







 本文介绍了如何使用爬虫抓取知乎专栏https://zhuanlan.zhihu.com/Entertainmentlaw的信息,包括专栏名称、作者和关注人数。通过分析请求URL和消息头,实现了对文章信息的抓取,揭示了知乎加载文章的limit和offset参数规律。
本文介绍了如何使用爬虫抓取知乎专栏https://zhuanlan.zhihu.com/Entertainmentlaw的信息,包括专栏名称、作者和关注人数。通过分析请求URL和消息头,实现了对文章信息的抓取,揭示了知乎加载文章的limit和offset参数规律。
接着昨天的模拟登陆,今天来爬取一下专栏信息
我们将对专栏https://zhuanlan.zhihu.com/Entertainmentlaw进行抓取
首先还是进行抓包分析,可以发现这里有我们想要的专栏的名称,作者,关注人数等信息
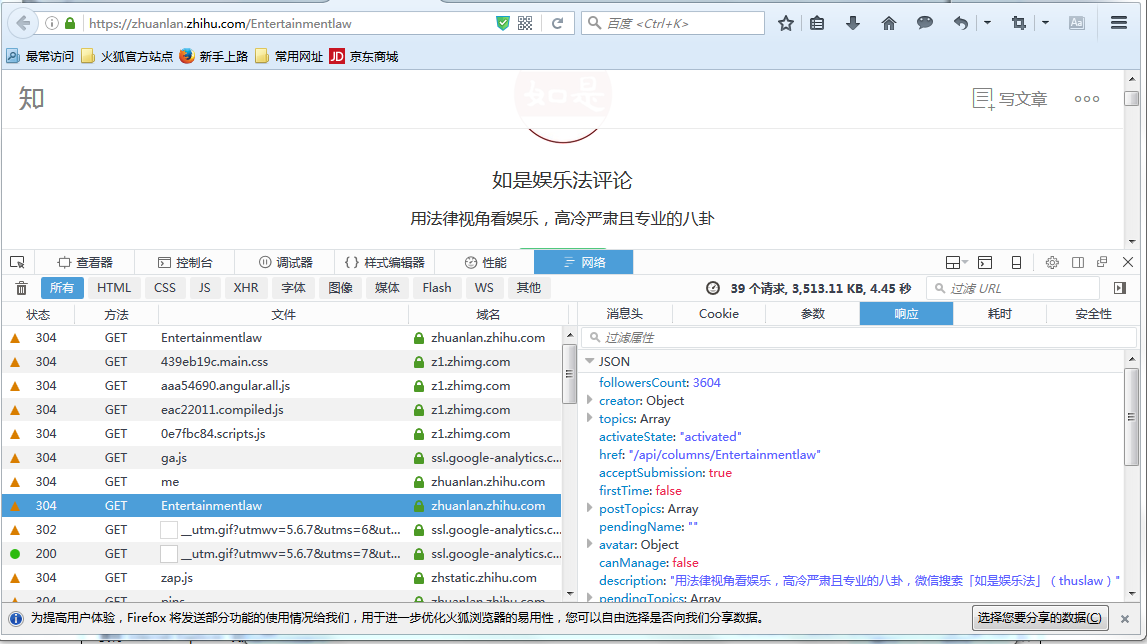
然后我们看一下消息头,看一下请求的URL和请求头
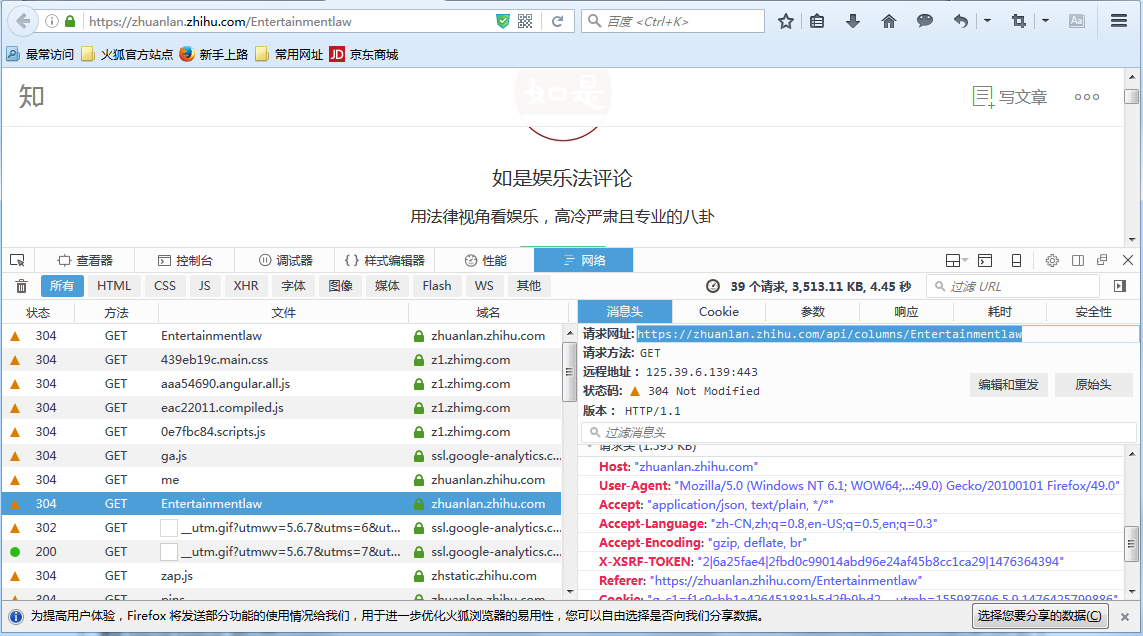
然后就可以编写代码了
# -*- coding:utf-8 -*-
__author__="weikairen"
import requests
from bs4 import BeautifulSoup
import time
BASE_URL='https://www.zhihu.com/'
LOGIN_URL=BASE_URL+'login/phone_num'
CAPTCHA_URL=BASE_URL+'captcha.gif?r='+str(int(time.time())*1000)+'&type=login'
BLOGS_BASE_URL='https://zhuanlan.zhihu.com/Entertainmentlaw'
BLOGS_API_URL='https://zhuanlan.zhihu.com/api/columns/Entertainmentlaw'
session = requests.session() #session创建为全局变量是为了能在不同的函数中使用一个相同的session
#在登录过后 session会保存服务器返回的cookie,爬取专栏信息的时候用这个session,服务器就会认为你已经登录,就不会拒绝你的请求了
def login():
headers={
'host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0',
'referer':"https://www.zhihu.com/",
'X - Requested - With': "XMLHttpRequest"
} #构造请求头, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









