









针对上次考试系统中出现的问题,数据的访问量过大,和数据的动态交互过多的时候,造成服务器的内存和Cpu的使用率都是高居不下的问题。
实例图如下
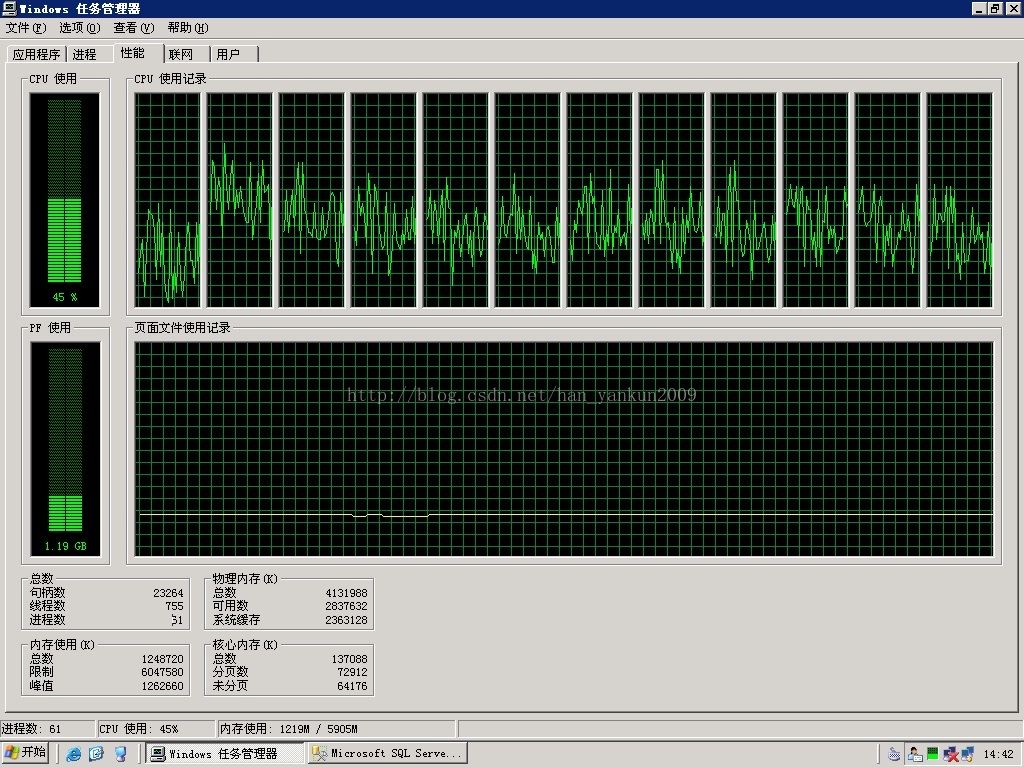
根据老师的启发,找到了基本的原因,主要原因还是在于一张表的数据过多,逐渐的积累,造成后续的访问中,冗余数据过多,这样查询的时候就消耗过多,造成登录或查询的时间就延迟过长。或则就查询超时了。
处于这样的考虑,想到了对于数据量的数据库优化,当然,优化不仅于此,这个优化只是对数据的优化,还有前台web服务的优化等。这里仅对于sql的查询进行优化。
在大数据量之下,部分数据库由于信息量很大,查询频繁。可以采取把一些表或者一些表中的部分记录分开存储在不同的数据文件里的方式进行优化。还可已经经常访问的表中的信息暂存在一个动态数组中,保存在内存中,这样就避免经常访问数据库的消耗了
首先看下整体的优化方法在逐个介绍
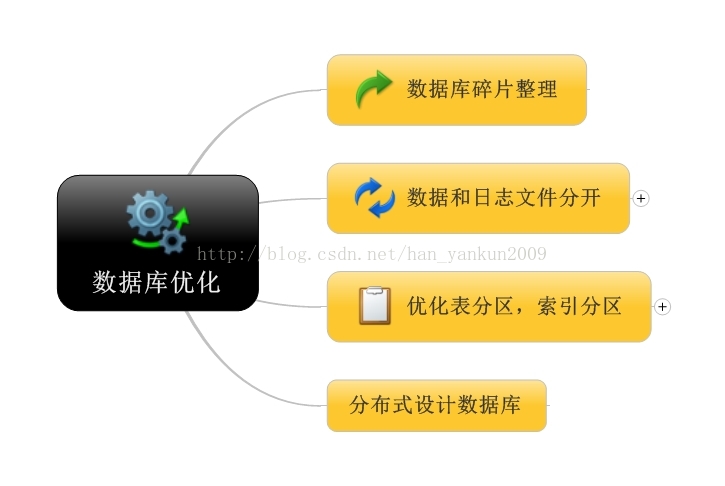
1设计适当的数据类型
数据类型是数据库中必须的类型,而且每种数据类型又是有不同的字长的,设置过大的数据类型,暂用过多的字段,少了又会溢出,或是不同的数据进行转换的时候又会造成内存的过多的使用,cpu使用就会缓慢,所以保证数据类型的准确性是必不可少的一项
2数据和日志文件分开放在不同磁盘上
数据文件和日志文件的操作会产生大量的I/O。在可能的条件下,日志文件应该存放在一个与数据和索引所在的数据文件不同的硬盘上以分散I/O,同时还有利于数据库的灾难恢复。
3优化表分区,索引分区
为何要表分区?
当一个表的数据量太大的时候,我们最想做的一件事是什么?将这个表一分为二或者更多分,但是表还是这个表,只是将其内容存储分开,这样读取就快了N倍了
原理:表数据是无法放在文件中的,但是文件组可以放在文件中,表可以放在文件组中,这样就间接实现了表数据存放在不同的文件中。能分区存储的还有:表、索引和大型对象数据 。
SQL SERVER 2005中,引入了表分区的概念, 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区,当一个表里的数据很多时,可以将其分拆到多个的表里,因为要扫描的数据变得更少 ,查询可以更快地运行,这样操作大大提高了性能,表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表
什么时候使用分区表:
A 表的大小超过2GB
B 表中包含历史数据,新的数据北增加到新的分区表中
表分区的优缺点 :
优点:
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
4分布式数据库设计
分布式数据库系统是在集中式数据库系统的基础上发展起来的,理解起来也很简单,就是将整体的数据库分开,分布到各个地方,就其本质而言,分布式数据库系统分为两种:
A .数据在逻辑上是统一的,而在物理上却是分散的,一个分布式数据库在逻辑上是一个统一的整体,在物理上则是分别存储在不同的物理节点上,我们通常说的分布式数据库都是这种
B.逻辑是分布的,物理上也是分布的,这种也成联邦式分布数据库,由于组成联邦的各个子数据库系统是相对“自治”的,这种系统可以容纳多种不同用途的、差异较大的数据库,比较适宜于大范围内数据库的集成。
以上只是几点对于大数据量的数据库优化问题,并不涉数据库表的优化问题。
- 改善查询性能,对分区对象的查询可以仅搜索自己关系的分区,提高检索数据
- 增强可用性,如果表的某个分区出现故障,表在其他分区的数据仍可用
- 维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
- 均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。














 2097
2097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









