









序言
- Hadoop 2.7 集群已搭建完毕. 参考“CentOS7 从零开始搭建 Hadoop2.7集群‘’。(node 192.168.169.131, node1 192.168.169.133, node2 192.168.169.132, node3 192.168.169.134)
- 本地下载 scala-2.11.8.tgz:
- 本地下载 spark-2.0.0-bin-hadoop2.7.tgz
上传文件到各服务器。
上传文件
pscp.exe -pw 12345678 scala-2.11.8.tgz root@192.168.169.131:/usr/local pscp.exe -pw 12345678 spark-2.0.0-bin-hadoop2.7.tgz root@192.168.169.131:/usr/local
安装配置Scala
设置临时变量
scalaFolder='/usr/lib/scala-2.11.8'解压文件夹
tar -zxvf /usr/local/scala-2.11.8.tgz mv /usr/lib/scala-2.11.8 ${scalaFolder}设置环境变量
echo export SCALA_HOME=${scalaFolder} >> /etc/profile echo export 'PATH=$PATH:$SCALA_HOME/bin' >> /etc/profile
安装配置Spark
设置临时变量
sparkFolder='/home/hadoop/spark2.0'解压文件并修改文件属性
tar -zxvf /usr/local/spark-2.0.0-bin-hadoop2.7.tgz mv /usr/local/spark-2.0.0-bin-hadoop2.7 ${sparkFolder} chown -R hadoop:hadoop ${sparkFolder} chmod -R g=rwx ${sparkFolder}设置环境变量
echo export SPARK_HOME=${sparkFolder} >> /etc/profile source /etc/profile
配置集群
创建文件 /home/hadoop/spark2.0/conf/slaves
node1 node2 node3创建文件/home/hadoop/spark2.0/conf/spark-env.sh
#!/usr/bin/env bash export SCALA_HOME=/usr/lib/scala-2.11.8
启动集群
启动hadoop 集群
$HADOOP_HOME/sbin/start-all.sh启动spark集群
$SPARK_HOME/sbin/start-all.sh验证集群状态
192.168.169.131:8080 #spark
192.168.169.131:50070 #hdfs
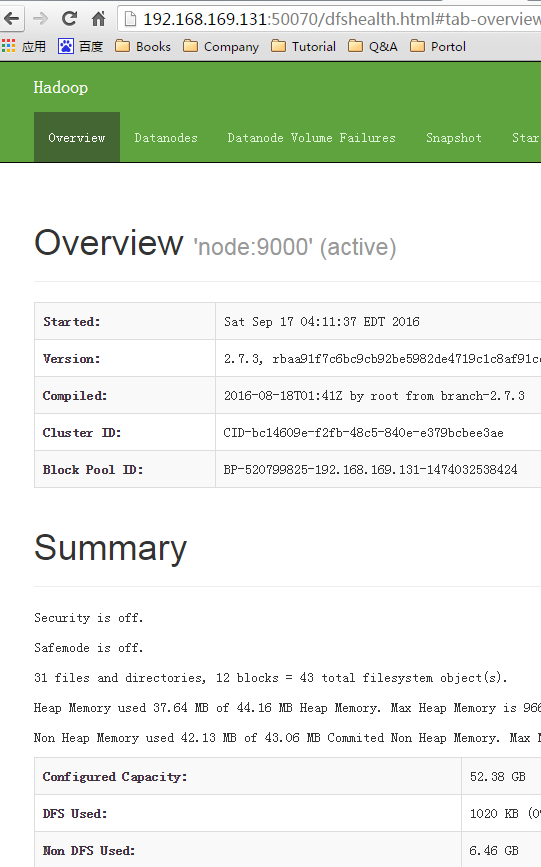
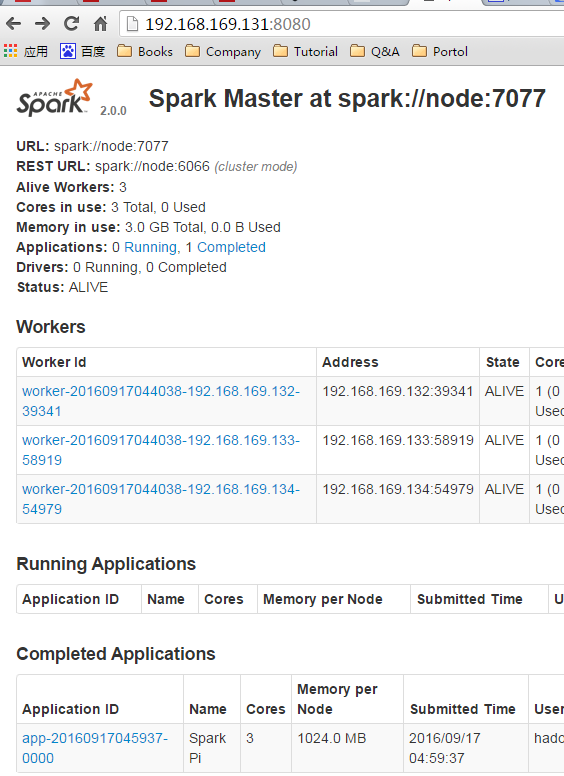
测试Spark集群
运行测试例子
MASTER=spark://node:7077 ./bin/run-example SparkPi
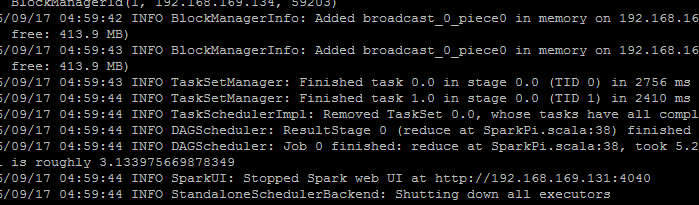














 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









