







这里需要说明下,内核本身执行时需要对数据进行预处理才能放到GPU上运算。这个例子的使用上面,采用的规则是:
数据的个数必须是64*256=16384的倍数。
我们先以单倍,即16384个数据为例来分析该例子。
先看第一个调用的内核函数scanArrayKerneldim2思想解析。其并行结构的划分可以简单用下图表示:
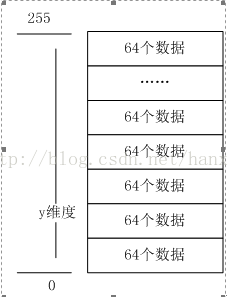
也就是说利用二维内核来计算,全局的内核分配为根据numElem/256划分x轴的block个数。当然因为我们分析的是最基本的单倍情况,这里只有一个组。而y轴的维度坐标情况为从0~255。那么这个内核用来计算什么呢?首先看下数据通过内核读取时的排序情况:
在x为0时,y从下到上的索引为0~255;x为1时,y从下到上的索引为256~511……
在内核scanArrayKerneldim2处理完成后,生成两个结果内存对象:
1. sumBufferin对象用于存储每行的统计和;即对入桶时索引相同的二中的结果以64个为一组进行加和。因为以单倍方式,所以sumBufferin得到256个加和结果;
2. scanedHistogramBinsBuf以纵向y轴方向排序,x=0时,结果为0,x=1时记录前面的组的结果即x=0时的统计结果;同理x=2时记录(x=0)+(x=1)的统计结果。
还是有点乱,没关系,我们上图说话:

这个就是sumBufferin的加和计算模型了。是不是清晰些了?那么还有一个scanedHistogramBinsBuf究竟是怎么回事呢?下面是一个超级简图,因为画起来比较困难,这里简化了很多,B[n],0<=n<=63是分块后的索引,B[0]表示histogram中0号块的统计结果,其他依次类推。

也就是说除了索引为0,每个都是前面块的结果的累加和。
内核函数为:
__kernel void ScanArraysdim2(__global uint *output,
__global uint *input,
__local uint* block, //64*1
const uint block_size,//64
const uint stride, //64
__global uint* sumBuffer)
{
int tidx = get_local_id(0);
int tidy = get_local_id(1);
int gidx = get_global_id(0);
int gidy = get_global_id(1);
int bidx = get_group_id(0);
int bidy = get_group_id(1);
int lIndex = tidy * block_size + tidx;
//因为实际是以256个为一组的,以y为偏移量,以x为基准量进行总的position的计算
int gpos = (gidx << RADIX) + gidy;
//以行为单位标记组ID
int groupIndex = bidy * (get_global_size(0)/block_size) + bidx;
/* Cache the computational window in shared memory */
//取出每行的数据
block[tidx] = input[gpos];
barrier(CLK_LOCAL_MEM_FENCE);
uint cache = block[0];
/* build the sum in place up the tree */
//就是缩减树算法
for(int dis = 1; dis < block_size; dis *=2)
{
if(tidx>=dis)
{
cache = block[tidx-dis]+block[tidx];
}
//等待第一次缩减完成
barrier(CLK_LOCAL_MEM_FENCE);
block[tidx] = cache;
//等待本次统计结果完成
barrier(CLK_LOCAL_MEM_FENCE);
}
/* store the value in sum buffer before making it to 0 */
//统计每行的加和结果
sumBuffer[groupIndex] = block[block_size-1];
/*write the results back to global memory */
if(tidx == 0)
{
output[gpos] = 0;
}
else
{
output[gpos] = block[tidx-1];
}
} 这里其中有一个缩减树,可能有些难理解,但是可以通过查资料找到。对核心代码已经做了简略的注释,可以根据图示进行理解。














 3060
3060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









