOE和IV如下。从结果可以看出,Pclass的IV为0.5,且“Highly Predictive”。由此可以暂时将Pclass作为预测模型的特征变量之一。
WOETable(X=factor(data$Pclass[1:nrow(train)]), Y=data$Survived[1:nrow(train)])## CAT GOODS BADS TOTAL PCT_G PCT_B WOE IV
## 1 1 136 80 216 0.3976608 0.1457195 1.0039160 0.25292792
## 2 2 87 97 184 0.2543860 0.1766849 0.3644848 0.02832087
## 3 3 119 372 491 0.3479532 0.6775956 -0.6664827 0.21970095
IV(X=factor(data$Pclass[1:nrow(train)]), Y=data$Survived[1:nrow(train)])## [1] 0.5009497
## attr(,"howgood")
## [1] "Highly Predictive"
不同Title的乘客幸存率不同
乘客姓名重复度太低,不适合直接使用。而姓名中包含Mr. Mrs. Dr.等具有文化特征的信息,可将之抽取出来。
本文使用如下方式从姓名中抽取乘客的Title
data$Title <- sapply(data$Name, FUN=function(x) {strsplit(x, split='[,.]')[[1]][2]})
data$Title <- sub(' ', '', data$Title)
data$Title[data$Title %in% c('Mme', 'Mlle')] <- 'Mlle'
data$Title[data$Title %in% c('Capt', 'Don', 'Major', 'Sir')] <- 'Sir'
data$Title[data$Title %in% c('Dona',  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4988
4988











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









