







在处理海量数据的时候,我们发现有些数据不是关系型的。而是NO-SQL型数据。这就不使使用传统的数据库来处理了。我这里介绍一种非关系型数据库MongoDB数据库,它是由C++写的方案。特点是稳定,高效,而且处理海量数据时效果显著。
首先要去下载这个MongoDB.下载地地址为:http://www.mongodb.org/downloads
由于我是用JAVA去访问这个MongoDB的,所以要下载MongoDB驱动。下载地址为:
http://github.com/mongodb/mongo-java-driver/downloads
当然我们还要查看一些开发文档:
http://www.mongodb.org/display/DOCS/MongoDB
http://www.mongodb.org/display/DOCS/Tutorial
首先要配置好MongoDB以及工作目录。
默认情况下,在将这两个都放置在同一个盘符下面,比如我这里,我统一都放在D盘目录下面。
然后启动 MongoDB,在普通启动下(即单结点),有三种方式:
(1) 默认启动 bin/mongod
(2) 指定端口和数据目录 bin/mongod –dbpath=/var/data/ –port=556600
(3) 带有鉴权的启动 bin/mongod –auth
如果是分布式的情况下:
您需要启动的至少两个MongoDB文档数据库。
服务器1:192.168.1.10/Linux1
服务器2:192.168.1.11 /Linux2
启动服务器1:
bin/mongod –slave –source=192.168.1.11:556600 –dbpath=/var/db/ –port=556611 –slavedelay 10 &
启动服务器2:
bin/mongod –slave –source=192.168.1.10:556601 –dbpath=/var/db/ –port=556610 –slavedelay 10 &
PS:这里的意思是启动该服务器1,并且把服务器2作为主服务器,每10秒与主服务器2同步一次。启动服务器2的意思是,把服务器1作为主服务器,每10秒与服务器1同步一次。这样服务器1与服务器2就构成了同步了。
下面我主要讲解,单节点方式。
在bin目录下面,输入: mongod
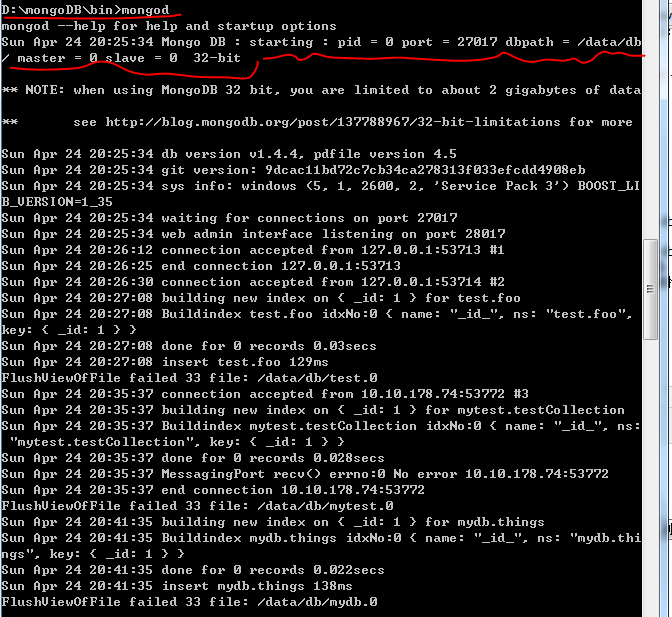
然后再输入: mongo.exe
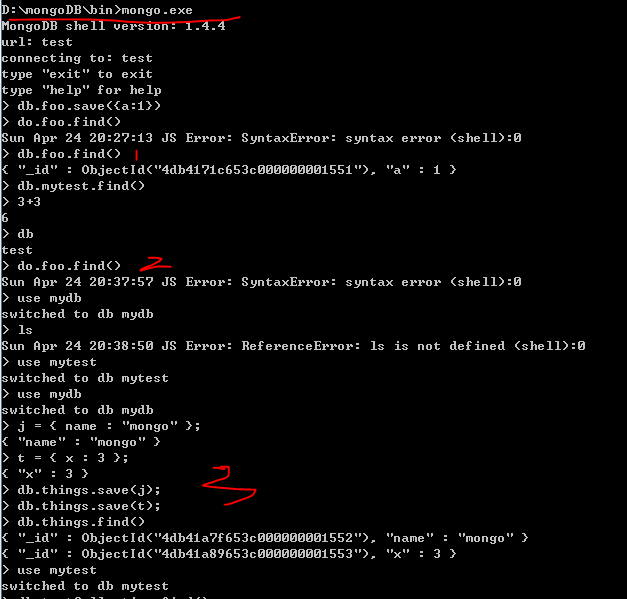
这样就可以去在shell中操作MongoDB了。
在实际项目开发过程中我们不可能通过Shell来操作MongoDB,这里我使用JAVA语言去操作。
下面是我例子的pakage层次:
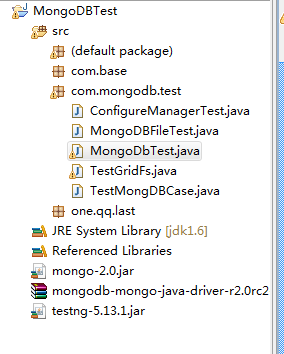
我这里下载了mongo-java包以及其源码。
下面以MongoDbTest.java为例,讲解,代码如下所示:
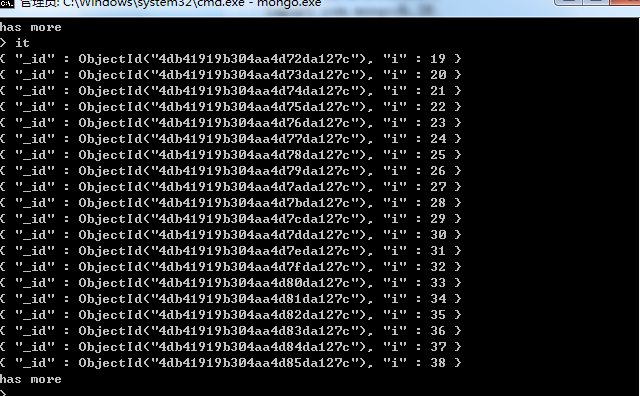
运行后,在控制台查询,如下所示:
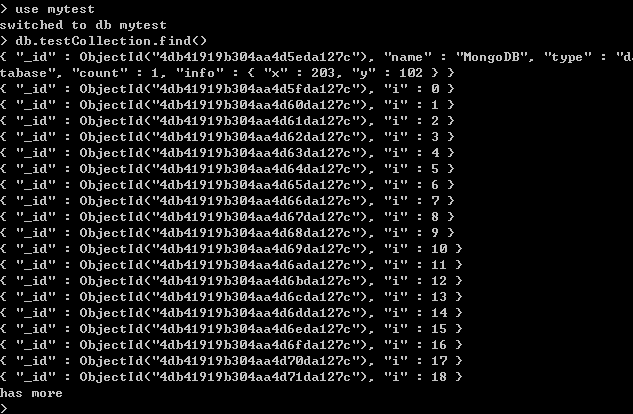
由于一次不能显示100条,这里只18条记录。不过使用it,可以显示下面的数据。
下面这段代码是实现将一个zip文件存储在MongoDB端,然后还可以读取出来。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









